


Enhancing The Robustness of Regression Model with Time-Series Analysis— Part 2
Last Updated on November 5, 2023 by Editorial Team
Author(s): Mirza Anandita
Originally published on Towards AI.
Enhancing The Robustness of Regression Model with Time-Series Analysis— Part 2
Previously…
Welcome to the second segment of this article!
In Part 1, we successfully managed to build a time-series model, specifically by using SARIMA (Seasonal Autoregressive Integrated Moving Average). Moreover, we evaluated the model that we built by performing a visual examination and assessing its mean absolute error (MAE).
Enhancing The Robustness of Regression Model with Time-Series Analysis — Part 1
In this story, we demonstrate how incorporating time-series analysis into linear regression can improve the model’s…
pub.towardsai.net
(For the complete codes of the end-to-end processes of this analysis, from data extraction to building regression models, feel free to check my GitHub repositories here)
As the title suggests, this article does not stop at time-series analysis. In the second part, we will move our focus to building regression models on how to predict Singapore’s HDB prices. Moreover, we will utilise the information from our time-series model as regression features to strengthen our regression’s predictive power.
With that being said, before we get into that part, let’s get back to our clean dataset and perform some feature engineering.
cleandata.head()

Feature Engineering
Feature engineering is another crucial phase in building predictive models. It is the process where we modify existing features or create new ones. The primary goal of feature engineering is to convert our data into a format that can be readily digested by our models. In essence, feature engineering forms a fundamental building block for our predictive models.
The way we perform feature engineering depends on the data types. Consequently, in our case, the initial step in performing feature engineering is to group our features into three groups: categorical features, temporal features, and numerical features.
Categorical Features
Based on our analysis of categorical features, it is evident that ‘flat_type’ and ‘storey_range’ exhibit ordinal characteristics. Although ordinal features possess natural order, it is important to note that the numerical differences between classes do not necessarily carry specific information. Interestingly, when we examine ‘flat_type’ and ‘storey_range’ in conjunction with ‘resale_price’, we observe nearly linear relationships.


Therefore, we can potentially simplify our predictive model by converting these ordinal features into numerical ones by using ordinal encoder. This transformation helps in removing unnecessary complexities within the model, while at the same time retaining important information.
np.sort(cleandata['flat_type'].unique())

np.sort(cleandata['storey_range'].unique())

Temporal Features
Temporal features are a group of features related to time-series data. These features can take the form of either date time, numerical, or categorical data. In the previous segment, specifically in the preprocessing stage, we created new features ‘resale_year’ and ‘resale_month’ from ‘resale_date’. Unlike ‘flat_type’ and ‘storey_range’, we found out that ‘resale_month’, which is also ordinal, does not have linear relationship with ‘resale_price’. Instead, ‘resale_month’ represents the seasonality aspect of our dataset. Hence, we need to convert ‘resale_month’ from numerical to categorical. From ‘resale_month’, we also created the new feature ‘resale_quarter’.
Other temporal features are the new features that we obtain from time-series analysis. Those features are forecast, trend, and lagged variables. For features forecast and trend, we can obtain them directly from our SARIMA model. For lagged variables, we created them from the forecast. Although the optimum number of lagged variables is three, based on the ARIMA parameter p = 3, we opted to create four lagged variables. By adding an extra variable, we aim to examine how this adjustment affects the behaviour of our regression model.
With new temporal features in hand, we could then seamlessly integrate those features into the cleaned dataset.
Numerical Features
The numerical features are in good shape. Therefore, they do not need to undergo any modification.
Feature Selection
After successfully performing feature engineering, we renamed our dataset to newdata. After obtaining newdata, the next step is to select the most relevant features that will go into our model.
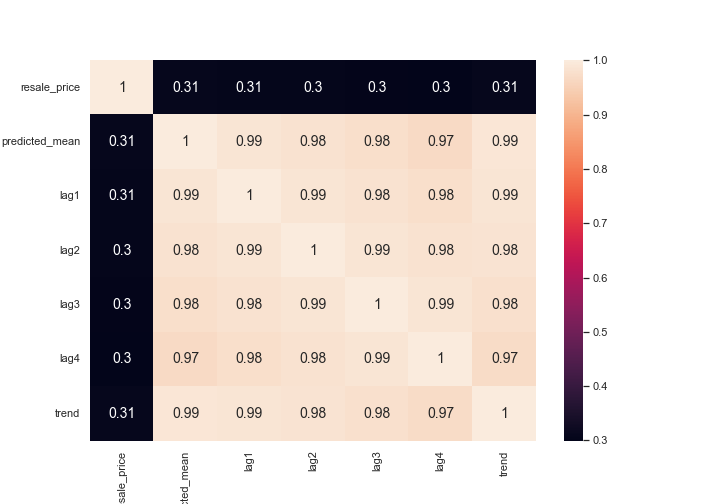
First, we group the numerical columns in our dataset together and run a correlation test. With this test, we can perform selection in two steps. The first one is comparing the features with the target, in this case ‘resale_price’.
From the heatmap below, we observe that the ‘resale_price’ has some degree of relationships with these numerical features, from a moderate relationship to a strong relationship. With that said, we also observe that some features have strong relationships with each other, indicating multicollinearity.
We know that ‘remaining_lease’ is a function of ‘lease_commence_year’. Hence, we can just remove one of these features. So, we removed ‘remaining_lease’. Moreover, we also observe that ‘floor_area_sqm’ and ‘flat_type’ are very strongly correlated, so we can remove ‘flat_type’ from the dataset.

Meanwhile, for our temporal features obtained from SARIMA, all of them are moderately correlated with the target. Additionally, all of them also exhibit multicollinearity between each other. With that said, we will not remove any of them at this point because we would like to know the combination of these features that works best in our regression model.
Meanwhile, for the categorical features, we use a more straightforward approach. From the image below, we see that ‘block’ and ‘street_name’ have extremely large number of unique classes, at 2671 and 565, respectively. It should be noted that categorical features that contain very large number of classes tend to add complexity to the model and are very prone to cause overfitting. Hence, we decide to drop these features.
cat = newdata.select_dtypes(exclude = 'number') #categorical/qualitative
for i, column in enumerate(cat.columns):
print(f'{column}'.title(), ': contains', cat[column].nunique(), 'values')

Once we have decided which features go into the regression model, we can now proceed to the next phase, building regression model.
Linear Regression
In machine learning, linear regression is a type supervised learning technique which goal is to predict the value of dependent variable based on its relationship with one or more independent variables. A key characteristic of linear regression is that the dependent variable, also called target, consists of continuous numerical values, while the independent variables, also known as features, can consist of numerical values or categorical values.
In our HDB case, we build linear regression model to predict the values of ‘resale_price’ based on its relationship with the features (‘floor_area_sqm’, ‘storey_range’, etc). To achieve a robust predictive model, first we need to build a baseline model. A baseline model is an essential starting point and a benchmark of how a model should perform and how it can be improved.
Baseline Model
As we all know, our goal is to see how combining time-series analysis helps to improve regression predictions. Subsequently, we create a baseline model that does not include temporal components, apart from those inherent in the raw dataset, which, in our case, include ‘resale_date’ and its direct derivatives, i.e. ‘resale_year’, ‘resale_month’, and ‘resale_quarter’. Hence, with the baseline model, we essentially create a scenario where we rely only on conventional linear regression.
Below is the combination of features and target that is used in our baseline model:
feat.head()

Model Building
It should be noted that because our dataset contains categorical features, we need to create dummy variables. In our case, we created dummy variables using one-hot encoding from Pandas.
As observed in the screenshot below, the number of features increase from 9 to a whopping 62, thanks to the creation of dummy variables.
dummies = pd.get_dummies(feat, drop_first= True, prefix_sep= '--')
dummies.head()

Following the creation of dummy variables, our next step is to partition the data into training and testing datasets. The splitting criterion used is the same as that used in time-series analysis, where the last 12 months form the testing set, while the preceding ones become the training set. In our specific case, this split results in a roughly 20:80 ratio of testing and training datasets. After partitioning the data, we could then build the model.
(In this analysis, we will not get into the details such as the regression coefficients or the statistical significance of each feature. However, for the complete summary of the regression model, you may check it out in my GitHub repositories.)
import statsmodels.api as sm
LinearRegression = sm.OLS(y_train, sm.add_constant(X_train)).fit()
Model Evaluation
Like we did in the time-series analysis section, to assess the performance of our regression model, we will employ two approaches — metric evaluation and visual evaluation. These two approaches work hand-in-hand to provide us with a thorough understanding of the model’s effectiveness.
To start the evaluation, what we need to assess is the residual plot of the regression model to examine the model’s homoscedasticity. First, we assess the residuals of the training dataset. As observed from the image below, we can see that in the lower price range, the actual data is scattered around the regression line quite evenly. However, as the price increases, the actual data scatters less evenly from the regression line. On the other hand, the histogram of the residuals follows the bell shape of a normal distribution with a mean close to zero, standing at -1.13e-11 after standardisation.

Additionally, the findings gained from the testing dataset are even less promising. As observed from the image below, we can tell that the actual data diverges even more from the regression line as the price increases. Furthermore, the histogram, although following the bell shape of normal distribution, is not centered close to zero, standing at -0.73 after standardisation.

Meanwhile, the key metrics we use to evaluate the regression model’s effectiveness are the adjusted R-squared, the mean absolute error (MAE) of training dataset, and MAE of testing dataset. These metrics are essential in measuring the model’s accuracy and its ability to generalise.
The values of those metrics are as follow:
- adjusted R-squared: 86.19%
The value of adjusted R-squared provides a measure of how well our predictive model can explain the variance in our data while penalising for the model’s complexity. In practical terms, it signifies how well the independent variables (features) in our model can explain the values of the dependent variable (target). An adjusted R-squared value of 86.19% can be considered a high value, considering what we are trying to model is housing prices, which can be complex to predict as it inherently involves human behaviour. A higher adjusted R-squared value (closer to 100%) in a regression model is typically a desirable characteristic.
- MAE of Training Dataset: S$47,453
- MAE of Testing Dataset: S$59,158
Meanwhile, for the values of MAE’s, as we did in time-series analysis, we need to compare them with the mean of monthly average prices, which is S$483,783. This means that the MAE values range from 9.8% to 12.2% of the mean of monthly average prices. Although these values are relatively small compared to the mean of monthly average prices, it would be better if we could reduce these error values even more.
Another angle to assess the model is to examine how well our regression can make time-series predictions. Hence, we generate plots that visualise monthly average prices from the actual dataset, training predictions, and testing predictions.

Upon examination of the graph above, we can uncover some important insights. It is evident that our baseline model can capture seasonality fairly well. However, the model apparently faces challenges capturing trend. It is evident that the training predictions (green line) frequently deviate quite far from the actual values, as indicated by the green shaded areas. The testing prediction (purple line) exhibits even larger errors, as shown in the purple shaded area, further suggesting that the model has difficulty capturing trend.
All in all, our comprehensive assessment, which encompasses the visual and metric evaluation, suggests the need for enhancements to the current model.
Improved Model
After extensive experiments using different scenarios with various combinations of features and data transformation, we have finally come up with an enhanced model. The new model should have improved robustness. However, the model, at the same time, should avoid unnecessary complexity so as to maintain interpretability.
That better model involves the incorporation of certain features obtained from time-series analysis using SARIMA, which are the trend and the third lag. Moreover, the model could perform more robustly by employing data transformation on the target (‘resale_price’) using Box-Cox transformation.
feat.head()

Model Building
In the process of building the improved model, we employ the same treatments as we did for the baseline model. By conducting the same steps, we can effectively compare the performance of the improved model to that of the baseline. The only notable difference is that the target of the improved model needs to undergo reverse transformation so as to return it to its original unit.
Model Evaluation
Just like we did for the baseline model, the first thing we assess in the improved model is the residuals. It should be noted that we can not compare the values in the residual analysis of the improved model with those of the baseline since each model has different unit for its target unless we employ standardisation on the residuals.

As observed in the regression plot above, we can tell that the improved model results in a more evenly scattered residuals than those of the baseline model. This finding suggests an improvement of the robustness of the model. Furthermore, if we refer to the testing dataset, the resulting regression plot, shown below, also exhibits an evenly scattered data, suggesting homoscedasticity. This is also an indication that we are on the right track!

Meanwhile, the values of the evaluation metrics are as follows:
- adjusted R-squared: 89.61%
- MAE of training dataset: S$40,114
- MAE of testing dataset: S$42,432
The value of the adjusted R-squared of the improved model is higher than that of the baseline. Meanwhile, the values of MAE of the training dataset and the testing dataset from the improved model is smaller than those of the baseline. This changes further indicate model improvement.
And finally, we would like to check out the time-series aspect of the improved model. From the graph below, it is evident that our improved model exhibits significantly smaller gaps between the actual values and the predicted values than the baseline model does, as indicated in the green and purple shaded areas.

Metrics Comparison
To make the comparison easier, I have recapped the metrics into these tables:


By comparing the MAE values of the baseline model with those of the improved model as shown on the tables, we can tell that the evaluation metrics, especially the mean absolute errors, of the second model are greatly improved by the incorporation of time-series into the regression model.
That’s kinda cool. So What?
We have finally succeeded in building a linear regression model that can capture the time-series nature of the data by incorporating SARIMA. With that being said, one might start asking the million dollar questions — Why does it even matter? How can we make use of the predictive model in real-world situations?
Well, one of the main uses of predictive models is to empower data-driven decision making. In a world full of information, predictive modelling helps us to convert information that comes from historical data into predictions of the future, which can act as actionable insights.
In our specific case, one of the direct applications of predictive modelling is to help HDB flat owners in making informed decisions on setting the optimal pricing for their properties, should they wish to sell their units. Setting the right price is crucial because underpricing can result in revenue loss, while overpricing may deter potential buyers.
With that being said, this model has its own limitation. In real-world situations, one of the main issues of making time-series forecasting is the declining reliability of models over time. Typically, when we make predictions further in the future, the resulting errors get larger, making our predictions less accurate. This is especially true in a situation that involves human behaviour, such as predicting the future prices of houses.
Therefore, this model is best used within a short period of time, such as 6 to 12 months into the future. After that period, it is better to revise the model by renewing the training data.
Key Takeaways
- One of the most basic machine learning techniques, linear regression, can be made more robust by combining it with classical time-series analysis technique such as SARIMA.
- HDB flat owners can leverage this model to aid them in setting the right prices, should they wish to sell their units.
- Due to its limitations, this model should be used within short period of time, such as 6 months or 12 months
- If this model is intended to be used for longer period, it is important to renew the training data periodically.
Finally, thank you very much for reading till the end! I hope you find my writing useful and inspiring.
Further Reading:
[1] M. Badole, Mastering Multiple Linear Regression: A Comprehensive Guide, 2021. [Online]. Available: https://www.analyticsvidhya.com/blog/2021/05/multiple-linear-regression-using-python-and-scikit-learn/ [Accessed: October 30th, 2023]
[2] Geeks for Geeks, Linear Regression in Python using Statsmodels, 2022. [Online]. Available: https://www.geeksforgeeks.org/linear-regression-in-python-using-statsmodels/ [Accessed: October 30th, 2023]
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

