


")
The Strengths & Weaknesses of Face2Vec (FaceNet)
Last Updated on January 23, 2021 by Editorial Team
Author(s): Jacky Wong
Computer Vision
Face2Vec refers to the process of transforming faces to vectors, a process named vectorization that transforms objects/images/text into numerical representations (if you would like to learn more, read this).
Recently, I added Face2Vec to the VectorHub repository (an open-source repository I maintain to host and share ___2Vec models). Face2Vec is one of the most widely-used vectorizations in the world, forming the basis of a significant number of applications today, including social media filters, identification, and verification.
In this article, we explore FaceNet’s strengths and weaknesses — providing readers with an understanding of where the model performs well and not so well. From there, we go more technical into understanding FaceNet’s architecture and its implementation.
I recommend exploring this model on VectorHub and trying it out for yourself! You can try out the model in 3 lines of Python code and begin searching through your own dataset in less than 5 minutes.
Strengths & Weaknesses
Note to the reader: The strengths and weaknesses are comparing Face2Vec models using the VectorHub implementation. Results may vary from different implementations. A series of experiments were run using custom, random, and transformed images to test how this model performs practically. A lot of the initial faces were retrieved from a portion of the Celeb-A dataset (cited below — of approximately 5 000 images), which can be found in Tensorflow’s datasets modules. We use this as a baseline for exploring the effectiveness of the Face2Vec model that we implemented into VectorHub.
There are, however, a few weaknesses in our experimentation we would like to acknowledge. There are a number of areas that are still left to be explored (how differing races/genders can play a role in the facial image recognition and unless there are specific attributes in the dataset that allow us to explore these — identifying whether these are edge-cases for the Face2Vec implementation needs to be considered. The examples seen below are also hand-picked ones that best illustrate the concepts that were spoken but are reflective of a broader overall trend.
Strengths
- Able to identify similar faces through different facial expressions and angles

- Able to handle different lightings/transformations

- Able to identify the same faces despite having markings on the face

- Action shots where the faces can be highly different can still be matched! This means that photos taken during sports games where facial expressions can be significantly different from everyday expressions, the models are still able to identify similar individuals.

- Able to handle half of a face. Surprisingly — the model was able to even determine the individual correctly when half the face was cut off!

Weaknesses
- Unable to find good matches if the image is edited with words in front of it.

- If individuals are wearing eyewear, Face2Vec overfocused on similar eyewear.

- The model, however, could also be improved across different races and skin colors. Below is an example of the model performing subpar of one such instance.

Overall the model performed well in a number of areas and not so well in a few edge cases. However, I have no doubt that if the model was re-trained with a dataset that has more images with a larger variety of ethnicities, eyewear and distortions with larger representative capacity then it would perform better. If readers are aware of such models, feel free to let us know and we are happy to add these models to VectorHub (or submit your own pull request and we will review it!).
In the following sections, we explore details about how it is performed and the two-stage implementation process that can be found in our VectorHub repository.
Understanding FaceNet
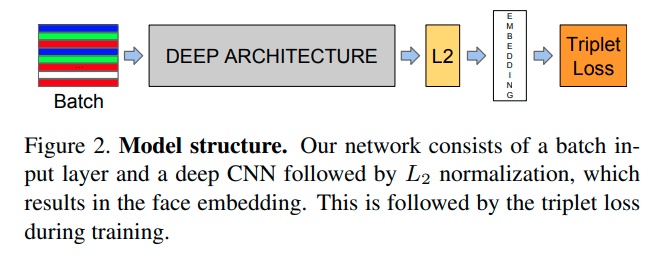
The FaceNet architecture is simple (a standard CNN), but its novelty comes from its use of triplet loss.
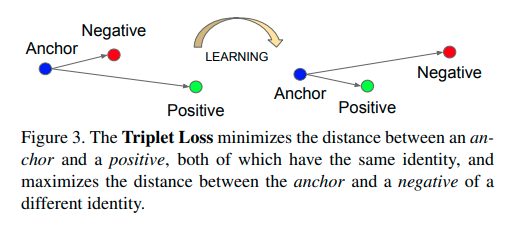
Triplet loss today is nothing ground-breaking today and is now part of what is considered One-Shot Learning.
VectorHub Implementation
The VectorHub Implementation is a 2-stage process from photo to face extraction to vectorization.

The model is able to detect faces and also identify facial landmarks — see below. From this, we can use vector search to grab photos of individuals with facial landmarks in similar places, allowing us to search for other photos with half-faces/different angular orientations.

If you would like to see more of this type of analysis or prefer more in-depth analysis of ____2Vec models (apart from just Face2Vec), give this story a clap/leave a comment and we may introduce this as a series and go more into depth into them. Remember to check out VectorHub if you are interested in testing out the model!
Citations & Acknowledgement
The Face2Vec implementation could not have been possible without a lot of support from researchers and engineers who have built some incredible packages!
These include those of the Tensorflow Datasets team, FaceNet team[1], the MTCNN team (https://github.com/ipazc/mtcnn) and the Celeb A team[2]! Thank you for their hard work in allowing us access into the FaceNet2Vec model implementation for VectorHub!
Schroff, Florian and Kalenichenko, Dmitry and Philbin, James, FaceNet: A Unified Embedding for Facial Recognition and Clustering (2015), CVPR 2015
Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou, Deep Learning Face Attributes in the Wild, (2015), IEEE Computer Society.
The Strengths & Weaknesses of Face2Vec (FaceNet) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")

Recent Posts
")



")


