



ROI based Hybrid Lossy and Lossless Image Compression
Last Updated on February 25, 2021 by Editorial Team
Author(s): Mahisha Patel
Computer Vision
You don’t always need an entire high-quality image for insights!
This article aims to present the amalgamation of lossy and lossless compression for building a hybrid approach based on Region Of Interest that provides a high compression ratio and serves the purpose of efficient storage and transmission without affecting the accuracy.
Presently, we have entered an era where information holds value more than anything else. It has been a crucial thing to store and maintain massive amount of data for future insights. For this, we need a huge capacity for storage and high bandwidth to transfer the data.
In many sectors, we deal with large number of image datasets including the Healthcare and Multimedia sectors. Here, Image Compression plays an important role in reducing the size of the image data seeking less storage space and providing low latency.
Table of Contents
- Image Compression: Lossy and Lossless
- Introduction to ROI in Images
- Hybrid Approach towards Image Compression
- Conclusion
Image Compression: Lossy and Lossless
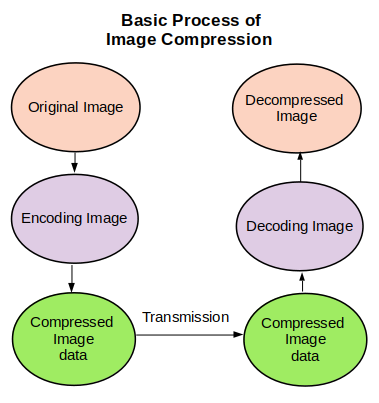
Image Compression, a type of data compression, is a technique of reducing image size for a reduction in the cost of storage and transmission. Image Compression is of basically two types :
- Lossy Compression: This technique is used in areas where not every bit of data is important. Lossy compression leads to the loss of some information. When the image is decoded, it represents the uncompressed image but with the loss of some of the information. Examples of Lossy Compression are JPEG and WebP.
- Lossless Compression: This technique is used in areas where data is critical, and loss of information is not acceptable. When the image is decoded, it completely matches with the original image without loss of data. Examples of Lossless Compression are Gif and PNG.
Introduction to ROI in Images
An image consists of three parts which are :
- Region of interest (ROI)
- Non-Region of interest (Non-ROI)
- Background
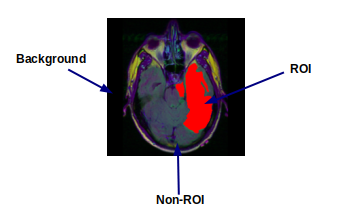
To illustrate ROI, I’ve taken a brain MRI image from Kaggle Dataset as shown above. The red-colored portion is shown as a Region of interest (ROI) which is the part affected by the tumor. Only this portion is needed for further evaluation by the doctor. Other than that, the Non-ROI portion shown has not much of an importance to be observed, and the black portion which is the background can completely be ignored.
So, a technique can be derived that takes into account the unimportant parts of the images, i.e. Non-ROI and background, to maximize the compression ratio.
Hybrid Approach towards Image Compression
Direction: To achieve a high compression ratio, the hybrid approach is proposed to combine lossy and lossless compression based on the Region of Interest. ROI is the most important part of the image that covers a very minute area of the image. Non ROI is also included which enables the user to bifurcate the most critical part from the whole image. Part other than ROI and Non-ROI is the background and most unused part of the image. As ROI is most crucial, it must be compressed using Lossless compression and Non-ROI can be compressed via Lossy compression whereas the background can be ignored.
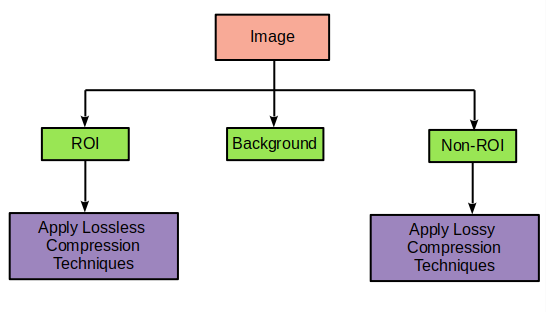
There exists numerous Lossless as well as Lossy compression techniques. The input image will be segmented into ROI and Non-ROI image and finally different techniques of Lossless Compression and Lossy Compression will be applied respectively.
Here, Context tree weighting lossless(CTW) for the ROI part and Fractal lossy compression for Non-ROI part is shown. We can use any other techniques of lossy and lossless compression instead of CTW and Fractal compression.
Lossy Compression — Fractal Compression
Fractal compression is a lossy compression method for digital images, primarily based on fractals. The method is best applicable for textures and natural images, relying on the fact that parts of an image often resemble different parts of the same image. Fractal algorithms convert these parts into mathematical data called “fractal codes” which are used to recreate the encoded image.
Lossless Compression — Context Tree Weighting (CTW)
Context Tree Weighting is a lossless compression and prediction algorithm. It gives the both theoretical and practical guarantees for the performance. The CTW technique is a “group technique,” combining the expectations of numerous hidden variable request Markov models, where each such model is built utilizing zero-request probability estimators.
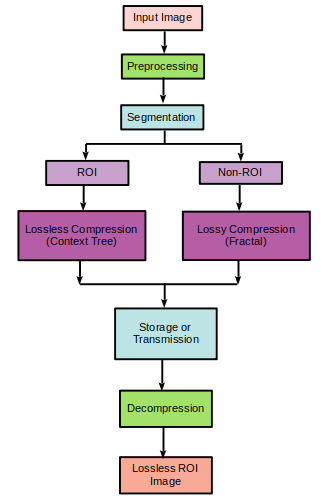
– Preprocessing (Rotation, Scaling, Translation, etc.) is done on the input image.
– Segmentation is done based on Region Of Interest.
1. ROI part: Context Tree Compression is applied.
2. Non-ROI part: Fractal Compression is applied.
– Storage or Transmission takes place after merging both parts of images.
– Decompression is performed.
The hybrid approach of combining these techniques of lossy and lossless compression outperforms many other techniques (Huffman and Arithmetic coding, IWT and Scalable RBC, etc.) when their performance parameters are compared.
Some of the performance parameters are:
- Mean Squared Error (MSE): It is the widely used measurement criteria for evaluating image quality in terms of error value between compressed and uncompressed images. The algorithm having the least MSE value is the most efficient algorithm.
- Compression Ratio (CR): It is the ratio between a number of pixels uncompressed (input) image to compressed (output) image. If the compression ratio is more, it will be beneficial for storage and transmission.
- Peak Signal to Noise Ratio (PSNR): It is a measure between the peak error between the compressed and uncompressed original image. It basically represents the quality of the image. The value of PSNR must be high for better quality.
The above-stated hybrid method for lossy and lossless compression gives higher CR, higher PSNR, and lower MSE than many state-of-the-art techniques.
Conclusion :
Image Compression is important from the research as well as the implementation point of view. This hybrid approach is better than the lossy or lossless technique as it highly increases the rate of compression and does not affect further evaluation or future insights. We can further apply a different combination of lossy and lossless compression methods to further increase the compression ratio without affecting the quality of the image.
References :
- ROI Based Medical Image Compression for Telemedicine
Application - https://en.wikipedia.org/wiki/Fractal_compression
- https://en.wikipedia.org/wiki/Context_tree_weighting
Thank you for reading! Have a nice day!! 🙂
ROI based Hybrid Lossy and Lossless Image Compression was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")

Recent Posts






")