



Build Natural Flower Classifier using Amazon Rekognition Custom Labels
Last Updated on January 6, 2023 by Editorial Team
Author(s): Juv Chan
Computer Vision
Building Natural Flower Classifier using Amazon Rekognition Custom Labels
The Complete Guide with AWS Best Practices
Introduction
Building your own computer vision model from scratch can be fun and fulfilling. You get to decide your preferred choice of machine learning framework and platform for training and deployment, design your data pipeline and neural network architecture, write custom training and inference scripts, and fine-tune your model algorithm’s hyperparameters to get the optimal model performance.
On the other hand, this can also be a daunting task for someone who has no or little computer vision and machine learning expertise. This post shows a step-by-step guide on how to build a natural flower classifier using Amazon Rekognition Custom Labels with AWS best practices.
Amazon Rekognition Custom Labels Overview
Amazon Rekognition Custom Labels is a feature of Amazon Rekognition, one of the AWS AI services for automated image and video analysis with machine learning. It provides Automated Machine Learning (AutoML) capability for custom computer vision end-to-end machine learning workflows.
It is suitable for anyone who wants to quickly build a custom computer vision model to classify images, detect objects and scenes unique to their use cases. No machine learning expertise is required.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account — You can create a new account if you don’t have one yet.
- AWS CLI — You should install or upgrade to the latest AWS Command Line Interface (AWS CLI) version 2.
Creating Least Privilege Access IAM User & Policies
As a security best practice, it is strongly recommended not to use the AWS account root user for any task where it is not required. Instead, create a new IAM (Identity and Access Management) user and grant the required permissions for the IAM user based on the principle of least privilege using identity-based policy. This adheres to the IAM best practices under the Security Pillar in the Machine Learning Lens for the AWS Well-Architected Framework.
In this walkthrough, the new IAM user requires both Programmatic access and AWS Management Console access.
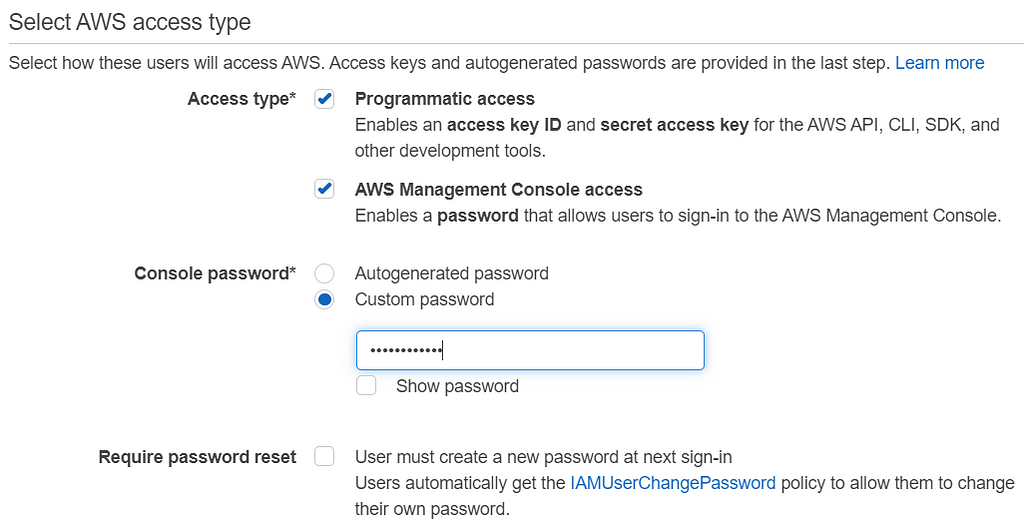
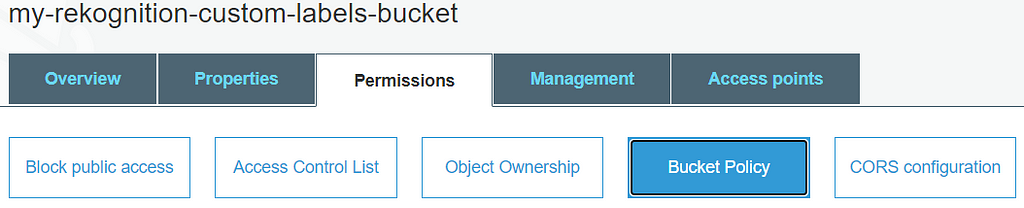
A new customer-managed policy is created to define the set of permissions required for the IAM user. Besides, a bucket policy is also needed for an existing S3 bucket (in this case, my-rekognition-custom-labels-bucket), which is storing the natural flower dataset for access control. This existing bucket can be created by any user other than the new IAM user.
The policy’s definition in JSON format is as shown.

Flower Dataset
We use the Oxford Flower 102 dataset from the Oxford 102 Flower PyTorch Kaggle competition for building the natural flower classifier using Amazon Rekognition Custom Labels. We use this instead of the original dataset from the Visual Geometry Group, University of Oxford, because it has already been split into train, valid, test datasets, and more importantly, the data has been labelled with respective flower category numbers accordingly for train and valid.
This dataset has a total of 8,189 flower images, where the train split has 6,552 images (80%), the valid split has 818 images (10%), and the test split has 819 images (10%). The code snippet below helps to convert each of the 102 flower category numbers to their respective flower category name.
import os
import json
with open('cat_to_name.json', 'r') as flower_cat:
data = flower_cat.read()
flower_types = json.loads(data)
for cur_dir_name, new_dir_name in flower_types.items():
os.rename(cur_dir_name, new_dir_name)
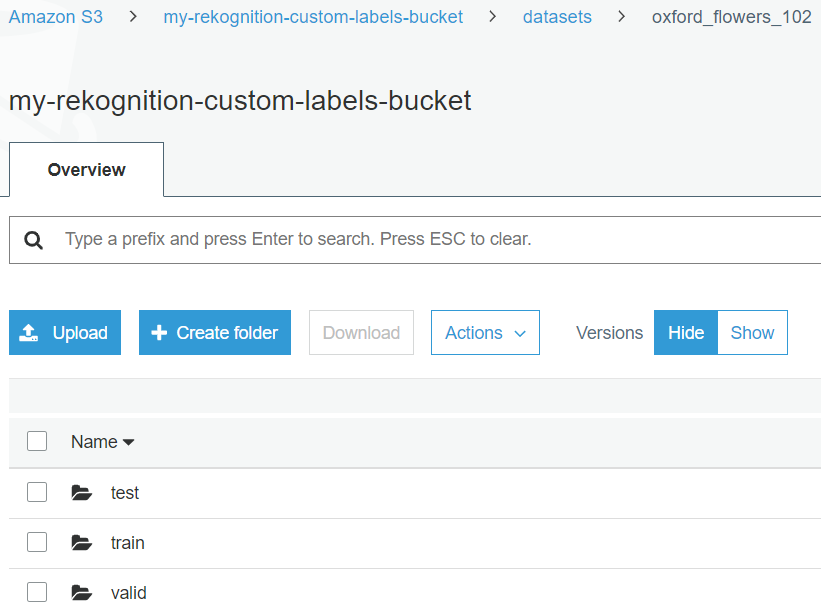
The dataset bucket should have the same folder structure, as shown below, with both train and valid folders. Each should have 102 folders beneath where each folder name corresponds to a specific flower category name.
Creating a New Flower Classifier Project
After the necessary setup has been completed, you can sign in to the AWS management console as the IAM user. Follow the steps in this guide to create your new project for Amazon Rekognition Custom Labels.
Creating New Training and Test Datasets
We create new training and test datasets for the flower classifier project in Amazon Rekognition Custom Labels by importing images from the S3 bucket. It is important to give the dataset a clear and distinctive name to distinguish between different datasets as well as training or test.
For the training dataset, the S3 folder location is set to the S3 train folder path as below. Similarly, for the test dataset, the S3 folder location is set to the S3 valid folder path.
s3://my-rekognition-custom-labels-bucket/datasets/oxford_flowers_102/train/
s3://my-rekognition-custom-labels-bucket/datasets/oxford_flowers_102/valid/
train
|- alpine sea holly
| |- image_06969.jpg
| |- image_06970.jpg
| |- ...
|- anthurium
| |- image_01964.jpg
| |- image_01965.jpg
| |- ...
|...
valid
|- alpine sea holly
| |- image_06977.jpg
| |- image_06978.jpg
| |- ...
|- anthurium
| |- image_01972.jpg
| |- image_01975.jpg
| |- ...
|...
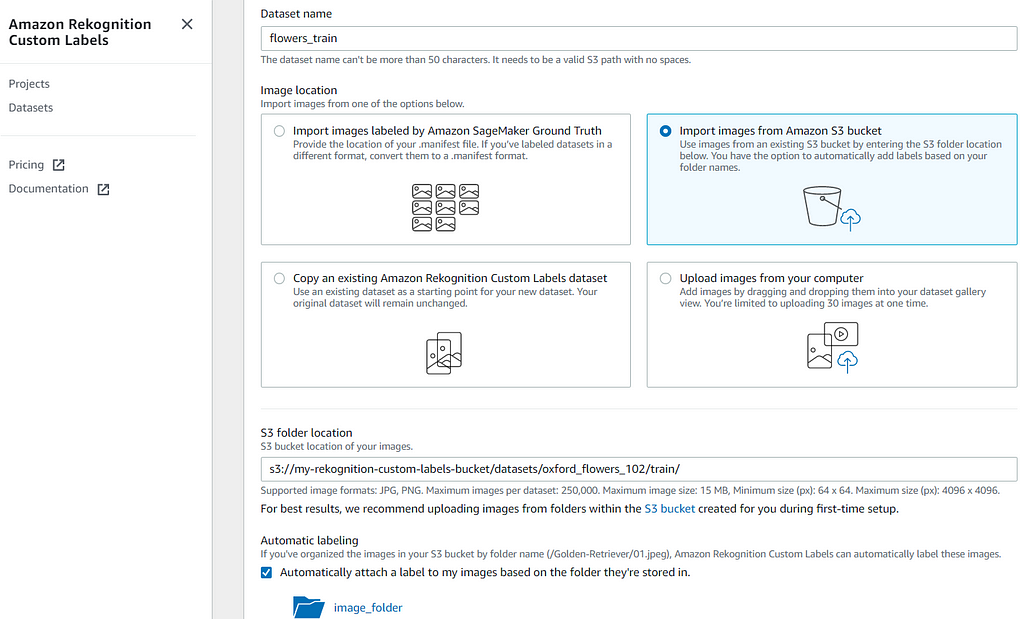
All the images in both training and test datasets are organized into folder names that represent their respective flower category labels. Please make sure to enable Automatic Labeling by checking the box as shown above as Amazon Rekognition Custom Labels supports automatic labeling of these images in such structures. This can save a lot of time and effort from manually labeling large image datasets.
You can safely disregard the “Make sure that your S3 bucket is correctly configured” message as you should have applied the bucket policy earlier. Please make sure that your bucket name is correct if you use a different name than the one in this example.

After you create the training and test datasets, you should use the datasets as listed.
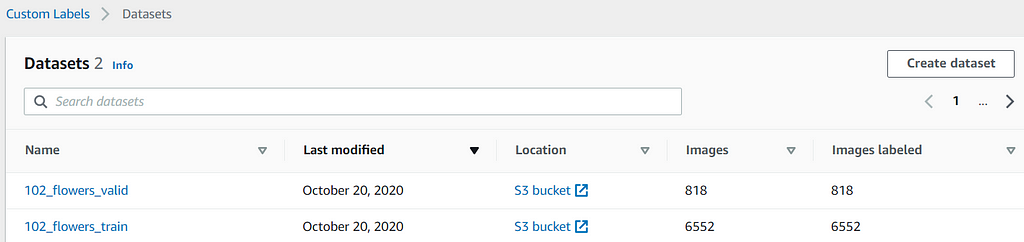
When you click into either of the datasets, you should find that all the images are labeled accordingly. You can click on any of the labels to inspect the images of that label. You can also search for a label in the search text box on the left.
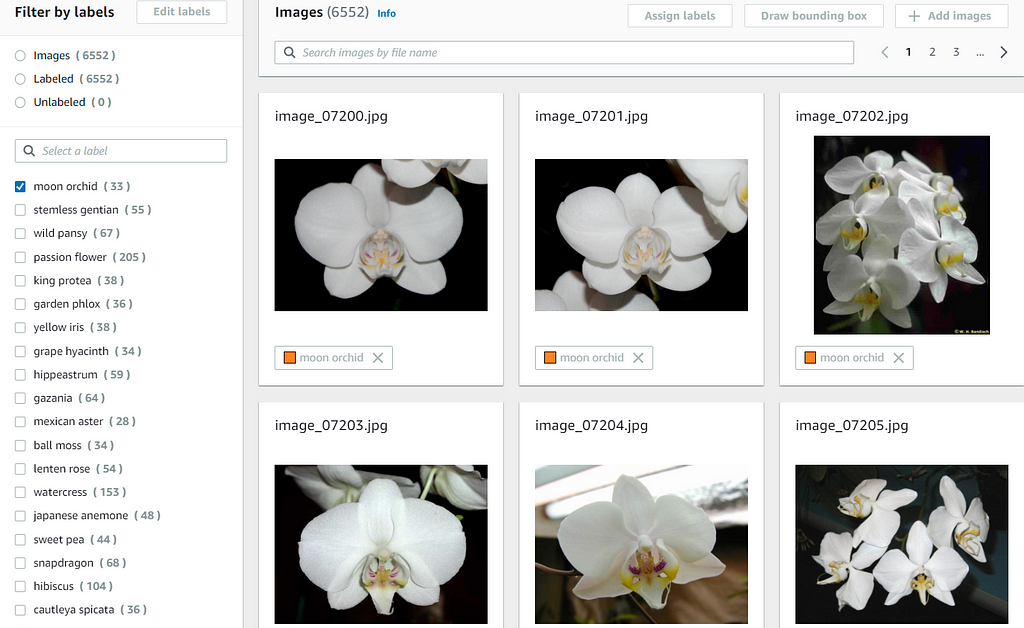
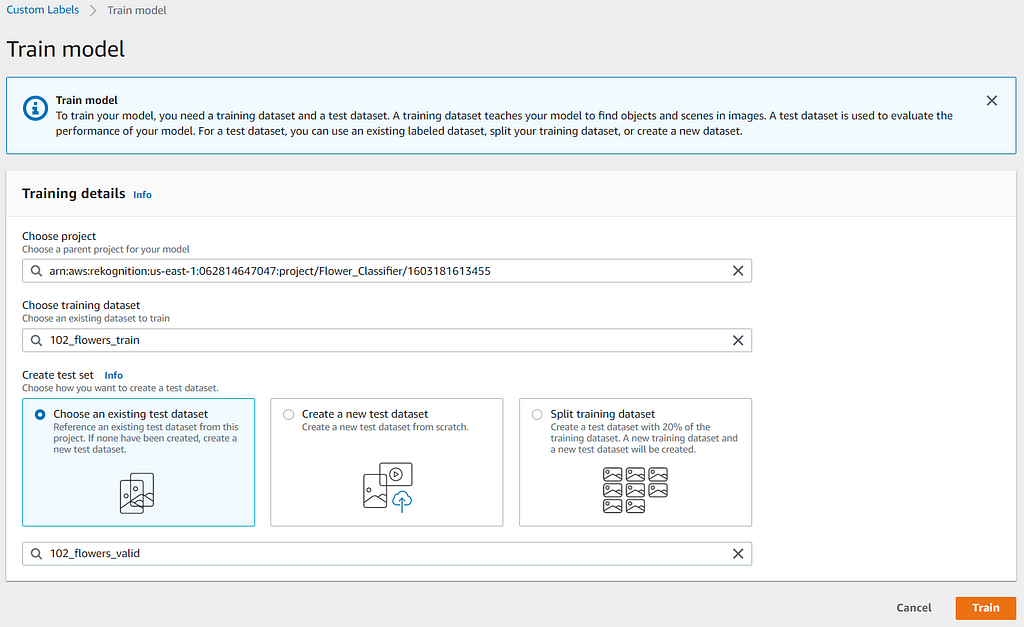
Training New Flower Classifier Model
You can train a new model in the Amazon Rekognition Custom Labels console by following this guide. To create a test dataset, you should use the “Choose an existing test dataset” option, as shown below, since it should have been created in the previous section.
The training based on this flower dataset could take more than an hour (approximately 1 hour and 20 minutes in this case) to complete.
Evaluating the Trained Model Performance
After the flower classifier model is trained, you can review the model performance by accessing the Evaluation Results in the console, as shown. You can better understand the metrics for evaluating the model performance from this guide. You should be able to achieve similar model performance evaluation results with the same datasets in Amazon Rekognition Custom Labels.
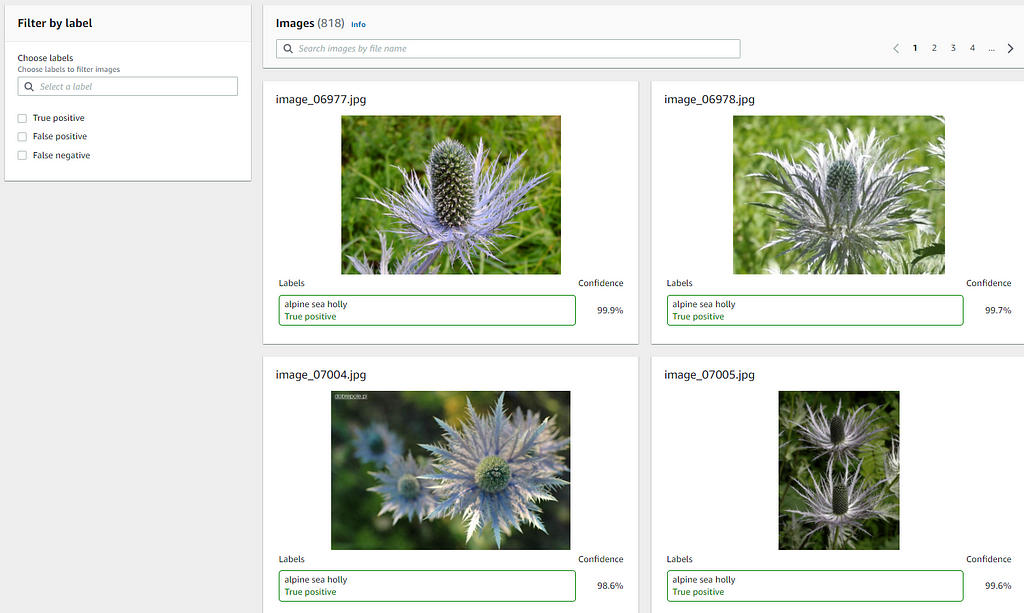
The Per Label Performance is a great feature that allows you to analyze the performance metrics at per label level so that it’s faster and easier for you to find out which labels are performing better or poorer than the average.
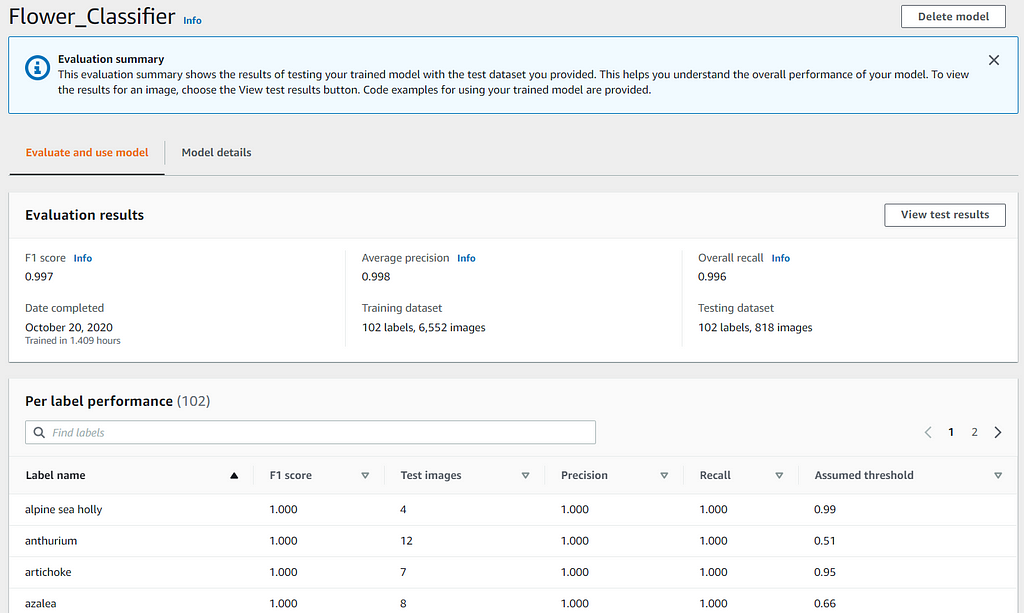
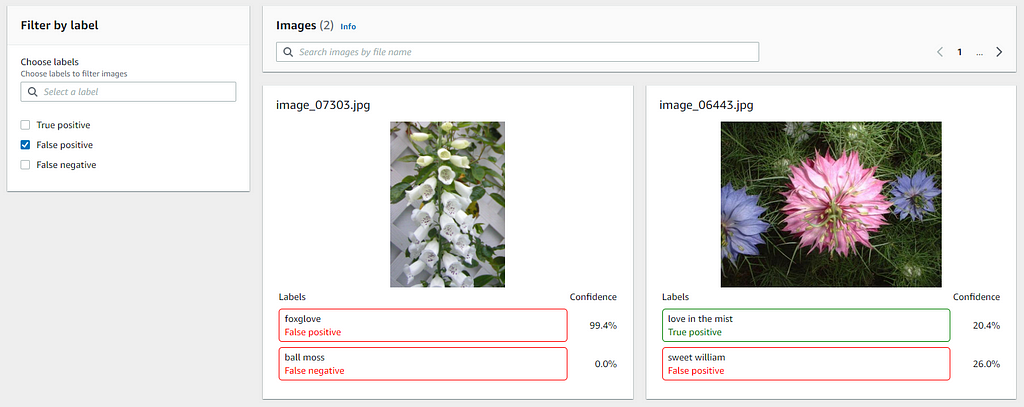
Besides, you can also review and filter the results (True Positive, False Positive, False Negative) of the test images to understand where the model is making incorrect predictions. This information helps you to improve your model’s performance by indicating how to change or add images to your training or test dataset.
Starting the Flower Classifier Model
When you are happy with the performance of your trained flower classifier model, you can use it to predict flowers of your choice. Before you can use it, you need to start the model. At the bottom section of the model evaluation results page, there are sample AWS CLI commands on how to start, stop, and analyze flower images with your model. You can refer to this guide for the detailed step to start the model and set up the AWS CLI for the IAM user.
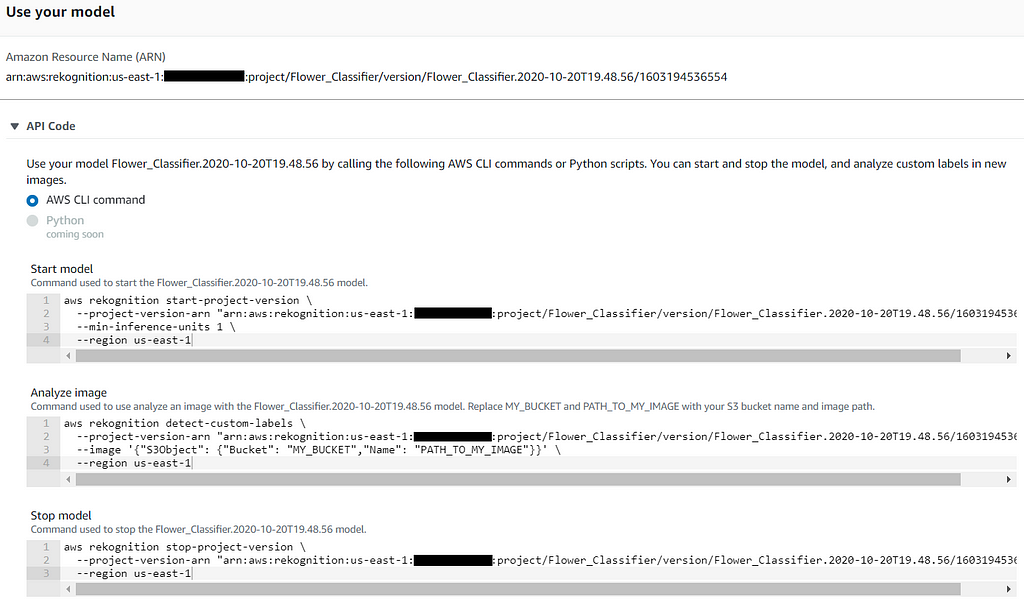
To start the model, use the AWS CLI command, as shown below. Note that you should change the command line arguments based on your setup or preference. The named profile is specific to the IAM user created for Amazon Rekognition Custom Labels.
aws rekognition start-project-version
--project-version-arn "MODEL_ARN"
--min-inference-units 1
--region us-east-1
--profile customlabels-iam
Starting the model takes a while (approximately 15 minutes in this case) to complete. You should see the model status shows as RUNNING in the console, as shown.
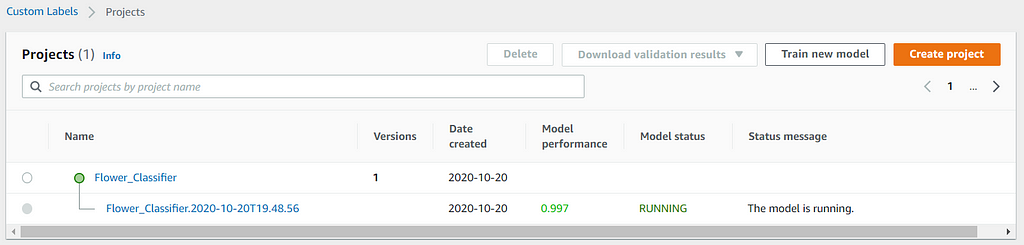
Classifying with Unseen Flower Images
After the model is running, you can use it to predict the flower types of images that do not exist in both the training and test datasets to determine how well your model can perform on supported flower types, which it has not seen before. You can use the AWS CLI command below to determine the predicted label of your image.
aws rekognition detect-custom-labels
--project-version-arn "MODEL_ARN"
--image '{"S3Object": {"Bucket": "BUCKET_NAME", "Name": "IMAGE_PATH"}}'
--region us-east-1
--profile customlabels-iam
Here are some of the prediction results with datasets that are self-taken or independent from both the training and test datasets.

{
"CustomLabels": [
{
"Name": "rose",
"Confidence": 99.93900299072266
}
]
}

{
"CustomLabels": [
{
"Name": "lotus",
"Confidence": 99.7560043334961
}
]
}

{
"CustomLabels": [
{
"Name": "moon orchid",
"Confidence": 98.02899932861328
}
]
}

{
"CustomLabels": [
{
"Name": "hibiscus",
"Confidence": 98.11100006103516
}
]
}

{
"CustomLabels": [
{
"Name": "sunflower",
"Confidence": 99.86699676513672
}
]
}

{
"CustomLabels": []
}

{
"CustomLabels": []
}
Cleaning Up Resources
You are charged for the amount of time your model is running. If you have finished using the model, you should stop it. You can use the AWS CLI command below to stop the model to avoid unnecessary costs incurred.
You should also delete the Custom Labels project and datasets in the S3 bucket if they are no longer needed to save costs as well.
aws rekognition stop-project-version
--project-version-arn "MODEL_ARN"
--region us-east-1
--profile customlabels-iam
Stopping the model is faster than starting the model. It takes approximately 5 minutes in this case. You should see the model status shows STOPPED in the console.
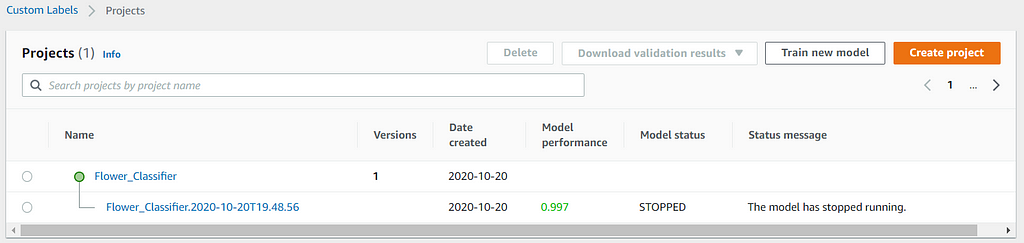
Conclusions and Next Steps
This post shows the complete step-by-step walkthrough to create a natural flower classifier using Amazon Rekognition Custom Labels with AWS best practices based on the AWS Well-Architected Framework. It also shows that you can build a high-performance custom computer vision model with Amazon Rekognition Custom Labels without machine learning expertise.
The model built in this walkthrough has an F1 score of 0.997, which is not easy to achieve for the same dataset if build from scratch even with extensive machine learning expertise. It is also able to perform well on the samples of the unseen natural flowers and is expected not able to predict on the samples of artificial flowers.
If you are interested in building a natural flower classifier from scratch, you might be interested in my post: Build, Train and Deploy A Real-World Flower Classifier of 102 Flower Types — With TensorFlow 2.3, Amazon SageMaker Python SDK 2.x, and Custom SageMaker Training & Serving Docker Containers.
Build Natural Flower Classifier using Amazon Rekognition Custom Labels was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")

Recent Posts






")
Comments are closed.