



Analyzing The Presidential Debates
Last Updated on January 6, 2023 by Editorial Team
Author(s): Lawrence Alaso Krukrubo
Data Science
Exploring Sentiments, Key-Phrase-Extraction, and Inferences …
2020 has been one ‘hell-of-a-year’, and we’re about the eleventh month.
It’s that time again for Americans to take to the polls.
If you’ve lived long enough, you recognize the patterns…
Each opposing political side, shades the other, scandals and leaks may pop, shortcomings are magnified, critics make the news, promises are doled out ‘rather–convincingly’ and there’s an overwhelming sense of ‘nationality and togetherness’ touted by both sides…
But for the most part, we’re not buying the BS! And often, we simply choose the ‘lesser of the two evils’, because candidly the one is not significantly better than the other.
So today, I’m going to analyze the presidential debates of President Trump and Vice-President Biden…
Disclaimer:
The entire analysis is done by the Author, using scientific methods that do not assume faultlessness. This is a personal project devoid of any political affiliations, sentiments or undertones. The inferences expressed from this scientific process are entirely the Author’s, based on the data.
Intro:
Trump and Biden faced-off twice.
- The first debate was on September 29, 2020. It was moderated by Chris Wallace of Fox News
- The second debate was originally scheduled for October 15th, but was cancelled due to Trump’s bout of COVID19, and held a week later. After his ‘rather-theatrical-and-spectacular-recovery’. This debate was moderated by Kristen Welker of NBC News.

1. The Data:
After watching both debates, as a Data Professional, I got really curious, wondering, what I could learn from analyzing the responses of these two Contestants.
It’s possible I may find something interesting from digging a little deeper into the way they answered questions bordering on the lives of millions of Americans…
That was my only motivation ‘Curiosity’, so I set out looking for the data.
Luckily I stumbled on rev.com, they had up the entire debates so I employed my data skills, scraped it off the website to a Jupyter notebook. That was the easy part. The hard part was preparing the data for each specific format required by the different libraries and tools for my analysis.
I scraped the website with the method I defined below…
2. Gentlemen You Have Two Minutes:
If you watched the first debate, you’d have noticed it was a hard task for Chris to keep both men within the 2-minute limit. Trump made it particularly hard, and quite often, there were exchanges between Trump and Biden.
Let’s look at what the data says…
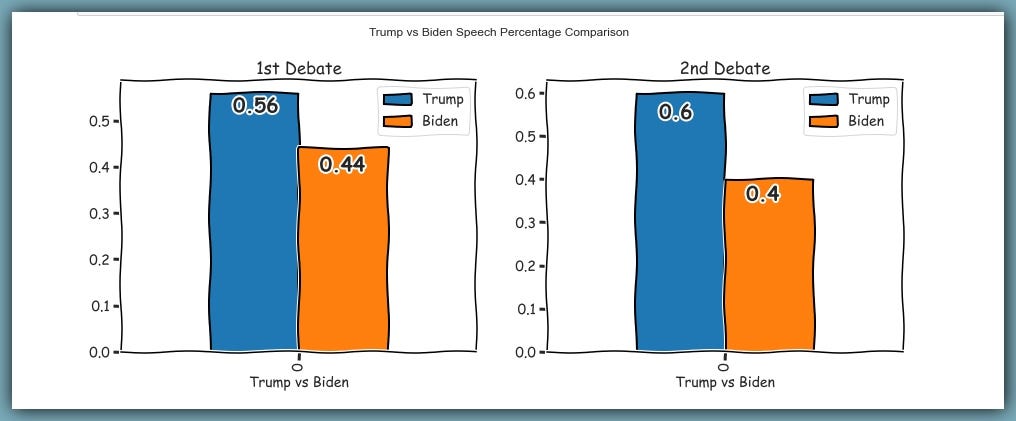
Of the total responses during the first debate, Trump had 56%, while Biden had 44% and it got worse for Joe during the second debate, as Trump dominated the responses further to 60%, leaving 40% to Joe.
Trump spoke 314 times in debate one and 193 times in debate two.
Biden spoke 250 times in debate one and 131 times in debate two.
Note to Self: Trump may not be the brightest, but he sure gets his voice heard…
2. Lexical-Diversity:
This simply means the cardinality or variety of words used in a conversation or document. In this case, it checks the number of unique words as a percentage of total words spoken by Trump and Biden.
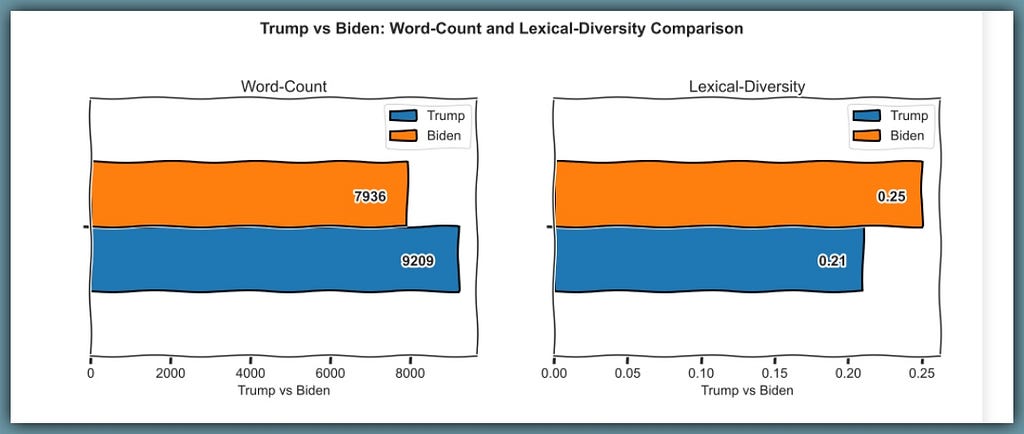
The data shows that Joe Biden is more creative with his words. He’s lexically-richer than Donald Trump, even though he consistently speaks fewer words than Trump.
Biden speaks 7,936 total words with 2,020 unique words and a lexical-diversity score of 25%
Trump speaks 9,209 total words with 1,894 unique words and a lexical-diversity score of 21%
Note to self: Biden may be few on words, but he’s got a heart of creativity…

3. TFIDF:
Term-Frequency-Inverse-Document-Frequency is arguably the most popular text processing algorithm. It tells us the importance of certain words to a document in comparison to other documents.
Simply put, TF-IDF shows the relative importance of a word or words to a document, given a collection of documents.
So, in this case, I choose to lemmatize the words of Trump and Biden, rather than stemming them…
def lemmatize_words(word_list):
lemma = WordNetLemmatizer()
lemmatized = [lemma.lemmatize(i) for i in word_list]
return lemmatized
Then I tokenize the words, remove punctuations and remove stopwords…
Then I build a simple TFIDF class to compute the TFIDF scores for both men.
So let’s see the words peculiar to Donald Trump using a word-cloud…

It’s pretty interesting or “uninteresting”, that Trump has on his top-10 TFIDF, words like ‘ago’, ‘built’, ‘Chris’ which is the Moderator’s name, as we can see he made it a hard task for Chris. Others are ‘disaster’, ‘called’, ‘cage’, ‘nobody’….
Let’s see for Joe Biden…

With words like ‘create’, ‘federal’, ‘serious’, ‘Americans’, ‘folk’, ‘situation’… It appears, Biden, put in more effort to his debate, than Team-Trump, in terms of structure and theme.
4. Some Questions Asked:

We have to commend Chris Wallace and Kristen Welker for being great moderators during the debates.
In the first debate, Chris asked some interesting questions, some of which bordered on…
- Supreme Court
- Obama-Care
- Economy
- Race / Justice
- Law Enforcement
- Election Integrity
- COVID
And during the second debate, Kristen held it down with questions on…
- COVID
- National-Security
- America / American-Families
- Minimum-Wage
- Immigration
- Race / Black-Lives-Matter
- Leadership
5. Some Answers and Inferences:

In this section, I shall analyze Trump’s and Biden’s responses to questions on three important topics:-
- Jobs, Wages and Taxes
- Racism
- The US Economy
The analysis for this section is quite interesting, involving a few libraries and tools
- For Sentiments-Analysis: AzureML Text-Analytics-Client SDK for python
- For Key-Phrase Extraction: AzureML Text-Analytics-Client SDK for python
- For Parts-Of-Speech-Tagging: spaCY
- For Visualization: Pywaffle, Matplotlib, Seaborn
After signing up on the Microsoft azureML portal and obtaining my key and endpoints, I created two methods for sentiments analysis and key-phrase extraction.
Next, I define the method for extracting the Parts-Of-Speech(POS) tags, using the spaCY library. This is really important in understanding how Trump and Biden often construct their sentences.
At this point, I’ve defined my work structure, now I need a couple of helper functions to process the debates into required formats and to find sentences that match my queries.
The first helper function is a search function. Such that given query-words like ‘Jobs’, ‘wages’, it would search through Trump’s and Biden’s corpus respectively, to extract sentences containing these query words…
The others are a function to convert the sentiments received from the AzureML Client to a DataFrame and another to apply the above methods together on a corpus to return a DataFrame with all sentiments and key-phrases intact plus a dictionary of overall sentiments scores.
With just a couple of extra plotting functions, we’re good to go!
A. Trump and Biden on Jobs/Wages/Taxes:
Trump responds with 93 sentences with an overall sentiment score of 21% positive, 72% negative and 7% neutral.
Biden responds with 127 sentences with an overall sentiment score of 33% positive, 60.3% negative and 6.7% neutral.
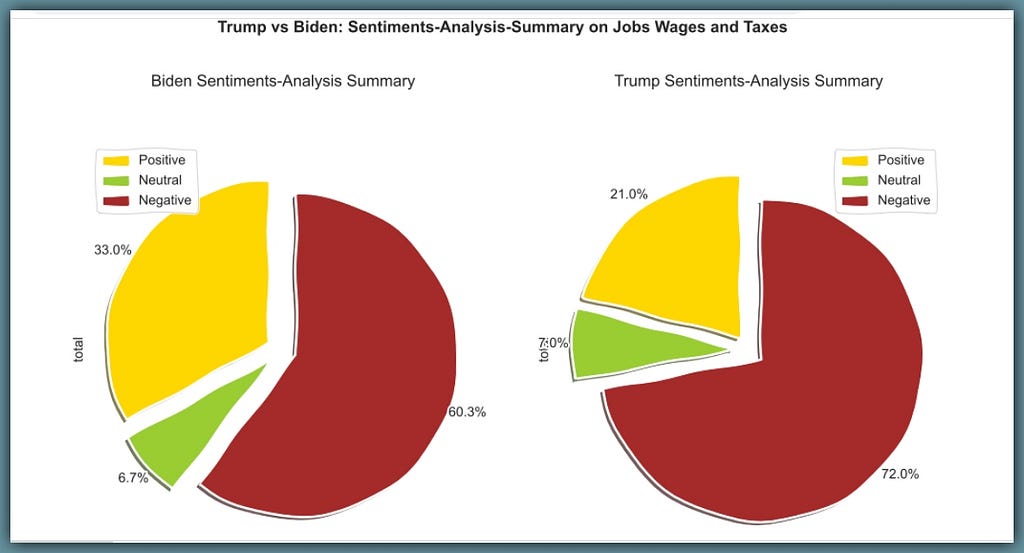
In both Pie-charts above, we can see the huge red portions indicating negative sentiments.
A2: Note that in a debate, negative sentiments should never be taken at face value, but should be explored to understand the context. This can be done by exploring the sentences and key-phrases extracted. For example, Biden may start a sentence by criticizing Trump’s approach severely, inorder to buttress his point. But doing so will cause the sentiments-analysis-client to record that sentence as overly negative. Therefore, negative-sentiments may only be taken at face-value in a review/feedback session, where negativity may indicate dissatisfaction or unhappy customers.
Given A2 above, Trump’s sentiments score is still kinda unexpected…We would expect him to paint a good picture of the work he’s been doing if he believes he’s been doing good work. I mean, it’s expected for Biden to criticize Trump, but since Trump is the sitting President, in charge of the present Government, it’s expected that his responses be more positive.
Let’s see a word-cloud of Trumps key-phrases on Jobs/Wages/Taxes

Trump talks about “Country, job, tax, companies, taxes, depression”…
Let’s see a few of his positive-sentiments responses on Jobs/Taxes/Wages…
Trump talks about ‘helping small business by raising the minimum wage’, plus ‘being on the road to success’, amongst other things. He also responds to the question of paying $750 taxes as untrue, saying he paid millions in taxes. When challenged by Biden for exploiting the tax-bill, he claimed the bill was passed by Biden and it only gave “certain individuals” the privileges for depreciation and tax credits.
And for Trump’s negative-sentiment responses…
For the negatives, Trump talks about people dying, committing suicide and losing their jobs. Saying there are depression, alcohol and drugs at a level nobody’s seen before, and that’s why he wants to open up the schools and economy.
Let’s see the word-cloud of Biden’s key-phrases on Jobs/Wages/Taxes

Biden talks about “tax, job, people, millions, fact, economy, significant”…
Let’s see a few of Biden’s positive-sentiments replies on Jobs/Taxes/Wages…
Biden talks about creating millions of jobs, investing in 50,000 charging stations on highways so as to own the electric car market of the future. He talks about taking 4 million existing buildings and 2 million existing homes and retrofit them so they don’t leak as much energy, saving hundreds of millions of barrels of oil in the process and creating millions of jobs…
On Biden’s negative sentiments responses…
Here he criticizes the Trump administration saying people who have lost their jobs have been those on the front-lines. Also, that Trump has almost half the states in America with a significant increase in COVID deaths, because he rushed to open the economy…
Generally, Biden’s negative sentiments scores come from his criticism of Trumps administration, which is expected. Trump’s negative sentiments are a mix of sour remarks and unfriendly remarks at Biden, Obama and Hillary Clinton… He called Hillary crooked and a disgrace.
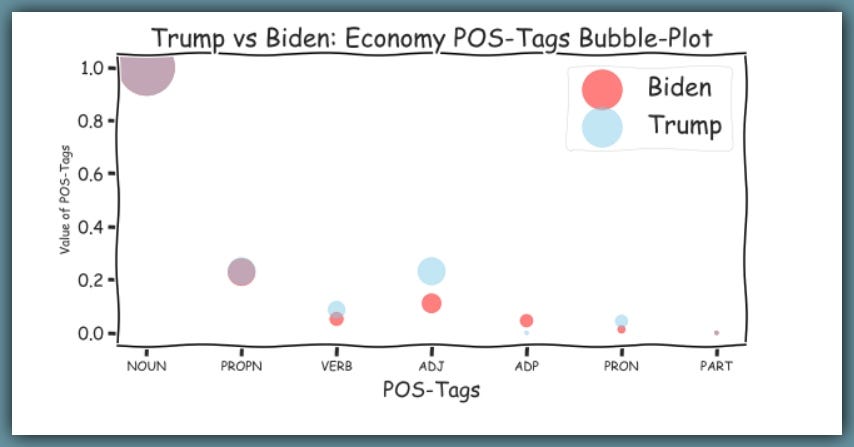
Let’s see the Parts-Of-Speech tags on for both Trump and Biden.
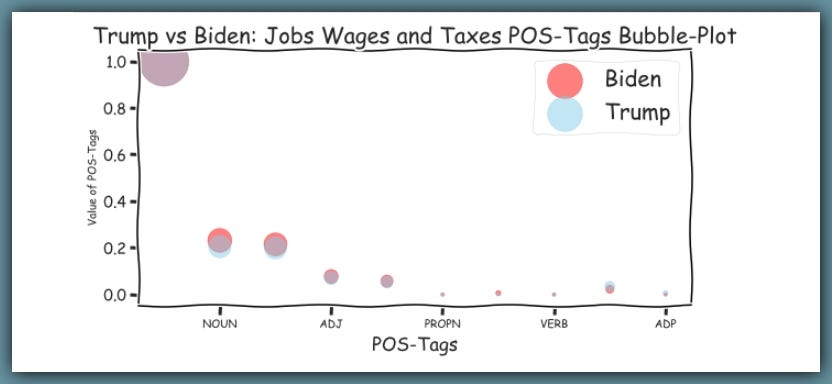
Bigger bubbles represent the most frequent part-of-speech tags used.
B. Trump and Biden on Racism:
Trump never said the word ‘Racism’ during the debates. He called Biden a Racist though and said people accuse him(Trump) of being a Racist, but they’re wrong…
Trump responds with 47 sentences with an overall sentiment score of 10% positive, 87% negative and 3% neutral.
Biden responds with 89 sentences with an overall sentiment score of 27.5% positive, 67% negative and 5.5% neutral.
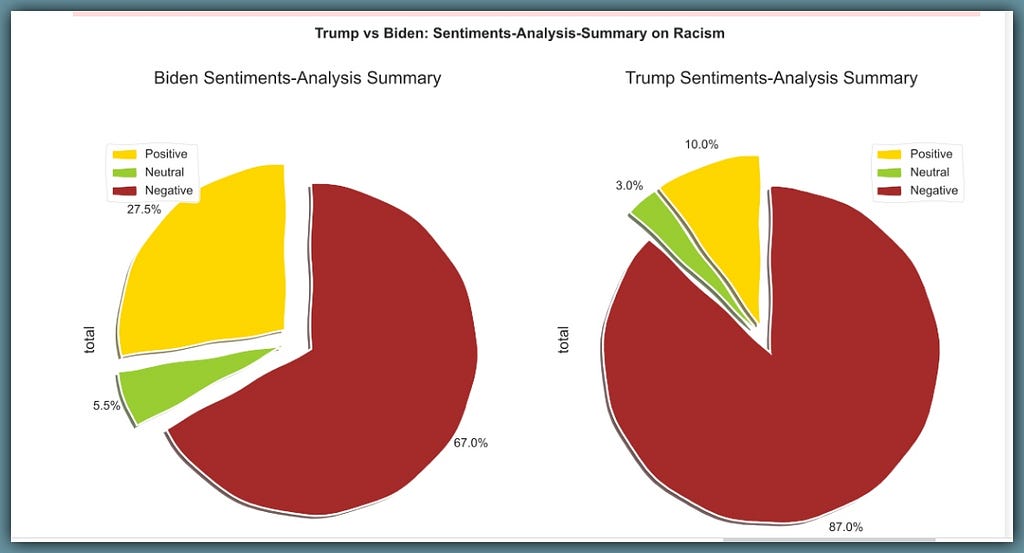
Trump’s sentences again appear overly negative at 87%, while Biden’s are negative at 67%
Let’s see a word-cloud of Trumps Key-phrases used in describing Racism
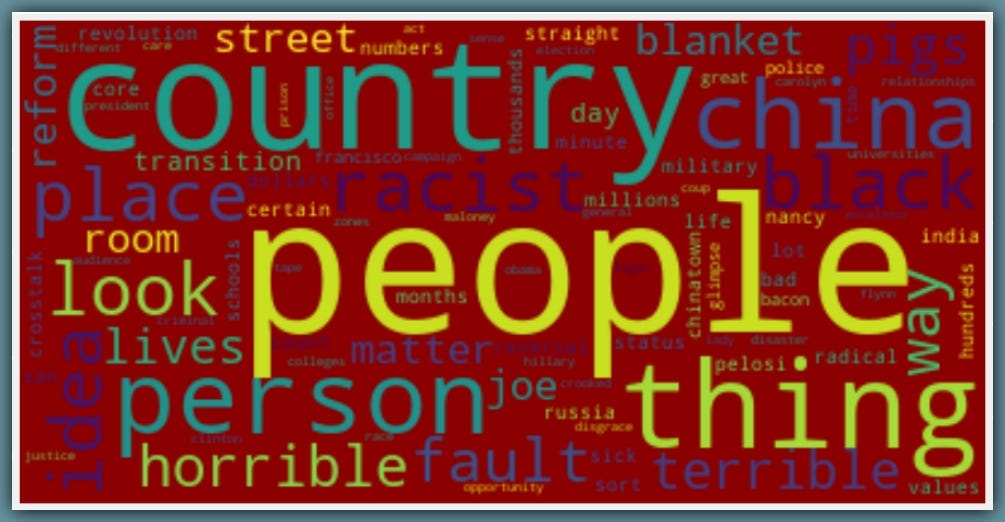
Trump uses terms like ‘people, person, horrible, country, china, black, racist, terrible..’
For some positive-sentiments responses from Trump…
And for some negative-sentiments responses from Trump…
Trump calls Biden a racist, calls Hillary Clinton crooked and says the first time he heard about Black-Lives-Matter, they were chanting ‘pigs in a blanket’ and ‘fry them like bacon’, at the police and Trump says, ‘that’s a horrible thing’…
Then Trump goes on to say he’s the least racist person in the room and that he’s been taking care of Black colleges and universities.
Note to self: Trump finds it hard to address racism constructively. Often he thinks it’s about him, he doesn’t realize it’s about the entire American system
Let’s see the Racism word-cloud for Joe Biden…
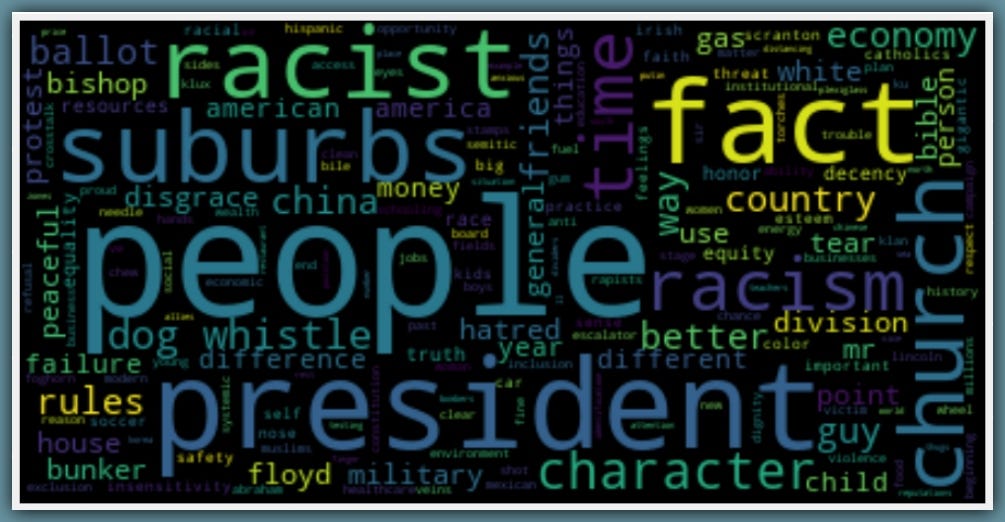
Here we have Biden using words like ‘people, president, character, racist, racism, suburbs‘… To tackle racism.
Some of Biden’s positive-sentiments responses are…
On his positives, Biden talks about how most people don’t wanna hurt nobody and how he’s going to provide for economic opportunities, better education, better health-care and education…
And while whipping negative sentiments, Biden talks like this…
Biden reminds Trump that when George Floyd was killed, he asked the military to use tear-gas on peaceful protesters at the White-house so that Trump could pose at the church with a Bible. Biden states there’s systemic racism in America, he calls Trump a racist and reminds him that it’s not 1950 no more…
Note to self: As a Blackman, I’m happy that Biden openly agrees that there’s systemic racism in America… This assertion is the only true route to a solution.
Now, let’s see the Parts-Of-Speech-Tags, for Trump and Biden on Racism…
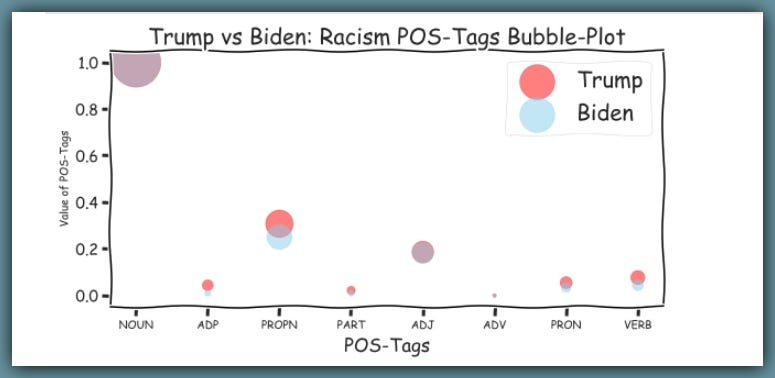
C. Trump and Biden on The US Economy:
Trump responds with 44 sentences with an overall sentiment score of 16% positive, 80% negative and 4% neutral.
Biden responds with 56 sentences with an overall sentiment score of 45% positive, 50% negative and 5% neutral.
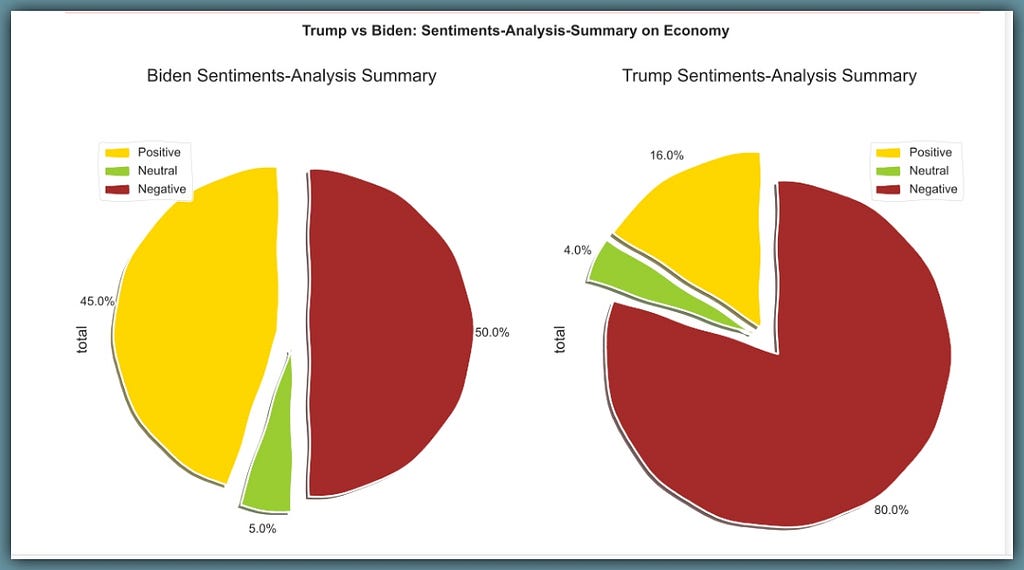
And for the ‘third-time-running’, Trump seems overly negative with his responses on The US Economy…
Let’s see a word-cloud of Trumps Key-phrases about the Economy

Trump uses terms like ‘greatest economy in history, country, china, administration, spike, massive, world…’
Let’s see some of Trump’s responses with positive-sentiments,
On his positives, Trump says Due to COVID he had to close ‘The greatest economy of the history of our country’. Which by the way is being built again and it’s going up so fast. He ends with saying they had the lowest unemployment numbers before the pandemic.
Let’s see some of Trump’s responses with negative-sentiments,
Trump talks about the negative effect of closing down the economy because of the ‘China-plague’. He accuses Biden of planning to shut down the economy again. He said if not for his efforts, there'd be 2.2 million dead Americans to the virus and not the current 220k…
Let’s see the word-cloud of Biden’s Key-phrases about the Economy.

Biden talks about ‘economy, jobs, fact, people, energy, covid, number, Putin…’
Let’s see some of his remarks with positive-sentiments about the Economy
Biden talks repeatedly about creating millions of new jobs by making sure the economy is being run, moved and motivated by clean energy. He talks specifically about curbing energy leaks and saving millions of barrels of oil, which leads to significantly new jobs.
On Biden’s negative-sentiments responses about the Economy…
From his negative-sentiment responses, Biden talks to the families who’ve lost loved ones to the pandemic. He challenges Trump that he can’t fix the economy except he first fixes the pandemic. He mentions systemic racism affecting the US economy. He accuses Trump of mismanaging the economy, stating the Obama administration handed him a booming economy which he’s blown.
Finally, for this section, let’s see the bubble-plot of the Parts-Of-Speech tags for Trump and Biden on The US Economy.
6. Bayesian Inference:
So, our task here is to find the conditional probability (P)of Trump and Biden mentioning the words we care most about, given the debates.
We will build a Naive-Bayes classifier from scratch and use it to tell the conditional likelihood of Trump and Biden saying the words we care most about.

This simply means that the Conditional P of event A, given event B is the Conditional P of event B, given event A, multiplied by the Marginal P of event A, all these divided by the Marginal P of event B (which is actually the Total P of event B occurring at all).
First, let’s define the prior, this is simply the P of Trump and Biden participating in the debates. I say it’s 50% each.
p_trump_speech = 0.5
p_biden_speech = 0.5
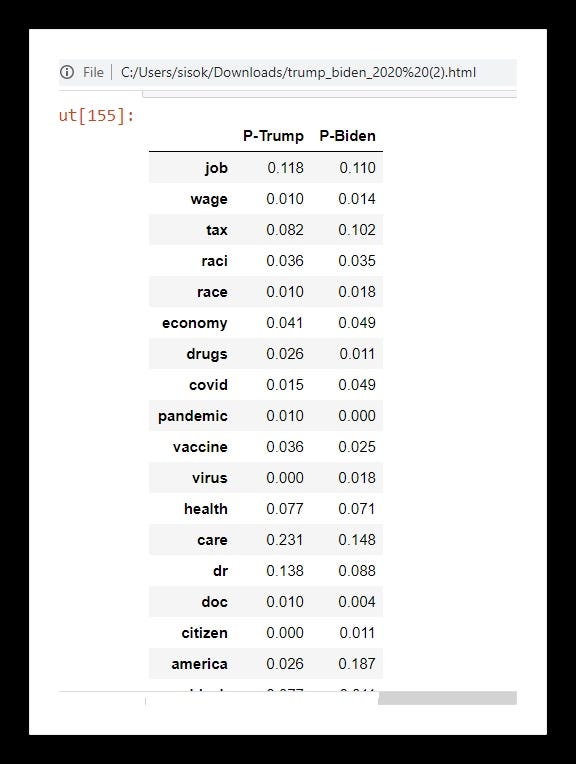
Now, I get a list of some of the words we care about (some may be stemmed)
['job','wage','tax','raci','race','economy','drugs','covid',
'pandemic','vaccine','virus','health','care','dr','doc','citizen',
'america','black','african','white','latin','hispanic','asian',
'minorit','immigra']
Next, I define a function that computes the individual conditional P of Trump and Biden saying each word, given the debates. It returns a DataFrame with these intact.
So I get the DataFrame, scale it up uniformly by multiplying each value by some factors of 10 and then I normalize the values and it looks like this…
Finally, I define a Bayes-Inference method for computing the conditional probability of Trump and Biden given these words.
So I get 46.5% for Trump and 53.5% for Biden
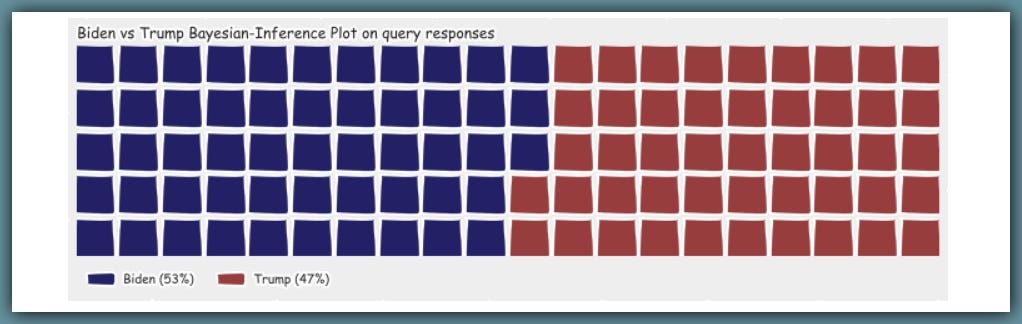
So from these debates and given the topics we care about, who’s more likely to discuss them… Hopefully, address them and proffer solutions? Bayes Rule says Biden is more likely, and the margin is tight 53.5% — 46.5% = 7% in favor of Joe Biden…
This is by no means a prediction of the result of the election nor a means to influence voter decisions, it’s just my opinion inferred solely from the Presidential debates.
But of course, we know there’s more to life, to America than just two debates.
God Bless America, God Bless Africa, God Bless The World…
Cheers!!
About Me:
Lawrence is a Data Specialist at Tech Layer, passionate about fair and explainable AI and Data Science. I believe that sharing knowledge and experiences is the best way to learn. I hold both the Data Science Professional and Advanced Data Science Professional certifications from IBM and the IBM Data Science Explainability badge. I have conducted several projects using ML and DL libraries, I love to code up my functions as much as possible. Finally, I never stop learning and experimenting and yes, I have written several highly recommended articles.
Feel free to find me on:-
Analyzing The Presidential Debates was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts


Recent Posts




")

