



Pre-train, Prompt, and Predict – Part1
Last Updated on March 4, 2023 by Editorial Team
Author(s): Harshit Sharma
Originally published on Towards AI.
Pre-train, Prompt, and Predict — Part1
The 4 Paradigms in NLP
(This is a multi-part series describing the prompting paradigm in NLP. The content is inspired by this paper (a survey paper explaining the prompting methods in NLP)
(Source: Image from Paper) Prompting paradigms
I came across this wonderful paper on Prompting while going through this amazing course on Advanced NLP (UMass). Being a survey paper, they have given a holistic explanation of this latest paradigm in NLP.
Over multiple articles, we will be discussing the key highlights from the paper and learn why Prompting is considered to be “The Second Sea Change in NLP”.
To appreciate what is prompting and to get started, Part 1 discusses 4 major paradigms that have occurred over the past years.
Let’s get started !!

Fully-Supervised Learning (Non-Neural Network)
— powered by —
Feature Engineering
- Supervised learning required input-output examples to train the model.
- In the Pre-Neural-Network era, these NLP models required
Feature Engineering, where NLP researchers use domain knowledge to extract features from limited data and infuse inductive bias into the model - There was NO Relation between the Language Models and the downstream tasks that were solved. Each task had to have its own trained model

Fully-Supervised Learning (Neural Network)
— powered by —
Architecture Engineering
- Neural Networks came and with that the automatic learning of features from training data. Manual feature engineering was no longer necessary
- The focus shifted to Architecture Engineering, where NN architectures were engineered to provide the appropriate inductive bias to the model
- Again, No relation between the training of language models and solving the downstream tasks. Each task was solved using its own model architecture.
 — — — — —-The First Sea Change — — —— —
— — — — —-The First Sea Change — — —— —
Pre-train and Fine-Tune
— powered by —
Objective Engineering
- This was the first time a Language Model was pre-trained on massive data and later adapted to downstream tasks via fine-tuning using task-specific objectives.
- The focus shifted to Objective Engineering, designing training objectives both during the pre-training and fine-tuning stages
- The below diagram shows how Language Models play a central role in this paradigm. Unsupervised training of LMs is combined with Task specific supervised fine-tuning
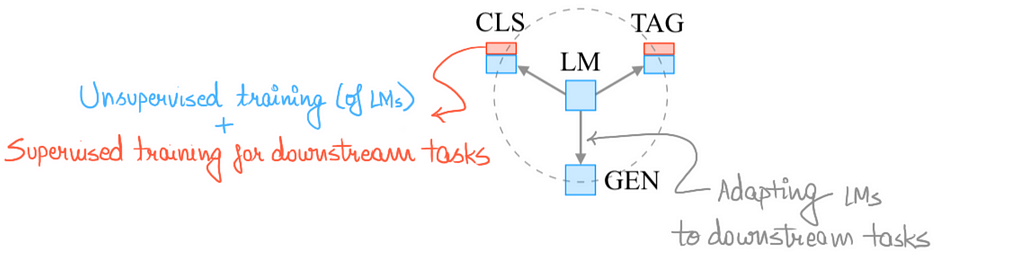 (Source: Paper, modified by Author) Relationship between Language Model pre-training and various downstream tasks.
(Source: Paper, modified by Author) Relationship between Language Model pre-training and various downstream tasks. — — — — — -The Second Sea Change — — — — —
— — — — — -The Second Sea Change — — — — —
Pre-train,Prompt,Predict
— powered by —
Prompt Engineering
- Instead of adapting LM to a specific task via objective engineering, the downstream tasks are reformulated using a Textual Prompt.
Eg: To find the emotion of “I missed the bus today”, feed the model “I missed the bus today. I felt so _____”. The trained LM will try to fill the blank with appropriate emotion, eventually giving us the emotion of the input. - This doesn’t require any task-specific training
- This calls for a focus on Prompt Engineering since prompt needs to be engineered correctly in order to elicit appropriate / desired response from the model.
That’s all for Part 1!! In Part 2, we will be diving into Prompting, its basics, its applications, various design considerations while designing prompts, etc.

Follow me and Subscribe so that you don’t miss out on the Prompting series and the upcoming articles on ML/NLP
Pre-train, Prompt, and Predict — Part1 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

