



All About Adaboost
Last Updated on July 26, 2023 by Editorial Team
Author(s): Akash Dawari
Originally published on Towards AI.
All About Adaboost
The article will explore the idea of Adaboost by answering the following questions:
- What is Adaboost?
- Why are we learning Adaboost?
- How do Adaboost works?
- What are the differences between Random Forest and Adaboost?
- What are the advantages and disadvantages of Adaboost?
- How we can implement Adaboost using python?
What is Adaboost?
Adaboost is a supervised machine learning algorithm. This algorithm can solve both kinds of problem statements that is classification and regression. It comes under the category of boosting ensemble technique. The basic idea of this algorithm is to collect some weak machine learning algorithms and train them in a sequential order where each weak learner passes some kind of helpful information to the next weak learner so that the next weak learner can learn better. This is why it is called Adaptive boosting which is the full form of Adaboost. The last step is to aggregate the outputs of the trained learner using some mathematical function.
I know the above explanation of the working of the Adaboost is not very helpful so don’t worry we will deeply explore the work in this article after some time. The above explanation is to just make us familiar with the concept of the adaboost algorithm.
For better understand of boosting and ensemble technique click the below link
All About Ensemble Techniques
In this article we will try to understand the idea of the ensemble in the context of machine learning by answering the…
pub.towardsai.net
Why are we learning Adaboost?
In past, adaboost is used in very complex problems like image classification. But nowadays, we introduce to deep learning so we don’t use adaboost for all those problem statements. So why the hack we are learning this? The following two arguments will make sense why we are learning adaboost.
- Adaboost convert a high bias low variance model to low bias low variance which helps to build an ideal machine learning model that gives us a very accurate prediction.
- Though adaboost is outdated but modern algorithms like Xgboost and Gradient boost algorithm are all based on adaboost concepts. These modern algorithms are heavily used in different Kaggle computations
How do Adaboost works?
Before we deep dive into the working mechanics of adaboost we have to understand some terminologies.
Prerequisites of an Adaboost:
Weak Learners:
Those machine learning models give very low accuracy. The accuracy range must be from 50% to 60%.
Decision Stump:
They are just a normal decision tree with depth or height equal to one. Adaboost only uses decision stumps as its base estimator.
Pros and Con of decision stumps:
Pros:
- Computational scalability
- Handles missing values
- Robust to outliers
Con’s:
- High Variance
- Inability to extract a linear combination of features.
Up-Sampling:
This is a technique used in adaboost to update the dataset by creating new weights for the rows. The new weights are generated by using the below formula:

The sum of new weights will not be equal to 1 so, we will perform normalization.
Alpha:
Alpha is the weight for the respective decision stump. This decides how much the decision stump will affect the final result. If the model is good then the value of alpha will increase and visa-versa.
Now, we are ready to understand the steps involved in adaboost algorithm.
The above picture of the adaboost algorithm seems very complicated and hard to understand. So, we will decode the above algorithm step by step.
- Add a column to the dataset which contains the weight of every row. The initial weight is calculated by assigning equal weights to all the rows by using the below formula:

2. Train a decision stump on the dataset.
3. Make predictions using the trained decision stump.
4. Calculate alpha for the decision stump by using the below formula.

5. Increase the importance of the miss predicted values rows by using the technique of upsampling and updating the dataset.
6. We will repeat all the steps again on a new decision stump but by using the updated dataset.
7. Now the last step, after running for n estimators we will get
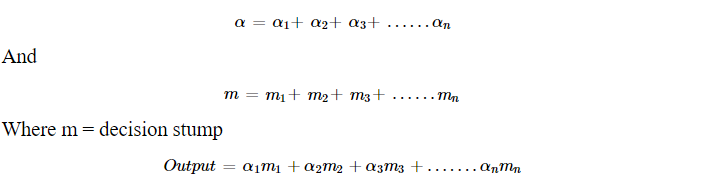
Pass this “output” in any function ranging from 0 to 1
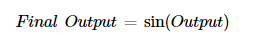
What are the differences between Random Forest and Adaboost?
- The first difference between random forest and adaboost is that random forest comes under the bagging ensemble technique and adaboost comes under boosting ensemble technique. If we elaborate, random forest runs a collection of machine learning models in parallel but adaboost runs a collection of machine learning models in sequence.
- Random Forest uses shallow or moderate depth of decision trees whereas adaboost uses decision stumps.
- Both the algorithms generate a low bias and low variance model but random forest converts low bias high variance models whereas adaboost converts high bias low variance models.
- In random forest, we can assign weights to the models but they will be the same for all whereas in adaboost the weights are assigned accordingly to each model's accuracy and performance.
What are the advantages and disadvantages of Adaboost?
Advantages:
- It is easy to use as we do not have to do many hyperparameters tunning as compared to other algorithms.
- Adaboost increases the accuracy of the weak machine learning models.
- Adaboost has immunity from overfitting of data as it runs each model in a sequence and has a weight associated with them.
Disadvantages:
- Adaboost needs quality data for training as it is very sensitive to noisy data and outliers.
How we can implement Adaboost using python?
We will implement Adaboost from scratch as well as using Scikit-learn. So, let’s get started.
NOTE: Below are the snippets of the whole code so, advise you to check the notebook itself for better understanding. The link is below.
First, we should import the required packages from python.

Now, create dummy data.

The dummy data looks like this.

Now, by referring to the adaboost algorithm. The first step is to add a new weight column.

The second step is to run a decision stump.

Calculate alpha,
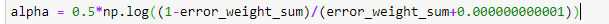
create a new data frame using upsampling.

Repeat these steps for n estimators.

if we check the accuracy of your adaboost code. then that will be:

Now, if we use Scikit-learn the implementation will become very easy.

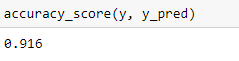
The accuracy of the Scikit-learn adaboost model will be:
link of the notebook used in this article:
https://github.com/Akashdawari/Articles_Blogs_Content/blob/main/All_About_AdaBoost.ipynb
Like and Share if you find this article helpful. Also, follow me on medium for more content related to Machine Learning and Deep Learning.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

