



Detecting Marine Creatures using the Monk Object Detection Library
Last Updated on January 6, 2023 by Editorial Team
Author(s): Aanisha Bhattacharyya
Computer Vision
The Monk Object Detection Library is a low code library to perform object detection very easily and efficiently.
About the project:
Brackish water creatures as fish, crabs, prawns are consumed by people all over the world. Fishermen fishing on these creatures tend to over-fish creating concern over marine biologists and scientists. As many marine creatures are becoming endangered.But what if we had a detector, that could detect these creatures. That would definitely reduce the risk of over-fishing, and help these species from becoming endangered.
Using Monk Object Detection, we can build this very easily. So let’s start making it!!
About the Data-set:
For training any model, the foremost thing required is data. The data set used for this purpose is titled “The Brackish Dataset” available in Kaggle. The data set contains videos of marine creatures found in brackish water. Now we need to convert the video to frame images, for our model to train and detect.
Creating train, validation, and test data-sets:
Now once we get the frame images ready, we can proceed to create our data-set. For that, the data-set itself contains .txt files containing the list of image names for train, validation, and test data-sets respectively.
I have written a small function that takes the image folder path, destination path, and text file path as arguments. Once we pass that, it reads the text file, into a pandas dataframe, and moves the images whose names are available in the file, from the source directory to destination directory using “shutil”.
I have already processed the images, and performed the train-test split as well, so the data is available to be used directly. The data set contains around 11,000 training images, with 6 different variety of creatures.
Data-set Link: https://drive.google.com/drive/folders/1E7LZQlC_zR7Yvy4CJ3yyWTB1PZ0Rz5RS?usp=sharing
Creating the annotation file:
The Monk Object Detection Library supports various pipelines and supports both COCO and YOLO annotations. For this project, I would be using the “mmdnet” pipeline with COCO annotations.
I have included the annotation files also, directly. However, all the data pre-processing codes are available in the Github repository.
Annotation files link: https://drive.google.com/drive/folders/1EU9KDI9lN1hUFZ3WEuUWac6Alh9GhgBR?usp=sharing
Training the model:
We have the data ready, we have to now train the model. As mentioned earlier, I used the Monk Object Detection Library, for this purpose.
Installing and setting up the library:
By this, we clone the repository. Once the repository is cloned, we need to install the requirements, for our “mmdnet” pipeline, to use the library for our code.
This usually takes 5–6 mins, once every dependency is installed, we are ready to set up the library for use.
Now we import the detector function, which is used to train an object detector.
Loading the data:
Here the train images are loaded, along with the annotation file and the class name file.Similarly, we will load the validation set too.
Setting the parameters:
Now we will need to set the hyper-parameters, no of epochs, and the model, for our project. For this, I chose the “faster_rcnn_x101_64x4d_fpn” model.
Train the model:
The only step left now is to train the model and its easiest.
This starts the training, which takes a bit of time on a standard GPU. So be patient, while the model trains.
Testing the model:
The training requires 5–6 hrs on a standard GPU, and the more you can train the model, the better it performs.
Once the training is completed, we need to test the model performance.
We call the “Infer” method, to test the model performance.
Loading the trained model, and testing on test images:
We load the trained model, for testing. Now we pass a test image, to check the performance.

This output shows that the image is saved, as “test1.png” and now let’s see what it looks like.
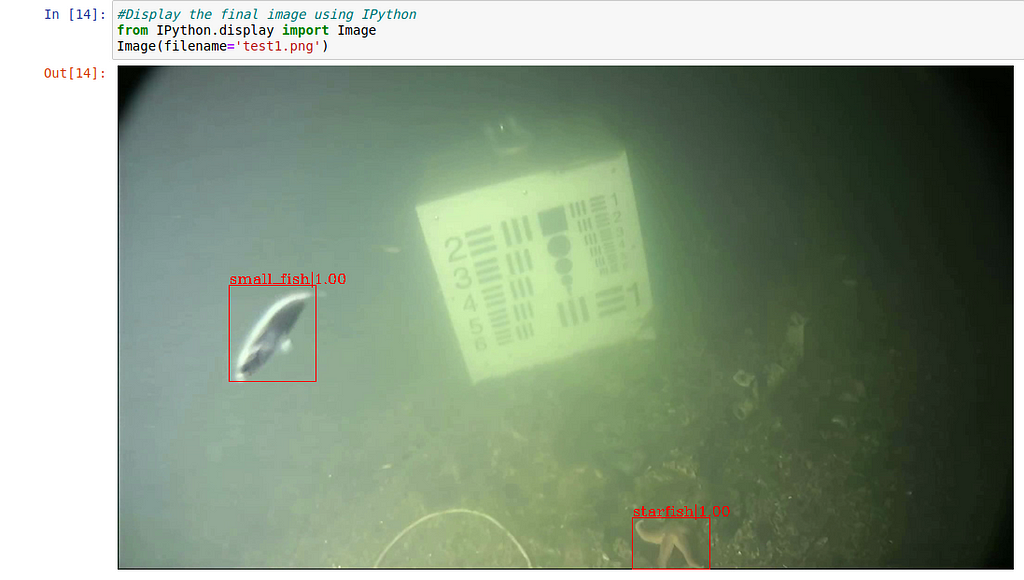
It's clearly seen that all the marine creature detected in this image is detected successfully by our model.
So you can train your own object detection model very easily. I have also linked the repository having the complete code.
Resources:
Monk Library: https://github.com/Tessellate-Imaging/Monk_Object_Detection
Original Dataset: https://www.kaggle.com/aalborguniversity/brackish-dataset
Detecting Marine Creatures using the Monk Object Detection Library was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")
Recent Posts




")

