



Addressing Toxic Comments with Lightning Flash and Detoxify
Last Updated on December 8, 2021 by Editorial Team
Author(s): イルカ Borovec
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Natural Language Processing
Showcasing created a Nature Language Processing (NLP) model for detecting toxicity in plain text with Lightning Flash. We also present a community project called Detoxify, which offers HuggingFace models pre-trained with PytorchLightning.
This post walks through two methods to identify toxic comments as part of the 4th Jigsaw Rate Severity of Toxic Comments competition. The first method leverages a powerful NLP baseline model easily trained with Lighting Flash to classify toxicity levels of human comments. The second part showcases an open-source project, Detoxify, based on HuggingFace Transformers but trained with PyTorch Lightning (PL). In addition, Detoxify offers to use their already trained models saved as PL checkpoints.
A toxic comment is defined as a rude, dis- respectful, or unreasonable comment that is likely to make other users leave a discussion. A subtask of sentiment analysis is toxic comment classification. [Toxic Comment Detection in Online Discussions]
This Jigsaw Rate Severity of Toxic Comments is already the fourth edition on this topic. The previous competitions were simple classification and later also multi-language and multilabel tasks.
Jigsaw Rate Severity of Toxic Comments
This year’s edition of the Jigsaw challenge is different as the organizers introduced a new evaluations system. The organizers noticed that it is challenging and subjective to binary classify what comment is toxic (above some acceptable threshold). So they turned to a ranking system when organizers provide validation dataset — set side-by-side two comments where one is more toxic than the other. It is more natural for humans to do such ranking instead of predicting the absolute score for each sample without context.
Baseline with Lightning Fash
Lightning Flash is a handy AI toolbox covering significant domains such as Tabular data, Natural language Processing (NLP), Computer Vision, and many others. It offers several generic tasks — binary and multilabel classification and domain-specific, such as NLP translation or Question Answering.
For simplicity and close nature of the solving problem we will treat the task as simple text classification and we use the past competition’s datasets. To mention, that organizers even encourage using the past datasets.
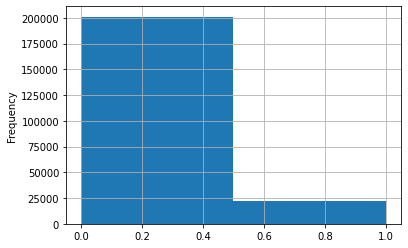
The figure above shows that the dataset is heavily imbalanced in favor of non-toxic labels even we aggregated over all subcategories: toxic, severe_toxic, obscene, threat, insult, identity_hate. When we read a few comments classified as non-toxic, we can feel a certain level of toxicity, which mirrors how tricky and subjective it can be to evaluate toxicity.
This post is based on Flash examples and our recent public Kaggle kernel:
🙊Toxic comments with Lightning⚡Flash
To train your model, you need to perform only three basic steps, following any general Machine Learning pipeline: (1) prepare and load dataset, (2) create the model with chosen backbone, and (3) train it. We show each of these steps accompanied by code snaped for illustration in the following lines.
1. Constructing the DataModule
We will use the single language binary dataset after the aggregation of all toxicity subclasses — simply, in a new column called “any”. We also need to specify which model we will use later to ensure the same tokenizer.
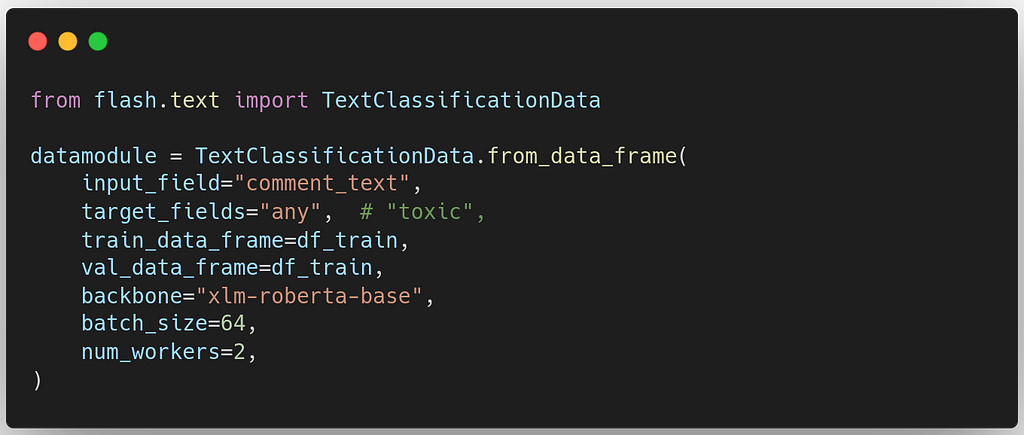
Flash directly integrates with the HuggingFace model hub so that you can use any model from this vast collection. In this baseline, we use “xlm-roberta-base” backbone model.
2. Creating the model
The model creation is straightforward. We pass the model name from the created DataModule, and the number of classes is automatically extracted from the provided dataset.

We replace the default Accuracy metric with Precision and F1 score from TorchMetrics to better monitor performances on our imbalanced dataset.
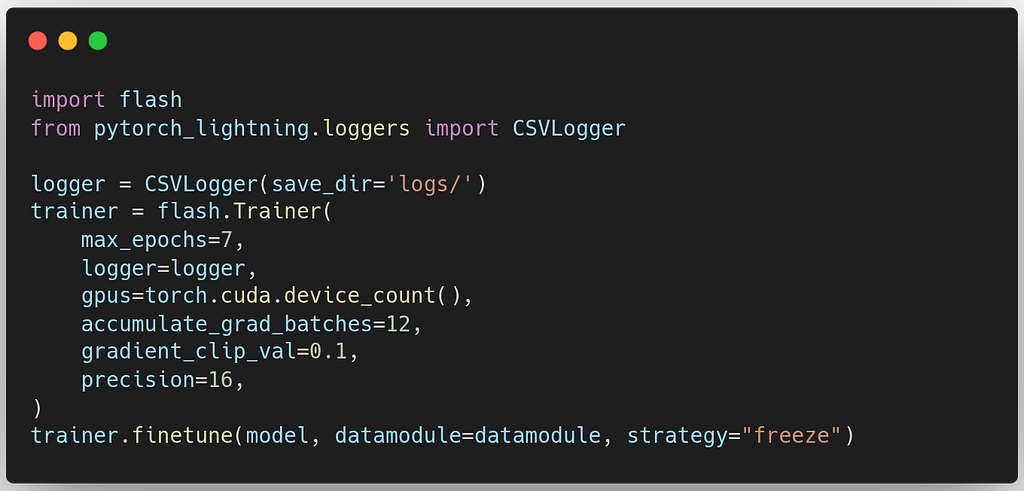
3. Training the model
With the instantiated DataModule and Model, we can start training. As Flash is built on top of PyTorch Lightning (PL), you can use the full features of the PL Trainer to train your model. Flash has a built-in default Tenrboard logger, which we replace in our demo with CSVLogger as it is more suitable for plotting results in notebooks.
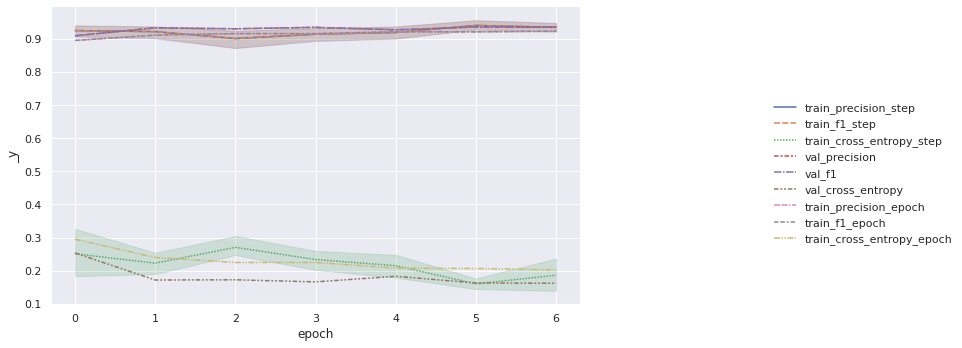
We take the logger results and plot the progress when training is done. The following chart shows that the pre-trained model performed well and that our finetuning is improving the model slowly. In this case, we can configure optimizers, learning rates, and schedules to improve convergence.
Inference & predictions
As the competition asks for some form of ranking, we have decided to return probabilities of being toxic instead of binary labels as it would better capture the nature of the given task.

Flash makes it easy to change the output format of predictions. We can change the output to Logits, which would offer more detailed descriptions on both ends of the probability range — explore tails squash by sigmoid.
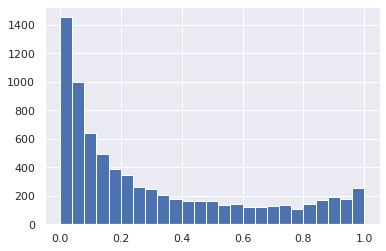
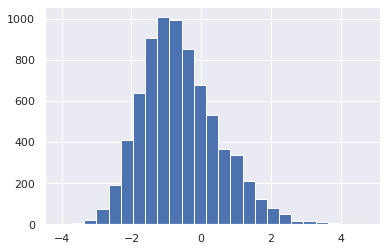
The baseline score on the leaderboard with three variants of predictions are:
* binary: 0.509
* probabilities: 0.696
* logits: 0.698
Pre-trained open-source protect Detoxify
In case you want to use something out of the box just for inference, you can search the HuggingFase hub and write light inference code to use this model. To compare the performance of our baseline, we evaluate it against the pre-trained models in the Detoxify project by unitary, which uses the same HuggingFase Transformers backbone as our previous Flash baseline (“xlm-roberta-base”).
Detoxify: Trained models & code to predict toxic comments on all 3 Jigsaw Toxic Comment Challenges. Built using zap Pytorch Lightning and hugs Transformers.
The model performs comparably to the top Kaggle solution according to the public leaderboard from the 3rd Jigsaw competition. Our demo Kaggle notebook for this fourth edition is publically available with downloaded checkpoints.
Score 🙊toxic comments with trained 🤗⚡Detoxify
In some of the following sections, we will refer to using offline kernels to install packages and downloaded checkpoints that we described in our previous post.
Easy Kaggle Offline Submission With Chaining Kernels
For resolving offline loading issues I am using my personal fork with necessary fixes: https://github.com/Borda/detoxify
Loading the pre-trained model
The Detoxify model can be instantiated by bypassing the checkpoint name or giving the downloaded checkpoint path and linking the HuggingFace stored model and tokenizer definition.
Inference: collect all predictions
The model has build-in support for GPU inference and predicts the scores as a single-line command, paired with pandas process mapping.

Compared to our previous Flash predictions, we can see that the scores favor toxic scores.
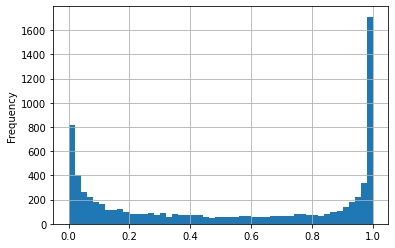
Compare on the validation dataset
We will demonstrate the performances on the provided validation dataset. The validation dataset comprises relative toxic comment pairs in which one comment is considered more harmful than the other.
The 30k comment pairs contain 15k unique comments with simple uniqueness analyses. We predicted each unique comment only once to reduce inference time, resulting in 15k predictions instead of 60k predictions (2 columns * 30k pairs) for the entire dataset.

Then we compare the toxicity score predicted for the assumed to be a less and more toxic comment in the validation dataset as a binary measure. Moreover, as Detoxify predicts scores for all seven toxicity subcategories, we evaluate each of them.
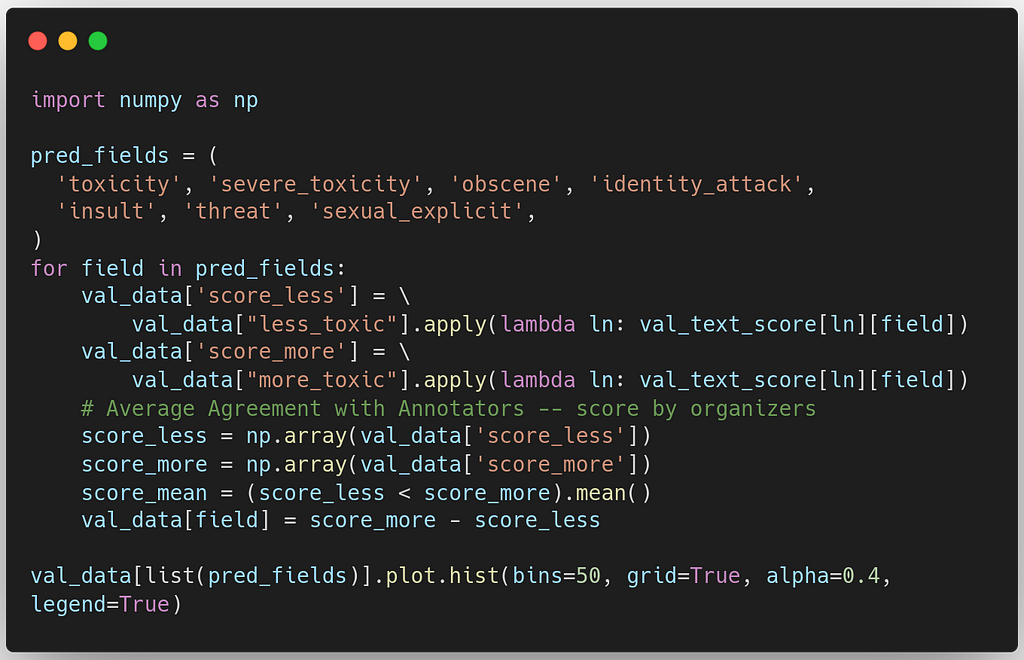
The distribution of the subcategory scores are very close, with validation score from 0.65 to 0.69
score for toxicity: 0.69356
score for severe_toxicity: 0.69542
score for obscene: 0.68111
score for identity_attack: 0.65862
score for insult: 0.68025
score for threat: 0.65082
score for sexual_explicit: 0.66334
Below, we plotted the difference between the scores to view the validation metric in a richer context. If the difference between the two comment scores is positive, they are correctly ranked, and if it is negative, they are incorrect.
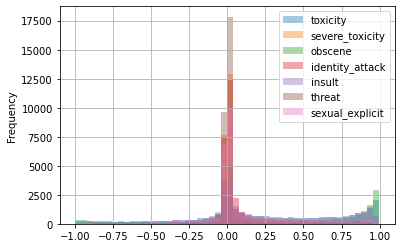
Compared to the Flash baseline trained on aggregated all kinds of toxicity, scoring 0.698 using any subclass of toxicity independently does not improve.
Thoughts on possible improvements
Let us briefly conclude with some next steps that we encourage readers to try with this competition, which can improve upon our baseline and are relatively simple to implement.
Construct a new dataset from the validation dataset
Given the validation dataset of comment pairs and knowing that, on average, each of them appears in the dataset about three times, we can do some week ordering and scale it into range (0, 1) and use it as our new training dataset with soft labels.
Hyperparameter search
As with any Machine Learning model, it is critical to select the best hyperparameters to get the most from a particular model. In the case of Flash integration with Transformers, we can optimize the model architecture, optimizer, scheduler, learning rate, tokenizer, and more. The Flash Zero CLI exposes all of these and can be swept over using cloud training tools.
HyperParameter Optimization with Grid.ai and No Code Change
Are you interested in more cool PyTorch Lightning integrations?
Follow me and join our fantastic Slack community!
About the Author
Jirka Borovec holds a Ph.D. in Computer Vision from CTU in Prague. He has been working in Machine Learning and Data Science for a few years in several IT startups and companies. He enjoys exploring interesting world problems, solving them with State-of-the-Art techniques, and developing open-source projects.
Addressing Toxic Comments with Lightning Flash and Detoxify was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



