



Understanding Pascal VOC and COCO Annotations for Object Detection
Last Updated on June 5, 2020 by Editorial Team
Author(s): Pushkar Pushp
Computer Vision
Introduction
In the previous blog, we created both COCO and Pascal VOC dataset for object detection and segmentation. So we are going to do a deep dive on these datasets.
Pascal VOC
PASCAL (Pattern Analysis, Statistical Modelling, and Computational Learning) is a Network of Excellence by the EU. They ran the Visual Object Challenge (VOC) from 2005 onwards till 2012.
The file structure obtained after annotations from VoTT is as below.
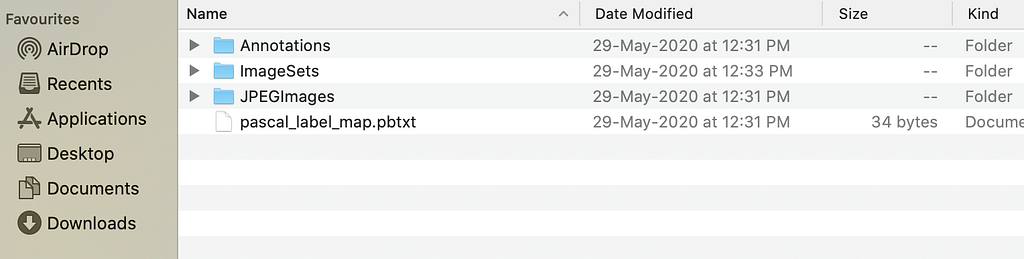
The four components are Annotations, ImageSets, JPEGImages, and pascal_label_map.pbxt.
We will come to annotations; at last, JPEGImages is the folder containing original images. ImageSets provides to txt file train and valid inside the main folder containing the list of images in train and valid.
The pascal_label_map.pbxt contains the id and name of the object to be detected.
pascal_label_map.pbxt
item {
id: 1
name: ‘cricketers’
}
The last and most important section is Annotations, annotations files are created for each image in the given folder.
The annotations are stored in an XML file, and let’s look into one sample XML file.
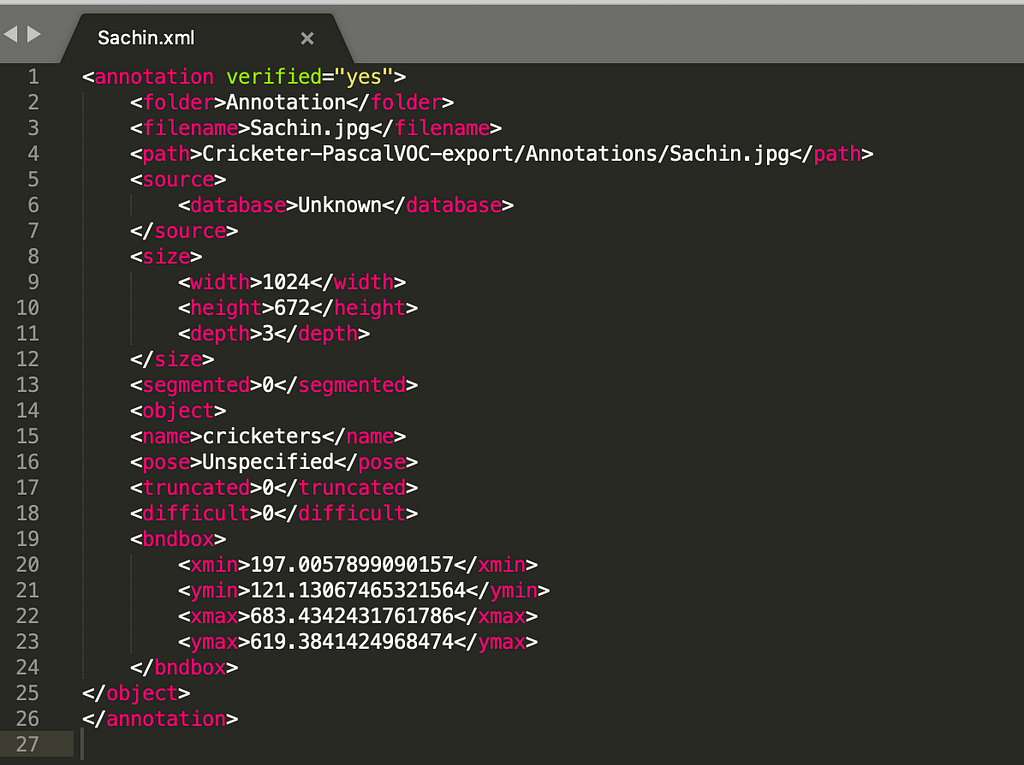
There are different components or tags corresponding to XML output.
folder: that contains images.
filename: the relative path of the image which is annotated.
path: an absolute path of the output file after annotations.
size: height, width in terms of pixels, the depth indicating the number of channels for RGB image depth is 3, for B/W it is 1.
object: contains name,pose ,truncated,difficult.
- name: contains the name of the object being annotated, in our case it is cricketers.
- pose: orientation left ,right ,etc.
- truncated: if objects extend beyond bounding box truncated is 1 else 0.
- difficult: if it is not evaluated difficult is 1 else 0.
bndbox: bounding box it consists of the top left-hand corner and bottom right-hand corner(xmin-top left, ymin-top left,xmax-bottom right, ymax-bottom right)
COCO
COCO is a common object in context. The dataset contains 91 objects types of 2.5 million labeled instances across 328,000 images.
COCO is used for object detection, segmentation, and captioning dataset.
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
COCO stores annotations in JSON format unlike XML format in Pascal VOC.
The official document of COCO states it has five object detection, keypoint detection, stuff segmentation, panoptic segmentation, and image captioning.

Basic Data structure of COCO annotations are the same for all five types. There is a single annotation for all images, different from Pascal VOC annotations.
Let’s have a closer look at the annotation file.
The four basic components are info, images, annotations, and license.
info: contains the standard information/description of the images.
images: all detail about each individual image as listed in the figure above.
license: consists of the license applicable to that image.
Here we will be focussing on Object Detection annotations.
Annotations to understand these lets first understand what are categories.
Categories contain a list of all images with a unique id and its supercategory, for instance, players supercategory will be cricketers and each cricketer will have a unique id.
"categories": [
{"supercategory": "cricketers","id": 1,"name": "Sachin"},
{"supercategory": "cricketers","id": 2,"name": "Stokes"},
{"supercategory": "umpire","id": 3,"name": "Bucknor"},
{"supercategory": "cricketers","id": 4,"name": "Waugh"},
{"supercategory": "umpire","id": 5,"name": "Taufel"},
]
The numbers of annotations will be equal to the total number of objects present entire image datasets.


The mask is converted into COCO annotation.
The annotation consists of segmentation,iscrowd,image_id,category_id,id,bbox,and area
[{'segmentation': [[236.0,616.5,610.5,...,613.5,233.0,612.5,236.0,616.5]],
'iscrowd': 0,
'image_id': 1,
'category_id': 1,
'id': 1,
'bbox': (199.5, 126.5, 474.0, 490.0),
'area': 103944.0}]
- segmentation: list of vertices of polygon for cluster run-length-encoded (RLE) is used .RLE stores repeating values by the number of times they repeat.
- iscrowd: 0 for a single object and 1 for a cluster of objects.
- image_id: unique id corresponding to the image in the dataset.
- category_id: corresponds to the category.
- id: unique id for each annotation.
- area: bounding box area in pixels.
- bbox: a list containing [top left x position, top left y position, width, height]
In the next blog, we read about various object detection techniques and harness both COCO as well as Pascal VOC data.
😊
Understanding Pascal VOC and COCO Annotations for Object Detection was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

