



10 Topics and 50 Papers You Shouldn’t Miss
Last Updated on November 27, 2022 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A Guide to NeurIPS 2022–10 Topics and 50 Papers You Shouldn’t Miss
2672 main papers, 63 workshops, 7 invited talks, and finally, in person again. Language Models, Brain-Inspired research, Diffusion Models, Graph Neural Networks… NeurIPS comes packed with world-class AI research insights, and this guide will help you find where to direct your attention.
The 36th edition of the Neural Information Processing Systems Conference (NeurIPS) is about to kick off, and we can’t understate how excited we are to be going there. As it’s becoming a tradition for the conference, we want to help our audience navigate what can be a fascinating yet overwhelming lineup of 2672 papers, 163 Datasets & Benchmark track papers, and more than 700 workshop papers across 63 workshops, 43 of them in-person.
This year, we’ve divided the content into what we believe are 10 key topical areas, along with a brief description of what they contain and a selection of 5 papers you shouldn’t miss for each one of them. Were you to find yourself unreasonably intrigued by a specific paper, click on the 🔎 More like this paper button, and you’ll find a list of relevant papers at NeurIPS on the topic.
1. Language Models and Prompting
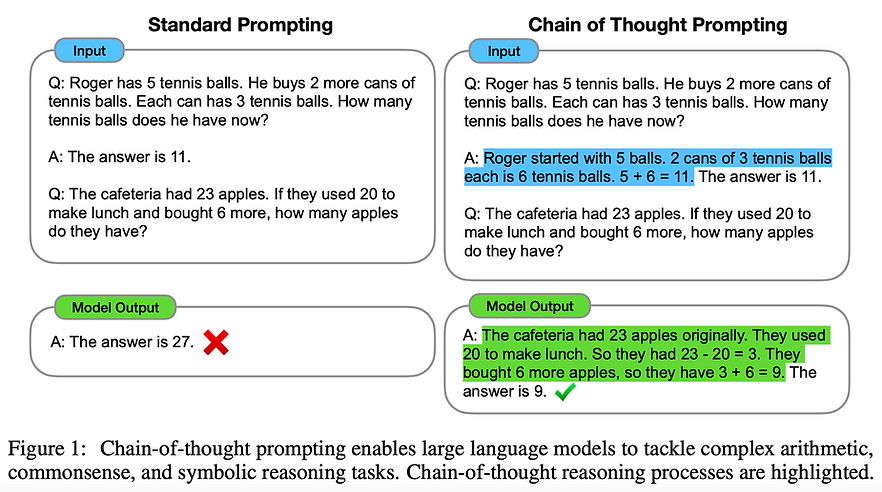
Arguably the most sought-after research area in AI — especially since the introduction of GPT-3 in 2020 — gets massive amounts of attention at the conference. With many blockbuster publications from the likes of Google, DeepMind, OpenAI, Meta, Stanford… all the big compute guys.
Expect to find a lot of work on “simple prompting” techniques like Chain of Thought techniques (or tricks?) that squeeze more performance out of plain pretrained autoregressive LMs. Multimodality also gets a spotlight this year, DeepMind’s Flamingo (vision + language) being the most popular of the bunch, Google’s Minerva shows how good LMs can be at math when pretrained with the right data, and InstructGPT showcases how human feedback and Reinforcement Learning can be used to fine-tune large LMs.
1️⃣ Chain of Thought Prompting Elicits Reasoning in Large Language Models
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More like this paper
💡 Simply prompting LMs to output reasoning steps instead of direct answers drastically improves performance. See also follow-up works like STaR.
2️⃣ Flamingo: a Visual Language Model for Few-Shot Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More like this paper
💡 DeepMind introduces a “simple” single model pretrained on vision + language, sets state of the art on various multimodal tasks
3️⃣ Solving Quantitative Reasoning Problems with Language Models (Minerva)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More like this paper
💡 A large LM trained on mathematical data can achieve strong performance on quantitative reasoning tasks, including state-of-the-art performance on the MATH dataset.
4️⃣ Data Distributional Properties Drive Emergent In-Context Learning in Transformers
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More like this paper
💡 What aspects of large-scale pre-training drive in-context learning? Training data distribution needs burstiness and a large number of rarely occurring cases.
5️⃣ Training language models to follow instructions with human feedback (InstructGPT)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More like this paper
💡 OpenAI uses Reinforcement Learning from Humans in the Loop (RLHF) to fine-tune GPT-3 using data collected from human labelers. The resulting model, called InstructGPT, outperforms GPT-3 on a range of NLP tasks.
2. Diffusion Models
Granted, if anything deserves the coolest-kid-in-town crown in 2022, it has to be text-to-image generation models, most of them powered by Diffusion Models: OpenAI’s DALL·E 2, Google’s Imagen, or Stable diffusion.
As an early sign of maturity — and barely 2 years since they became popular! — the modeling technique has now spread beyond the realm of 2D still image generation and is being applied to 3D scene synthesis, video generation, and molecular docking, among others. As we saw with Transformers in 2017, the time it takes for a research idea to become mainstream just keeps shortening.
1️⃣ Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Imagen, a simple approach to text-to-image synthesis using diffusion models.
2️⃣ Object Scene Representation Transformer (OSRT)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A highly efficient 3D-centric model in which individual object representations naturally emerge through novel view synthesis.
3️⃣ Denoising Diffusion Restoration Models (DDRM)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Super-resolution, deblurring, inpainting, and colorization using pre-trained Denoising Diffusion Probabilistic Models (DDPMs) without problem-specific supervised training.
4️⃣ Flexible Diffusion Modeling of Long Videos
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 DDPMs applied to the video domain. To capture long-range dependencies between frames, they present an architecture that can be flexibly conditioned on any subset of video frames.
5️⃣ EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Energy-guided stochastic differential equations (EGSDE) that employ an energy function pretrained on both the source and target domains to guide the inference process of pretrained SDE for realistic and faithful unpaired Image-to-image (I2I).
3. Self-Supervised Learning
Self-Supervised Learning (SSL) has become such an essential ingredient of modern ML that it’s now pretty much baked into most research in one way or another. For the first time in Deep Learning, NLP led the way with BERT in 2018, and Computer Vision later joined the SSL bandwagon with successful techniques like SimCLR.
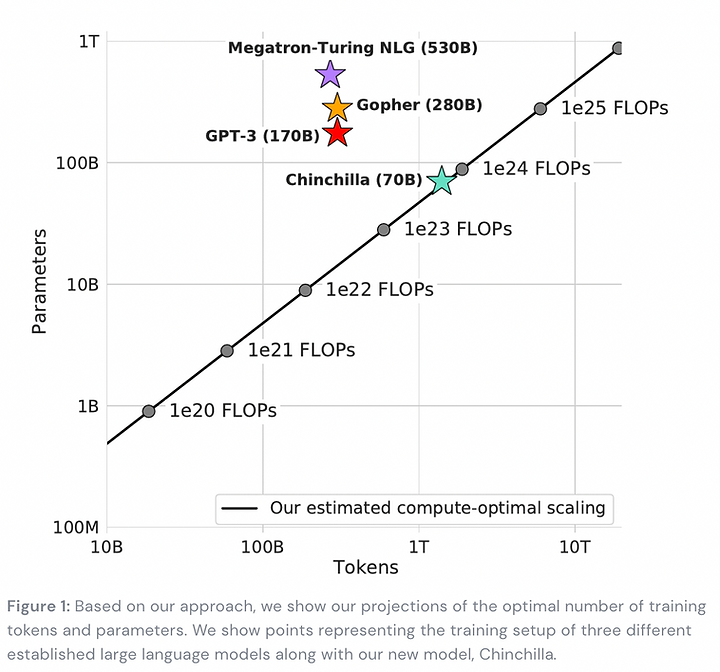
This region of our semantic map has a heavy representation of novel SSL techniques for Computer Vision: learning from unsupervised videos, the effects of data augmentation on images… But arguably, the cherry on top is DeepMind’s Chinchilla: a study on how much of a Language Model’s pretraining budget should be spent on model parameters and how much in a larger training corpus (finding that most large LMs are too big or undertrained), resulting in Chinchilla, a 70B parameter LM that outperforms its bigger counterparts by training for longer.
Finally, we also couldn’t miss out on wild new (partly) SSL techniques for Information Retrieval, such as the Differentiable Search Index.
While SSL is now so commonplace it’s often relegated to a disinterested footnote. All this research is proof that there are many stones unturned in this area with new insights to discover.
1️⃣ An empirical analysis of compute-optimal large language model training (Chinchilla)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 It’s better to train a smaller Language Model on more tokens. DeepMind showcases this with their 70B Chinchilla model outperforming bigger models such as Gopher (280B), GPT-3 (175B) or Megatron-Turing NLG (530B).
2️⃣ VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Pretraining video representations on video done exquisitely. 3 takeaways: high masking ratio is best, technique works well even on small datasets, and quality > quantity when it comes to Self-Supervised Video Petraining.
3️⃣ Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A systematic study of the interactions between the pretraining data sources for CLIP. Surprisingly (?) mixing multiple data sources does not necessarily yield better models, which is corroborated by our theoretical analysis of toy models.
4️⃣ A Data-Augmentation Is Worth A Thousand Samples: Analytical Moments And Sampling-Free Training
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 An analytical study of data augmentation (DA) and how it impacts the parameters of a model. E.g., given a loss at hand, common DAs require tens of thousands of samples for the loss to be correctly estimated and for the model training to converge.
5️⃣ Transformer Memory as a Differentiable Search Index
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A single Transformer is trained to directly output document identifiers autoregressive given a query as a prompt. Followup work is also presented at NeurIPS, such as the A Neural Corpus Indexer for Document Retrieval.
4. Graph Neural Networks
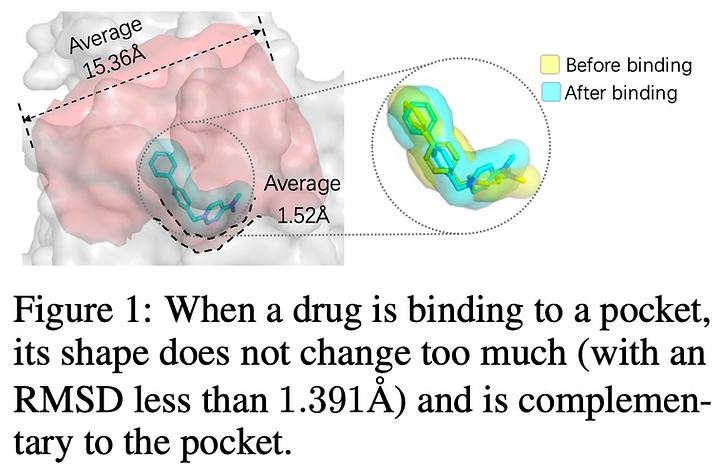
Equivariances, 3D molecule generation, Partial Differential Equations… Graph Neural Networks (GNNs) have been around for a while now, and while they haven’t achieved celebrity-level popularity like Transformers or Diffusion Models, they’ve steadily grown their pie in the last couple of years, extending into applications such as drug design, differential equation solving or reasoning.
This heterogeneous landscape makes sense because, as outlined in the Geometric Deep Learning blueprint, in a way, GNNs is a new abstraction on NNs to unlock thinking from first principles about how to cast arbitrary problems into the right architectures, escaping the curse of dimensionality by leveraging symmetries and invariances. For example, this is key for finding the right representations to computationally solve Partial Differential Equations or predicting the shapes of organic molecules to design new drugs more efficiently.👇
1️⃣ Zero-Shot 3D Drug Design by Sketching and Generating (DESERT)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A zero-shot drug design method powered by pre-training techniques. Existing deep-learning-based methods for drug design often rely on scarce experimental data or slow docking simulation. DESERT splits the design process into sketching and generation phases, speeding up generation while preserving high accuracy.
2️⃣ Torsional Diffusion for Molecular Conformer Generation
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Drug-like Molecule Conformer Generation via diffusion process on torsion angles the Fast and accurate conformer generation via diffusion modeling on the hypertorus and an extrinsic-to-intrinsic score model, while being orders of magnitude faster than previous diffusion-based approaches.
3️⃣ MAgNet: Mesh Agnostic Neural PDE Solver
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A novel mesh-agnostic architecture that predicts solutions to PDE at any spatially continuous point of the PDE domain and generalizes across different meshes and resolutions.
4️⃣ MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Message Passing NNs (MPNNs) is a powerful way to model interatomic potentials, but they’re inefficient. MACE introduces higher-order message passing in a highly parallel manner achieving SOTA in various benchmarks.
5️⃣ Few-shot Relational Reasoning via Connection Subgraph Pretraining (CSR)
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 CSR can make predictions for the target few-shot task directly by self-supervised pre-training over knowledge graphs.
5. Reinforcement Learning

Making agents more efficient learners is a key question RL researchers are still grappling with, and this year’s NeurIPS contains many proposals on how to achieve it. For instance, using offline learning and imitation learning at scale to overcome the initial inefficient exploration phase, improving credit assignment techniques to better navigate sparse rewards landscapes, or using pretrained Language Models to bootstrap policies with human priors. Other points of interest often revolve around robustness and reproducibility, which are closely related to efficiency in challenging open-ended settings.
Finally, RL also sees successful application in areas like chip design with quite a few papers on the topic (seriously, check out the “More like this!”).
1️⃣ Using natural language and program abstractions to instill human inductive biases in machines
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Meta-learning agents can learn human inductive biases through co-training with representations from language descriptions and program induction.
2️⃣ MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Leveraging large pretrained models to automatically label videos with actions to create large-scale datasets for offline learning, just with video data from Minecraft.
3️⃣ MaskPlace: Fast Chip Placement via Reinforced Visual Representation Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 RL agents that learn to distribute components on a silicon chip design better than humans.
4️⃣ Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 MCTS made more efficient by allocating a higher compute budget on harder states.
5️⃣ Trajectory balance: Improved credit assignment in GFlowNets
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A new training objective for generative flow networks that tackles the problem of credit assignment (what action within a trajectory is most responsible for a final reward?) leads to faster convergence and better fitting to a target distribution.
6. Brain-Inspired
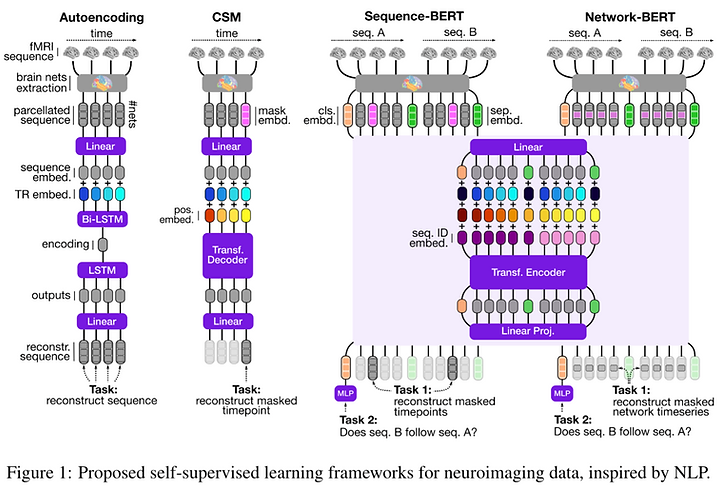
Let’s not forget NeurIPS is also home for neuroscience adjacent literature; after all, our brains are the OG neural information processing system that sparked much of the modern artificial NNs.
This diverse area involves a lot of learning from brain imaging techniques such as fMRI, alternatives to backprop for learning that bode better with what we know about neurons, spiking Neural Networks, and more!
1️⃣ Learning on Arbitrary Graph Topologies via Predictive Coding
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡Backprop does not allow training on networks with cyclic or backward connections, which are hypothesized to be essential in brain-like computation. They show how predictive coding (PC), a theory of information processing in the cortex, can be used to perform inference and learning on arbitrary graph topologies.
2️⃣ Theoretically Provable Spiking Neural Networks
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A theoretical investigation on the approximation power and computational efficiency of spiking neural networks with self-connections.
3️⃣ Self-Supervised Learning of Brain Dynamics from Broad Neuroimaging Data
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Novel self-supervised learning techniques for neuroimaging data inspired by prominent learning frameworks in natural language processing, using one of the broadest neuroimaging datasets used for pre-training to date.
4️⃣ On the Stability and Scalability of Node Perturbation Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Node perturbation is scalable against overparameterization but unstable in the presence of a model mismatch.
5️⃣ An Analytical Theory of Curriculum Learning in Teacher-Student Networks
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A solvable model of curriculum learning and comment on the implications for the ML and the experimental psychology literature.
7. Out-of-Domain Generalization
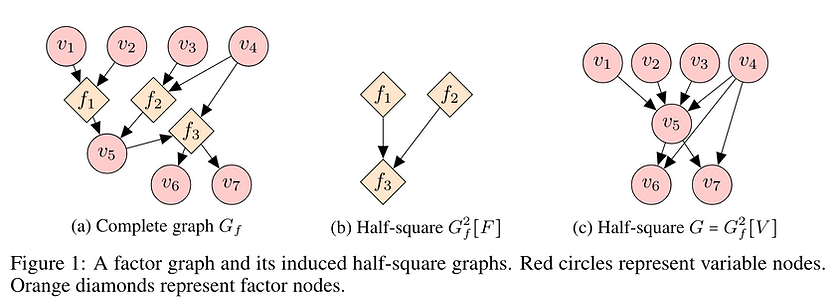
Out-of-Domain generalization and closely related, causality, are topics of high interest in academic research. While standalone OOD research hasn’t fully broken into the mainstream, there’s an undeniable trend broadly in Machine Learning benchmarking culture towards caring more and more about robustly generalizing in challenging conditions such as zero/few-shot or under heavy data distribution shifts because static in-domain evaluations have been cracked one after the other at a record-breaking pace.
The area — as most in the early stages — still suffers from a lack of standardization, which is why we’re highlighting a couple of publications on the topic (2, 3). In addition, we’re highlighting a simple ensemble technique to domain generalization (1), tabular embeddings (4), and sparsely connected factor graphs at scale for causal discovery (5), which represents progress in a research direction we’ve highlighted before: the use of sparsity + communication bottlenecks to constrain the model into learning models of the world that capture its robust causal structure.
1️⃣ Ensemble of Averages: Improving Model Selection and Boosting Performance in Domain Generalization
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A simple hyper-parameter-free strategy of using the simple moving average of model parameters during training and ensembling achieves SOTA on domain generalization benchmarks and can be explained using the Bias-Variance trade-off.
2️⃣ Assaying Out-Of-Distribution Generalization in Transfer Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A large-scale empirical study of out-of-distribution generalization.
3️⃣ Is a Modular Architecture Enough?
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Metrics to study a broad range of mixture-of-experts styled modular systems. Such systems suffer from problems of collapse and specialization and might require additional inductive biases to overcome this sub-optimality.
4️⃣ On Embeddings for Numerical Features in Tabular Deep Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Representing numerical features with vectors instead of scalar values can significantly boost DL models for tabular data.
5️⃣ Large-Scale Differentiable Causal Discovery of Factor Graphs
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Using factor graphs for large-scale causal discovery learning with interventional data.
8. Learning Theory
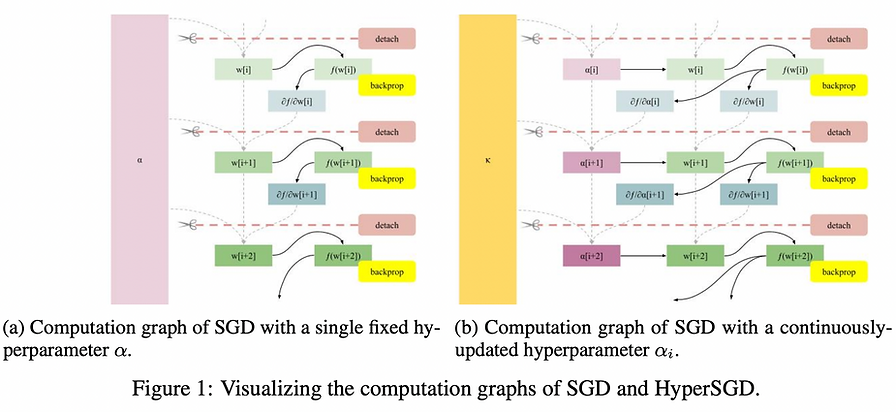
Okay, let’s start by admitting that many of us kinda find the heavy-duty mathy stuff off-putting. Still, there’s so much to learn from it at NeurIPS.
For instance, large batch sizes have proven to be essential to successfully learn representations with contrastive learning. This makes sense intuitively, but is there a more grounded statistical explanation? (1) Or what guarantees can we expect when using autodiff blindly over functions that aren’t smooth enough? (3) Or under which conditions is performing well in Out-of-Distribution even possible? (2). Check out the papers below if you’re intrigued by these questions.
1️⃣ Why do We Need Large Batch sizes in Contrastive Learning? A Gradient-Bias Perspective
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A Bayesian data augmentation method to disentangle negative samples for gradient bias mitigation in contrastive learning.
2️⃣ Is Out-of-Distribution Detection Learnable?
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Through the lens of Probably Approximately Correct (PAC) learning theory, this work studies the generalization of OOD detection: classifying whether a sample falls within the training distribution or not. They find this is impossible under some conditions and prove formal theorems around it, but these conditions are mostly not a concern in real-world problems.
3️⃣ Automatic differentiation of nonsmooth iterative algorithms
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 What happens when you apply autodiff to functions that aren’t smooth enough? It’s mostly fine. They converge to classical derivatives anyway.
4️⃣ Efficient and Modular Implicit Differentiation
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Autodiff but in the implicit form (i.e. when you can’t isolate f(x) in the left side of the equal sign). Implemented in JAX.
5️⃣ Gradient Descent: The Ultimate Optimizer
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Using gradient descent to tune not only hyperparameters but also hyper-hyperparameters, and so on… This work shows how to automatically compute hypergradients with a simple and elegant modification to backpropagation.
9. Adversarial Robustness, Federated Learning, Compression
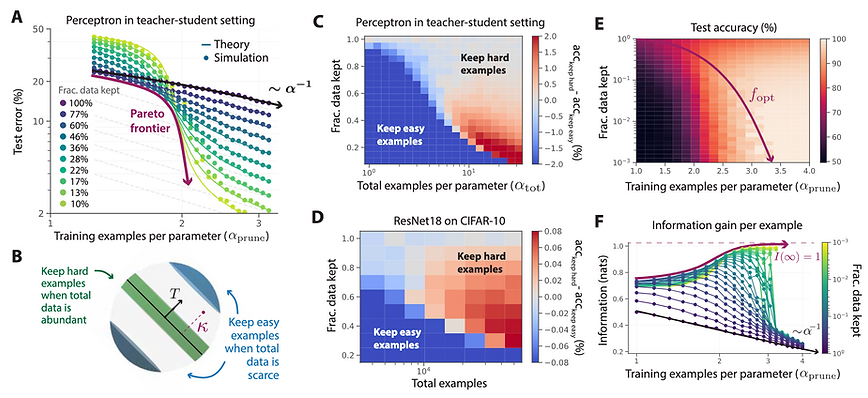
Adversarial Robustness in ML has been a thing for longer than I can remember, and this year it’s no different (3, 5). This is understandable as this is a concern of high importance when it comes to using models in safety-critical applications such as self-driving.
On the other hand, Federated Learning, sometimes married with Differential Privacy is another prolific area of research that still needs to find its use in the mainstream real-world applications (2). A camp that decidedly already has widespread usage in the real-world, compression, pruning, and other speed/efficiency enhancing techniques (4). Finally, a new twist on pruning that looks at pruning data, not weights, to train NNs faster than scaling laws would allow for! (1)
1️⃣ Beyond neural scaling laws: beating power law scaling via data pruning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 In theory and practice, power-law scaling of error with respect to dataset size can be improved via intelligent data pruning.
2️⃣ Self-Aware Personalized Federated Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 We propose a new adaptive federated learning algorithm for personalization.
3️⃣ Increasing Confidence in Adversarial Robustness Evaluations
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A test that enables researchers to find flawed adversarial robustness evaluations. Passing this test produces compelling evidence that the attacks used have sufficient power to evaluate the model’s robustness.
4️⃣ On-Device Training Under 256KB Memory
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A framework for on-device training on tiny IoT devices, even under a limited memory budget of 256KB.
5️⃣ Pre-trained Adversarial Perturbations
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A novel algorithm to generate adversarial samples using pre-trained models which can fool the corresponding fine-tuned ones and thus reveal the safety problem of fine-tuning pre-trained models to do downstream tasks.
10. Datasets & Benchmarks

Last but not least, the unsung heroes of ML. As the pace of progress keeps accelerating and even modern datasets saturate faster than most predicted [link to palm and instruction fine-tuning], new datasets that measure interesting phenomena must emerge to substitute them. Like last year, NeurIPS had a special track for datasets and benchmark papers (see the full list of them here).
Many of the proposed benchmarks are incredibly interesting and useful, so the list below is guaranteed to miss some of those. Still, here it goes👇
1️⃣ LAION-5B: An open large-scale dataset for training next generation image-text models
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 An open, publically available dataset of 5.8B image-text pairs and validate it by reproducing results of training state-of-the-art CLIP models of different scales.
2️⃣ DC-BENCH: Dataset Condensation Benchmark
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Dataset Condensation aims to learn a tiny dataset that captures the rich information encoded in the original dataset. Comparing condensation remains a challenge, which is why this benchmark is proposed.
3️⃣ NeoRL: A Near Real-World Benchmark for Offline Reinforcement Learning
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 The Near real-world offline RL benchmark (NeoRL) is a benchmark with emphasis on the complete pipeline for deploying offline RL in real-world applications that aims to bridge the performance gap between offline evaluation and online deployed performance.
4️⃣ A Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 Injecting a backdoor during the training phase can be a powerful way for adversaries to control NLP systems such as Language Models. This work presents an open-source toolkit OpenBackdoor that enables rigorous evaluation of how vulnerable models are to these kinds of attacks.
5️⃣ PEER: A Comprehensive and Multi-Task Benchmark for Protein Sequence Understanding
🔗 OpenReview | 🖥 Virtual Poster | 🔎 More papers like this
💡 A comprehensive and multi-task benchmark for protein sequence understanding, which studies both single-task and multi-task learning.
Our selection ends here, but our NeurIPS coverage has just started! We’ll be live tweeting from New Orleans during the conference, so make sure to follow us on Twitter @zetavector to stay up to date with everything that’s happening there!
10 Topics and 50 Papers You Shouldn’t Miss was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

