


From Raw to Refined: A Journey Through Data Preprocessing — Part 3: Duplicate Data
Last Updated on August 28, 2023 by Editorial Team
Author(s): Shivamshinde
Originally published on Towards AI.
This article will explain how to identify duplicate records in the data and, the different ways to deal with the problem of having duplicate records.
Why the presence of duplicate records in data is a problem?
The presence of duplicate values in the data is often ignored by many programmers. But, dealing with the duplicate records in the data is quite important.
Having duplicate records can lead to incorrect data analysis and decision-making.
For example, what happens when you replace missing values (imputation) with mean in data with duplicate records?
In this scenario, the incorrect mean value may be used for imputation. Let’s take an example.
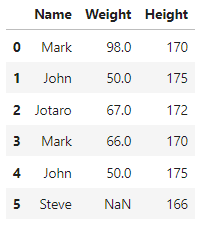
Consider the following data. Data contains two columns, namely Name and Weight. Note that the weight value for the ‘John’ is repeated. Also, the weight value for ‘Steve’ is missing.

If one wishes to impute the missing value of weight for Steve with the mean of all the weight values, then the imputation would be done using the incorrect mean, i.e.,
(98 + 50 + 67 + 66 + 50)/5 = 66.2
But the actual mean of the data by ignoring the duplicate value is
(98 + 50 + 67 + 66)/4 = 70.25
Therefore, the missing value will be incorrectly imputed if we do not do something about the duplicate records.
Moreover, duplicate values may even affect the business decisions that are made using such faulty data.
In summary, duplicate records from the data should be dealt with to keep the data free from problems.
Now, let’s see different methods to deal with the duplicate records in the data.
Identifying the duplicate values in the data
We can use the pandas duplicated method to identify the rows that are duplicated in the data.
Now, let’s understand the duplicate values using an example.
## Importing required libraries
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
## Creating a dataframe
Name = ['Mark', 'John', 'Jotaro', 'Mark', 'John', 'Steve']
Weight = [98, 50, 67, 66, 50, np.nan]
Height = [170, 175, 172, 170, 175, 166]
df = pd.DataFrame()
df['Name'] = Name
df['Weight'] = Weight
df['Height'] = Height
df
Identifying duplicate values:
## Identifying the duplicated values (default behavior)
df.duplicated()

We get the value True, where the duplicate record is present, and False where the unique records are present.
Note that by default, duplicated() method uses all the columns to find duplicate records. But, we can use the subset of columns to find the duplicates as well. To do this, duplicated() method has a parameter named subset. The subset parameter takes the list of column names that we want to use for finding duplicates.
## subset parameter of duplicated() method
df.duplicated(subset=['Name','Height'])

Additionally, duplicated() method has one more important parameter named keep. The value of the keep parameter decides whether we consider the first record or the last record as unique in all the duplicated records. We also have the option where we can consider all the duplicate records as non-unique.
keep = ‘first’: The first record in all of the duplicate records is considered unique
keep = ‘last’: The last record in all of the duplicate records is considered unique
keep = False: All the duplicate records are considered as non-unique.
## keep parameter of duplicated() method
df.duplicated(keep='first')

Notice here that the first duplicate value (at index 1) is considered unique and all the others (at index 4) are considered duplicates.
## keep parameter of duplicated() method
df.duplicated(keep='last')

Notice here that the last duplicate value (at index 4) is considered unique and all the others (at index 1) are considered duplicates.
## keep parameter of duplicated() method
df.duplicated(keep=False)

Notice here that all the duplicate records (at index 1 and index 4) are shown.
How to deal with duplicate records in data
The next step after identifying the duplicate records is to deal with them.
There are two ways to deal with the duplicate records in the data.

Removing the duplicate records
Let’s start with the approach where we remove the duplicate records.
We can make use of the pandas drop_duplicates() method for this.
By default, drop_duplicates() method keeps the first record from the set of all the duplicate records and then drops the rest of them from the data. Also, by default, drop_duplicates() method uses all the columns to identify the duplicate records.
But this default behavior can be changed using the two parameters of the drop_duplicates() method. They are
- keep
- subset
They work exactly how the keep and subset parameters of duplicated() method work.
"""dropping duplicate values using the pandas drop_duplicates() method
(default behavior)"""
df1 = df.drop_duplicates()
df1

"""dropping duplicate values using the pandas drop_duplicates()
method with subset and keep parameters (custom behavior)"""
df2 = df.drop_duplicates(subset=['Weight'], keep='last')
df2

Updating the duplicate records
Sometimes we want to replace the duplicate records with some value. Let’s say we found two duplicate records, then we got to know that the person who acquired the data accidentally put the wrong name in one of the duplicate records. So in such a case, we would want to put the name of the correct person. Thus, this would solve the problem of duplicate values.
df.duplicated(keep=False)

Here, we have duplicate records at the indices 1 and 4. Now, if we changed the value of ‘Name’ column at index 1, then we won’t have duplicate values anymore.
## changing the 'Name' value for the first duplicate record
df.iloc[1, 0] = 'Dio'
df

We changed the ‘Name’ value for the first duplicate record. Now, let’s again check if there are duplicated records present in the data or not.
df.duplicated()

Now, we don’t have any duplicate records.
Thanks for reading! If you have any thoughts on the article, then please let me know.
Are you struggling to choose what to read next? Don’t worry, I know of an article that I believe you will find interesting.
From Raw to Refined: A Journey Through Data Preprocessing — Part 2 : Missing Values
Why deal with missing values?
pub.towardsai.net
and one more…
From Raw to Refined: A Journey Through Data Preprocessing — Part 1: Feature Scaling
Sometimes, the data we receive for our machine learning tasks isn’t in a suitable format for coding with Scikit-Learn…
pub.towardsai.net
Shivam Shinde
Have a great day!
References:
Handling Duplicate Values in a Pandas DataFrame
As a data analyst, it is our responsibility to ensure data integrity to obtain accurate and trustworthy insights. Data…
stackabuse.com
Find duplicate rows in a Dataframe based on all or selected columns – GeeksforGeeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and…
www.geeksforgeeks.or
Pandas DataFrame duplicated() Method
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering…
www.w3schools.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

