



A New BLOOM in AI? Why the BLOOM Model Can Be a Gamechanger
Last Updated on July 5, 2022 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
We are now used to large language models, why is this so special?
Bigger and bigger
When BERT come out it was pretty clear which was the path the industry has chosen for the future of the natural language processing field. BERT was the first transformer that really got the attention but not the last (sadly, we can say the same for the movie series).
BERT open the way to BART, RoBERTa, and other large transformers model. It showed that stack of self-attention layers and more parameters was astonishingly good for many tasks (named entity recognition, translation, question answering, etc…). Then arrived in 2020 OpenAI strongly entered the competition with GPT-3 (a giant model with about 175 billion parameters). It was impressive but it stayed on the throne just for a while, Google and a few other companies release a parade of just bigger models. We saw Gopher (280 billion), PALM (540B), and LaMDA (137B). With the exception of chinchilla (70 billion, not very small anyway) the principle was the same gather more data and increase the number of parameters.
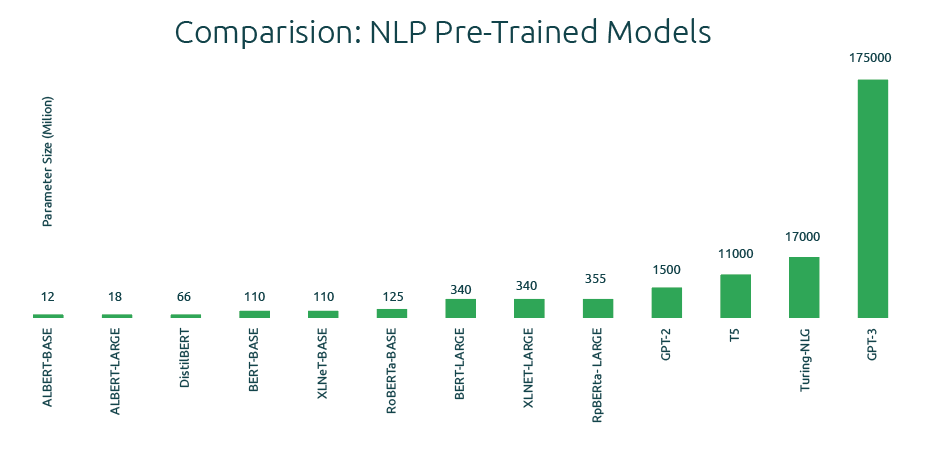
It was a race with few participants. The truth was that BERT showed the world that only the tech blue-chip companies could compete in the game. GPT3 is estimated to cost just 10–20 million dollars to train if we just consider the electricity bill (image how much it costs to buy all the GPU for the training).
The tech-pox: the open-source allergy that afflicts the tech company.
Everyone was thrilled to try GPT-3, GATO, Flamingo, DALL-E, and Imagen, however, there were restrictions in the best case (and a so long waiting list). OpenAI, Meta, Google, and Microsoft open-sourced some of their models (examples are OPT, VPT, and Switch Transformers) but they were not happy about it. The truth is if you have the best in class you want to keep to yourself. Google easily used BERT and following models to improve the Google search but loose the exclusive on it is another thing.
We all know the importance of open source (and if you forget, there is Linus Torvalds to remember it). We use it every day and whoever the program knows how important is to use the open-source component. However, open-source is make hitching company that would just like to make money.
To be fair, EleutherAI, BigScience, and Hugging Face tried to break down the monopoly and open source a lot of great models. Adam Smith says something like “the market regulates buy itself”, so you see now we have companies that will open-source stuff and we will solve the problem. Sure, we have 2 centuries of experience that what said Adam Smith was not true. So, at this point, we have a question about where there were the institutions?
The Good, the Bad and the Bias
Training these huge models is not environmentally friendly. Different articles pointed out the environmental impact of AI (even Forbes notice it, so you can imagine). The carbon footprint of training a large NLP model is quite impressive according to a study by the University of Massachusetts. Moreover, we have to deal with the cost and rare elements you need to produce the hardware (all the GPUs).
In addition, since word2vec was published in 2013 somebody noticed that there was something weird, the language models can be racist and misogynist. Why? Because with the aim of collecting as much data as possible, they often gathered data full of stereotypes. For example, Reddit is one of the most used sources for scraping data, and King’s College researchers published an article that showed evidence of gender and religious bias in Reddit communities. This sparked criticism and OpenAI claimed to have mitigated the bias in GPT-3. We know that companies controlling themselves are not enough (remember the promises of Facebook against fake news?). In fact, if these models will end in production we need to remove the harm as much as possible.
What is BLOOM?! Why I should care about another transformer-based model?

BLOOM (BigScience Language Open-science Open-access Multilingual) has 176 billion parameters and has been trained on 1.5 terabytes of text. Looking under the hood, the website reports it has 70 layers and uses multi-head attention. Ok, enough with the tech jargon, what does it mean? It is another transformer. Why so special?
Let’s start with the fact that behind BLOOM there is an international team of around 1,000 largely academic volunteers (more than 50 countries and over 20 languages). The project is encompassing institutions from France to Canada, but also companies such as Hugging Face.
Moreover, they released an ethical charter, where they described the core value that inspired the project. They decided to distinguish two categories intrinsic and extrinsic value. It is worth spending a short description of the values that inspired the project.
Intrinsic values:
- Inclusivity. The project aimed to avoid any discrimination.
- Diversity. The BigScience project was defined as a means of diversity, covering many researchers from different countries and backgrounds.
- Reproducibility. As a core value, they decided on open science
- Openness. Which they further subdivided into one focused on the process and one related to the results
- Responsibility. The responsibility that they described as individual and collective, which is also social and environmental.
Extrinsic values:
- Accessibility. They are described as linked to openness but extended with the aim to be accessible and explainable to the wider public.
- Transparency. related to openness, BigScience encourages the divulgation and diffusion of the project
- Interdisciplinarity. The focus was from the beginning to bridge different disciplines together (computer science, linguistics, sociology, philosophy, and so on).
- Multilingualism. Linked to the diverse values, they aimed since the project conception to cover different languages also as a means of inclusivity
Let’s start with the fact that this charter was not a vague promise. First, the model was trained on the Jean Zay public supercomputer powered by nuclear energy (which is a low carbon energy source). In addition, they used the heat generated by the hardware for eating buildings on the campus.
Aware of the past lessons, they tried to limit the hazard of racist or sexist associations. How? Including academics (including ethicists, legal scholars, and philosophers) but even company employers from Facebook or Google. Moreover, instead of just scraping the web, they select 500 sources (discussing in workshops including community groups such Masakhane, LatinX in AI, and Machine Learning Tokyo). Researchers told Nature, that even with all these cautions the model will not probably be free of bias. But since code and datasets are open they can understand the roots of harmful behavior and improve.
The model will be free to use and would be soon available through HuggingFace (they are planned also for a smaller and less hardware-intensive version as well as a server-distributed version).
Conclusions
NLP models will change probably the world and AI will be pervasive in all aspects of our future life. However, we know how monopolies are a problem when there are breakthrough technologies (remember the phone? Internet without dismantling monopoly would have been totally different). Until now language models have been the hobby of a small club of rich tech companies. BLOOM is the first effort to allow everyone to benefit from AI. In the future, we will have chat-bot probably everywhere and we need access to large models for the public.
Additional resources
- curious to know more about the technical part, give a glance here and here
- Do you want to know more about their approach? here
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here, is the link to my Github repository where I am planning to collect code, and many resources related to machine learning, artificial intelligence, and more.
A New BLOOM in AI? Why the BLOOM Model Can Be a Gamechanger was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")