



A Complete End-to-End Machine Learning Based Recommendation Project
Last Updated on July 26, 2023 by Editorial Team
Author(s): Gowtham S R
Originally published on Towards AI.
A machine learning recommendation project based on collaborative filtering and popularity-based filtering
What is a recommendation system?
Whenever we visit a shopping mall to buy a new pair of shoes or clothes, we find a dedicated person who helps us with the kind of products we should buy based on our preferences and makes our job simpler. In simple words, he is a recommendation system. But in this modern world, everything is online, and there is so much content on the internet, there are crores of videos on Youtube and crores of products on Amazon, which makes it difficult for the user to choose. There comes the recommendation system, which makes the user's life simple by recommending the next video to watch or a similar product to buy.
A recommendation system is a piece of code that is intelligent enough to understand the user’s preferences and recommend things based on his/her interest, the goal is to increase profitability. For Eg, Youtube and NetFlix want you to spend more time on their platform, so they recommend videos based on the user’s preferences. Amazon wants you to buy products from their website so that they can make more profit.
Simple ways to write Complex Patterns in Python in just 4mins.
Easy way to write complex pattern programs in python
medium.com
Types of Recommendation Systems:

Popularity-based: Recommending the top products from their website to every user. This method will not consider the user’s interest. Eg, the Trending section on Youtube, IMDB top 250 movies.
Content-based:

This is based on the similarity between the products. E.g., If a user has watched a movie and liked it, he may like to watch similar movies in the future. This can be based on the genre, actor, actress, or director.
Practical Implementation of Content-Based Recommendation System
A complete end-to-end Content-based recommendation system that recommends similar movies based on the user’s input.
medium.com
Collaborative filtering:

This is based on the similarity of users. E.g., If person A and B had watched and liked the movie M, next if person A watched the movie Z and liked it, we can recommend the movie Z to person B since A and B are similar users.
Hybrid filtering: This makes use of all or some of the above-mentioned methods to form a hybrid model.
Building a Book Recommendation System:
Let us look at how we can build a popularity-based and collaborative filtering-based book recommendation system.
Popularity-based filtering :
Let us import basic libraries, read the dataset and create the data frames. The dataset can be downloaded from this link — dataset.
books — the ‘books’ data frame has 2 columns ISBN(unique ID for each book) and Book-Title.
users — the ‘users’ data frame has 3 columns User-ID, Location, and Age.
ratings — the ‘ratings’ data frame has 3 columns User-ID, ISBN, and Book-Rating.
Let us look at the first 5 rows from each data frame.

The next step is to merge books and ratings on the column ‘ISBN’ and merge users and ratings on the column ‘USER-ID’.

Let us make 2 new data frames that will have a number of ratings and the average rating for each book and name them book_num_ratings and book_avg_ratings.
final_rating data frame is created by merging the two data frames book_avg_ratings and book_num_ratings

In order to implement popularity-based filtering, let us select only those books with more than 250 ratings sorted in descending order by avg_ratings,
Now we have successfully built a popularity-based recommendation system where we have filtered out the top 50 books from our dataset.

Collaborative Filtering:
To build a collaborative-filtering-based recommendation system, we will consider only those users who have rated more than 200 books and those books which are having at least 50 ratings.
We have a final data frame that has only those books with at least 50 ratings and users who have rated at least 200 books.

The next step is to create a pivot table that will have ‘Book-Title’ as the index, ‘User-ID’ as the column, and ‘Book-Rating’ as the value.

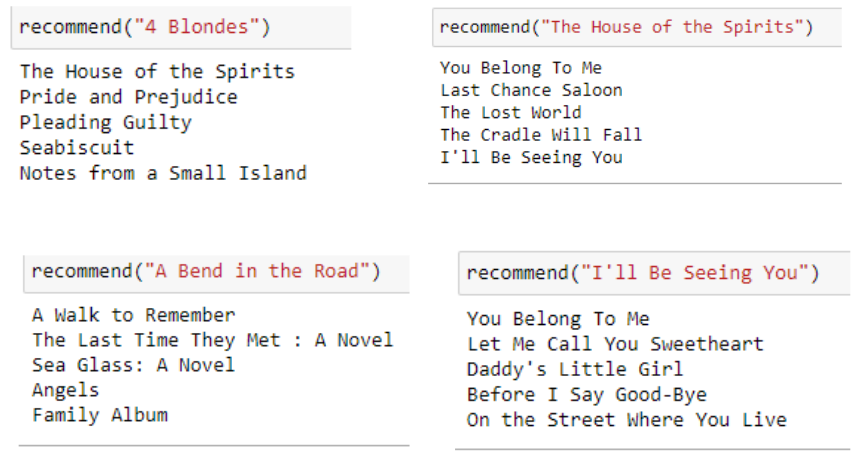
We will calculate the similarity score between each book using the cosine_similarity function. 5 books with the highest similarity scores will be recommended as shown below.
Below are a few results based on our recommendation model.

Now we have successfully built a popularity-based and collaborative filtering-based recommendation system. Let us deploy these models using flask.
Deploying the model:
Let us use the flask framework to deploy the model. We need to create a python file app.py, which will be linked to HTML files.
We should create a folder called templates where the HTML files index.html and recommend.html will be placed.
We need to place pickle files popularity.pkl, similarity.pkl, books.pkl, pt.pkl in the project folder.
Complete code can be found on the GitHub page
Popularity-based filtering: The home page of our app will show the top 50 books from our dataset along with the cover page, author, average rating, and the total number of votes.

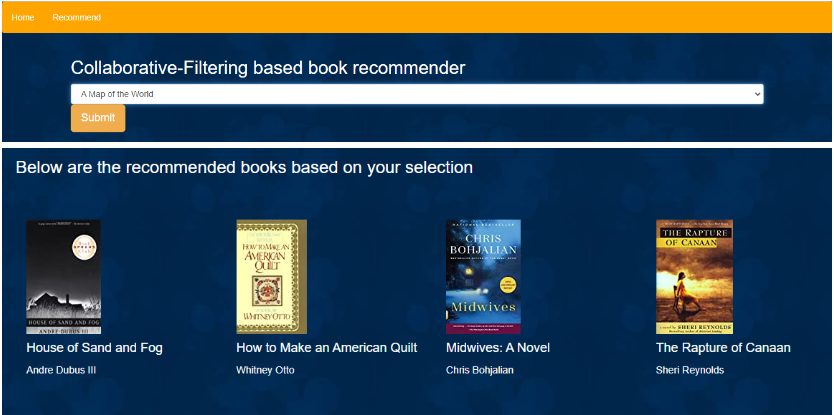
Collaborative filtering: When a user clicks the recommend icon, he will be prompted to the below page where a user can select the book for which he needs a recommendation, once submitted, similar books along with the cover page and author will be shown.
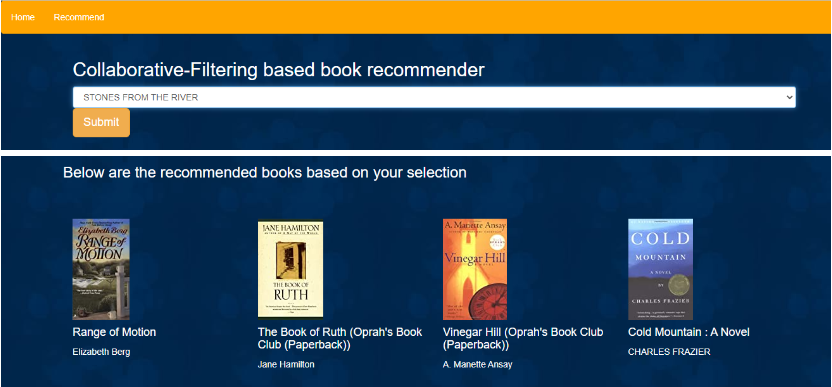
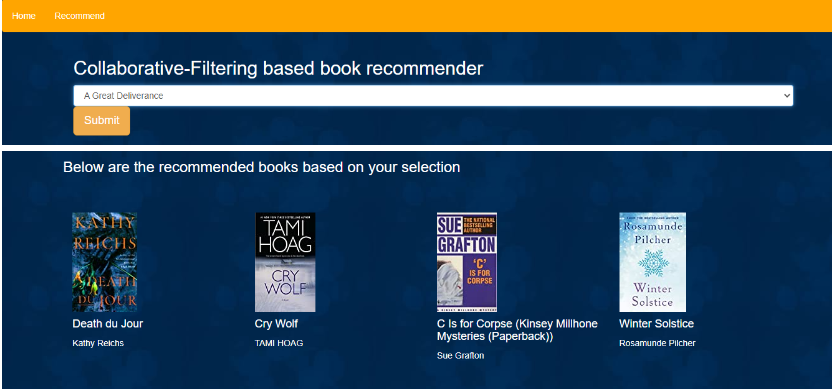
So, we have successfully completed the deployment part. You can try to implement this project this weekend.
Thank you.
Why is multicollinearity a problem?
What is multicollinearity? and why should we take care of multicollinearity before creating a machine learning model?
medium.com
Which Feature Scaling Technique To Use- Standardization vs Normalization
Is feature scaling mandatory? when to use standardization? when to use normalization? what will happen to the…
pub.towardsai.net
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

