



AWS S3 Read Write Operations Using the Pandas’ API
Last Updated on January 25, 2021 by Editorial Team
Author(s): Vivek Chaudhary
Programming
AWS S3 Read Write Operations Using the Pandas API
The Objective of this blog is to build an understanding of basic Read and Write operations on Amazon Web Storage Service “S3”. To be more specific, read a CSV file using Pandas and write the DataFrame to AWS S3 bucket and in vice versa operation read the same file from S3 bucket using Pandas API.
1. Prerequisite libraries
import boto3
import pandas as pd
import io
2. Read a CSV file using pandas
emp_df=pd.read_csv(r’D:\python_coding\GitLearn\python_ETL\emp.dat’)
emp_df.head(10)
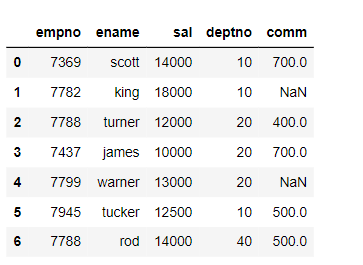
3. Write the Pandas DataFrame to AWS S3
from io import StringIO
REGION = ‘us-east-2’
ACCESS_KEY_ID = xxxxxxxxxxxxx’
SECRET_ACCESS_KEY = ‘xxxxxxxxxxxxxxxx’
BUCKET_NAME = ‘pysparkcsvs3’
FileName=’pysparks3/emp.csv’
csv_buffer=StringIO()
emp_df.to_csv(csv_buffer, index=False)
s3csv = boto3.client(‘s3’,
region_name = REGION,
aws_access_key_id = ACCESS_KEY_ID,
aws_secret_access_key = SECRET_ACCESS_KEY
)
response=s3csv.put_object(Body=csv_buffer.getvalue(),
Bucket=BUCKET_NAME,
Key=FileName)
As per Boto3 documentation: “Boto is the Amazon Web Services (AWS) SDK for Python. It enables Python developers to create, configure, and manage AWS services, such as EC2 and S3.”
StringIO: Is an in-memory file-like object. StringIO provides a convenient means of working with text in memory using the file API (read, write. etc.). This object can be used as input or output to the functions that expect a standard file object. When the StringIO object is created it is initialized by passing a string to the constructor. If no string is passed the StringIO will start empty.
getvalue() method returns the entire content of the file.
Let’s check if the file is available on AWS S3 bucket “pysparkcsvs3”
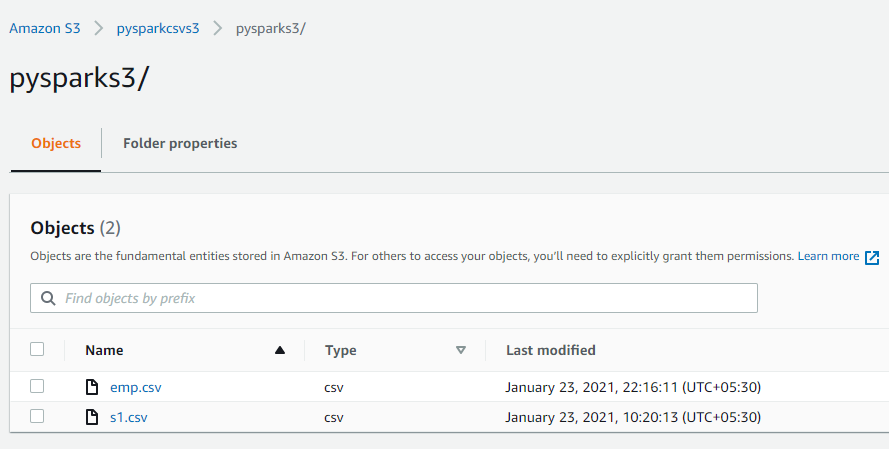
csv file successfully uploaded to S3 bucket.
4. Read the AWS S3 file to Pandas DataFrame
REGION = ‘us-east-2’
ACCESS_KEY_ID = ‘xxxxxxxxx’
SECRET_ACCESS_KEY = ‘xxxxxxxxx’
BUCKET_NAME = ‘pysparkcsvs3’
KEY = ‘pysparks3/emp.csv’ # file path in S3
s3c = boto3.client(‘s3’,
region_name = REGION,
aws_access_key_id = ACCESS_KEY_ID,
aws_secret_access_key = SECRET_ACCESS_KEY)
obj = s3c.get_object(Bucket= BUCKET_NAME , Key = KEY)
emp_df = pd.read_csv(io.BytesIO(obj[‘Body’].read()), encoding='utf8')
emp_df.head(5)
obj is the HTTP response in dictionary format, refer below.

get_object() retrieves objects from Amazon S3 buckets. To get objects user must have read access.
io.BytesIO() data can be kept as bytes in an in-memory buffer when we use the io module’s Byte IO operations.
Verify the data retrieved from S3.
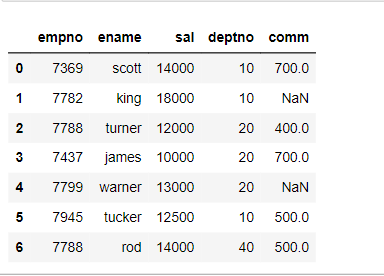
Data retrieved from CSV file present in the AWS S3 bucket looks good and string-byte conversion is successfully done.
Summary:
· Pandas API connectivity with AWS S3
· Read and Write Pandas DataFrame to S3 Storage
· Boto3 for connectivity with S3
Thanks to all for reading my blog. Do share your views or feedback.
AWS S3 Read Write Operations Using the Pandas’ API was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts


Recent Posts




")

