



Text Mining in Python: Steps and Examples
Last Updated on November 17, 2020 by Editorial Team
Author(s): Dhilip Subramanian

In today’s scenario, one way of people’s success is identified by how they are communicating and sharing information with others. That’s where the concepts of language come into the picture. However, there are many languages in the world. Each has many standards and alphabets, and the combination of these words arranged meaningfully resulted in the formation of a sentence. Each language has its own rules while developing these sentences, and these sets of rules are also known as grammar.

In today’s world, according to industry estimates, only 20 percent of the data is being generated in the structured format as we speak, as we tweet, as we send messages on WhatsApp, Email, Facebook, Instagram, or any text messages. And the majority of this data exists in the textual form, which is a highly unstructured format. In order to produce meaningful insights from the text data, then we need to follow a method called Text Analysis.
What is Text Mining?
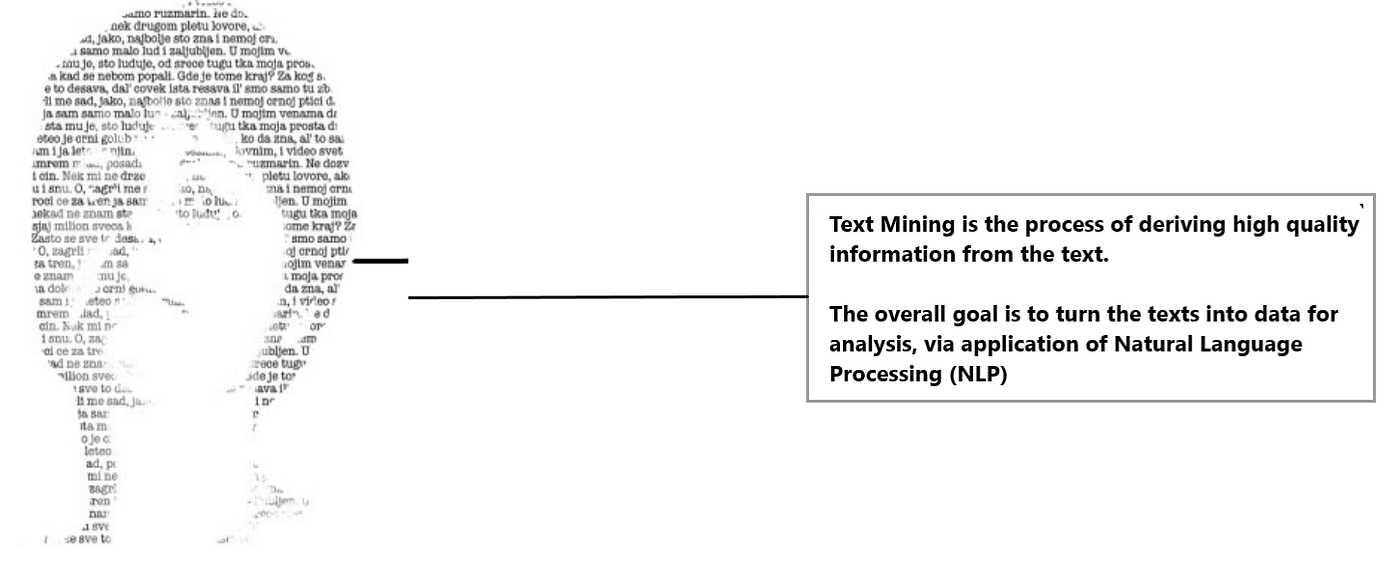
Text Mining is the process of deriving meaningful information from natural language text.
What is NLP?
Natural Language Processing(NLP) is a part of computer science and artificial intelligence which deals with human languages.
In other words, NLP is a component of text mining that performs a special kind of linguistic analysis that essentially helps a machine “read” text. It uses a different methodology to decipher the ambiguities in human language, including the following: automatic summarization, part-of-speech tagging, disambiguation, chunking, as well as disambiguation, and natural language understanding and recognition. We will see all the processes in a step-by-step manner using Python.

First, we need to install the NLTK library that is the natural language toolkit for building Python programs to work with human language data, and it also provides easy to use interface.
Terminologies in NLP
Tokenization
Tokenization is the first step in NLP. It is the process of breaking strings into tokens, which in turn are small structures or units. Tokenization involves three steps, which are breaking a complex sentence into words, understanding the importance of each word with respect to the sentence, and finally produce a structural description on an input sentence.
Code:
# Importing necessary library import pandas as pd import numpy as np import nltk import os import nltk.corpus# sample text for performing tokenization text = “In Brazil they drive on the right-hand side of the road. Brazil has a large coastline on the eastern side of South America"# importing word_tokenize from nltk from nltk.tokenize import word_tokenize# Passing the string text into word tokenize for breaking the sentences token = word_tokenize(text) token
Output
['In','Brazil','they','drive', 'on','the', 'right-hand', 'side', 'of', 'the', 'road', '.', 'Brazil', 'has', 'a', 'large', 'coastline', 'on', 'the', 'eastern', 'side', 'of', 'South', 'America']
From the above output, we can see the text split into tokens. Words, comma, punctuations are called tokens.
Finding frequency distinct in the text
Code 1
# finding the frequency distinct in the tokens
# Importing FreqDist library from nltk and passing token into FreqDist
from nltk.probability import FreqDist
fdist = FreqDist(token)
fdist
Output
FreqDist({'the': 3, 'Brazil': 2, 'on': 2, 'side': 2, 'of': 2, 'In': 1, 'they': 1, 'drive': 1, 'right-hand': 1, 'road': 1, ...})
‘the’ is found 3 times in the text, ‘Brazil’ is found 2 times in the text, etc.
Code 2
# To find the frequency of top 10 words
fdist1 = fdist.most_common(10)
fdist1
Output
[('the', 3),
('Brazil', 2),
('on', 2),
('side', 2),
('of', 2),
('In', 1),
('they', 1),
('drive', 1),
('right-hand', 1),
('road', 1)]
Stemming
Stemming usually refers to normalizing words into its base form or root form.

Here, we have words waited, waiting, and waits. Here the root word is ‘wait.’ There are two methods in Stemming, namely, Porter Stemming (removes common morphological and inflectional endings from words) and Lancaster Stemming (a more aggressive stemming algorithm).
Code 1
# Importing Porterstemmer from nltk library
# Checking for the word ‘giving’
from nltk.stem import PorterStemmer
pst = PorterStemmer()
pst.stem(“waiting”)
Output
'wait'
Code 2
# Checking for the list of words
stm = ["waited", "waiting", "waits"]
for word in stm :
print(word+ ":" +pst.stem(word))
Output
waited:wait
waiting:wait
waits:wait
Code 3
# Importing LancasterStemmer from nltk
from nltk.stem import LancasterStemmer
lst = LancasterStemmer()
stm = [“giving”, “given”, “given”, “gave”]
for word in stm :
print(word+ “:” +lst.stem(word))
Output
giving:giv
given:giv
given:giv
gave:gav
Lancaster is more aggressive than Porter stemmer.
Lemmatization
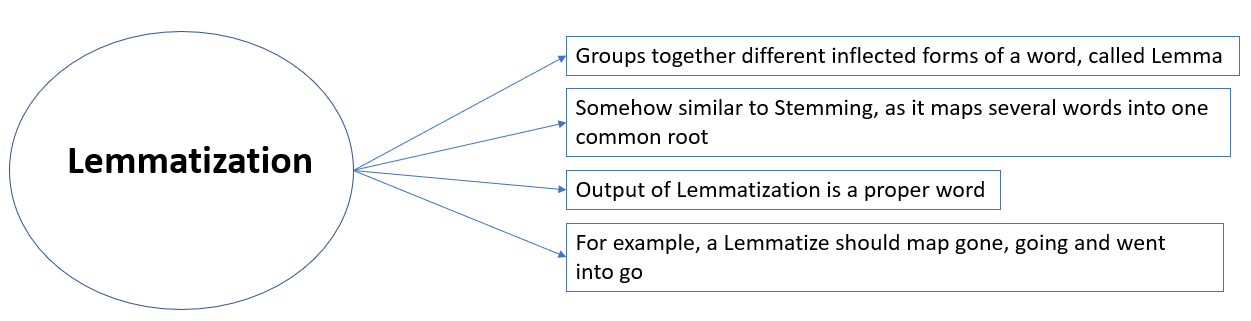
In simpler terms, it is the process of converting a word to its base form. The difference between stemming and lemmatization is, lemmatization considers the context and converts the word to its meaningful base form, whereas stemming just removes the last few characters, often leading to incorrect meanings and spelling errors.
For example, lemmatization would correctly identify the base form of ‘caring’ to ‘care,’ whereas stemming would cutoff the ‘ing’ part and convert it into a car.
Lemmatization can be implemented in python by using Wordnet Lemmatizer, Spacy Lemmatizer, TextBlob, Stanford CoreNLP
Code
# Importing Lemmatizer library from nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(“rocks :”, lemmatizer.lemmatize(“rocks”))
print(“corpora :”, lemmatizer.lemmatize(“corpora”))
Output
rocks : rock
corpora : corpus
Stop Words
“Stop words” are the most common words in a language like “the”, “a”, “at”, “for”, “above”, “on”, “is”, “all”. These words do not provide any meaning and are usually removed from texts. We can remove these stop words using nltk library.
Code
# importing stopwors from nltk library from nltk import word_tokenize from nltk.corpus import stopwords a = set(stopwords.words(‘english’))text = “Cristiano Ronaldo was born on February 5, 1985, in Funchal, Madeira, Portugal.” text1 = word_tokenize(text.lower()) print(text1)stopwords = [x for x in text1 if x not in a] print(stopwords)
Output
Output of text: ['cristiano', 'ronaldo', 'was', 'born', 'on', 'february', '5', ',', '1985', ',', 'in', 'funchal', ',', 'madeira', ',', 'portugal', '.']Output of stopwords: ['cristiano', 'ronaldo', 'born', 'february', '5', ',', '1985', ',', 'funchal', ',', 'madeira', ',', 'portugal', '.']
Part of speech tagging (POS)

Part-of-speech tagging is used to assign parts of speech to each word of a given text (such as nouns, verbs, pronouns, adverbs, conjunction, adjectives, interjection) based on its definition and its context. There are many tools available for POS taggers, and some of the widely used taggers are NLTK, Spacy, TextBlob, Standford CoreNLP, etc.
Code
text = “vote to choose a particular man or a group (party) to represent them in parliament”
#Tokenize the text
tex = word_tokenize(text)
for token in tex:
print(nltk.pos_tag([token]))
Output
[('vote', 'NN')]
[('to', 'TO')]
[('choose', 'NN')]
[('a', 'DT')]
[('particular', 'JJ')]
[('man', 'NN')]
[('or', 'CC')]
[('a', 'DT')]
[('group', 'NN')]
[('(', '(')]
[('party', 'NN')]
[(')', ')')]
[('to', 'TO')]
[('represent', 'NN')]
[('them', 'PRP')]
[('in', 'IN')]
[('parliament', 'NN')]
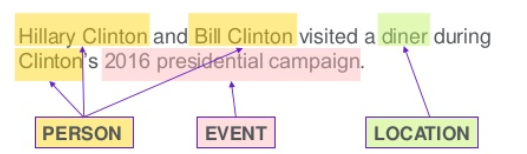
Named entity recognition
It is the process of detecting the named entities such as the person name, the location name, the company name, the quantities, and the monetary value.
Code
text = “Google’s CEO Sundar Pichai introduced the new Pixel at Minnesota Roi Centre Event”#importing chunk library from nltk from nltk import ne_chunk# tokenize and POS Tagging before doing chunk token = word_tokenize(text) tags = nltk.pos_tag(token) chunk = ne_chunk(tags) chunk
Output
Tree('S', [Tree('GPE', [('Google', 'NNP')]), ("'s", 'POS'), Tree('ORGANIZATION', [('CEO', 'NNP'), ('Sundar', 'NNP'), ('Pichai', 'NNP')]), ('introduced', 'VBD'), ('the', 'DT'), ('new', 'JJ'), ('Pixel', 'NNP'), ('at', 'IN'), Tree('ORGANIZATION', [('Minnesota', 'NNP'), ('Roi', 'NNP'), ('Centre', 'NNP')]), ('Event', 'NNP')])
Chunking
Chunking means picking up individual pieces of information and grouping them into bigger pieces. In the context of NLP and text mining, chunking means a grouping of words or tokens into chunks.

Code
text = “We saw the yellow dog” token = word_tokenize(text) tags = nltk.pos_tag(token)reg = “NP: {<DT>?<JJ>*<NN>}” a = nltk.RegexpParser(reg) result = a.parse(tags) print(result)
Output
(S We/PRP saw/VBD (NP the/DT yellow/JJ dog/NN))
This blog summarizes text preprocessing and covers the NLTK steps, including Tokenization, Stemming, Lemmatization, POS tagging, Named entity recognition, and Chunking.
Thanks for reading. Keep learning, and stay tuned for more!
You can also read this article on KDnuggets.
Reference:
Related posts
Popular posts

 for 2021")



Updates



Recent Posts




