



Active Learning and Semi-supervised Learning turn your unlabeled data into annotated data
Last Updated on December 9, 2021 by Editorial Team
Author(s): Edward Ma
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Machine Learning
Active Learning and Semi-supervised Learning
Active Learning is one of the teaching strategies which engage learners (e.g. students) to participate in the learning process actively. Compared to the traditional learning process, learners do not just sit and listen but work together with teachers interactively. Progress of learning can be adjusted according to the feedback from learners. Therefore, the cycle of active learning is very important. If you are not familiar with active learning, you may visit this post.
Semi-supervised Learning is a way to combine both labeled data and unlabeled data for model training. The assumptions of this approach are continuity assumption, cluster assumption and manifold assumption. In short, data points share the same label if they are closed to each other.
Hybrid Learning
Han et al. (2016) proposed to combine both active learning and semi-supervised learning for sound classification. Of course, we may apply it in other areas such as text, video, etc. Practitioners leverage the active learning approach to estimate the most valuable data points for labeling. However, they go further by introducing semi-supervised learning to estimate most confidence unlabeled after each round of iteration.
Overview
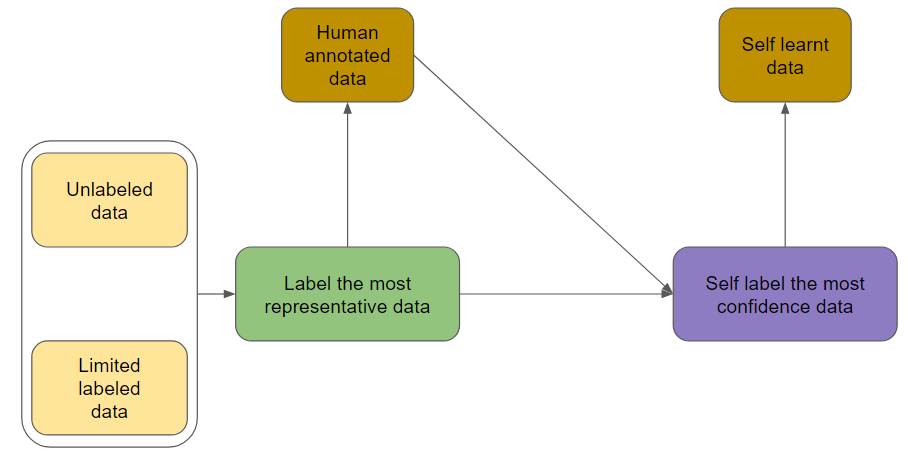
You may have a look at the following flow chart to understand how the aforementioned approach works. Here is the pseudo:
- We have a large amount of unlabeled data and limited labeled data at the beginning.
- Go through a normal active learning process to perform data annotation.
- Fit both initial labeled data and new annotated data to train a classification model and classify it.
- If the confidence is higher than the pre-defined threshold (says 85%), we will assign the label to those data.
- Repeat step 2 to step 4 until exit points. For example, acquired 500 annotated data or model performance achieves certain accuracy.
Most Confidence Sampling
The story does not finish yet. One of the outstanding is how do we control the self-learned data. By setting up a high threshold, we can ensure that the candidates should most likely belong to a particular category. However, we should not blindly trust it because of several reasons.
First of all, it may cause data imbalance. If the model is doing very well in one or a few categories, those self-learned data will belong to that one or a few categories and cause data imbalance after a few iterations.
To control the progress, we should acquire self-learned data progressively. Instead of picking those data points higher than the threshold, random sampling some of them is a better approach.
Python code by NLPatl
NLPatl provides semi-supervised learning in active learning. You just need to fit your data to it and you can annotate the most valuable data points and self-learned data points. Let prepare to get your hands dirty. I will walk through how can you apply active learning in NLP with a few lines of code. You can visit this notebook for the full version of the code.
# Initialize entropy sampling apporach to estimate the most valuable data for labeling
learning = SemiSupervisedLearning(
sampling=sampling,
embeddings_model=embeddings_model,
classification_model=classification_model
)
# Label data in notebook interactively
learning.explore_educate_in_notebook(train_texts, num_sample=2)
Reference
- W. Han, E. Coutinho, H. Ruan, H. Li, B. Schuller, X. Yu and X. Zhu. Semi-Supervised Active Learning for Sound Classification in Hybrid Learning Environments. 2016
Like to learn?
I am Data Scientist in Bay Area. Focusing on the state-of-the-art in Data Science, Artificial Intelligence, especially in NLP and platform related. Feel free to connect with me on LinkedIn or Github.
Active Learning and Semi-supervised Learning turn your unlabeled data into annotated data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


