



Build a License Plate Recognition App using Streamlit
Last Updated on December 11, 2023 by Editorial Team
Author(s): Lu Zhenna
Originally published on Towards AI.
Summary
This article briefly walks through a solution to extract text from variable-line license plates using the pre-trained model and explains step-by-step on how to build a web app using Streamlit to deliver this solution to users.
Streamlit is an open-source app framework built specifically for Machine Learning and Data Science projects.
Target Audience
- Data scientists who are interested to learn web development but think that life is too short to learn html, css, js.
- Aspiring machine learning engineers who are interested to turn your python code into shareable web apps .
Outline
- Detect the License Plate closest to the camera
- Use
easyocrortesseractto extract text - Build an app to take an image as input and then output a string
Problem Statement
Given a 2D image, taken from variable angles, distances and luminance conditions, of one or multiple vehicles, we want to extract the license plate number of the vehicle closest to the camera. All license plates are from Singapore, which means the license plate number only consists of English characters and numbers with one or two lines in variable lengths.
- Detect the License Plate closest to the camera
I will use a pre-trained yolov5 model without fine-tuning, because I don’t have data. Here is my code:
import yolov5
import torch
def inference(
path2img: str,
show_img: bool = False,
size_img: int = 640,
nms_conf_thresh: float = 0.7,
max_detect: int = 10,
) -> torch.Tensor:
model = yolov5.load("keremberke/yolov5m-license-plate")
model.conf = nms_conf_thresh
model.iou = 0.45
model.agnostic = False
model.multi_label = False
model.max_det = max_detect
results = model(path2img, size=size_img)
results = model(path2img, augment=True)
if show_img:
results.show()
return results.pred[0]
I know you must wonder why I don’t just set max_detect as 1 and directly get one bounding box instead of multiple? It’s because every predicted bounding box has a confidence score. With max_detect = 1 , you get the most confident prediction which may not always be the license plate closest to the camera.

So I have to calculate the area of all predicted bounding box and keep the one with the biggest area. That will always give me the closest license plate even when the confidence is low due to skewed angle etc.

2. Use easyocr or tesseract to extract text
If your license plate has fixed length and only a single line, tesseract is mostly enough. However, from my experience, it performs poorly with number 9 and character Z and occasionally D.
My code is pasted below. Please change the tessedit_char_whitelist and lang accordingly, if your license plates contain non-English characters.
import pytesseract
def ocr_tesseract(path2img):
text = pytesseract.image_to_string(
path2img,
lang="eng",
config="--oem 3 --psm 6 -c tessedit_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789",
)
return textIt can successfully recognize one-line license number, however, tesseract fails to extract the second line for the image below.

This red taxi carplate is considerably difficult for tesseract because it contains D, 9 and Z. Let’s try easyocr instead!

Despite of the challenges, easyocr successfully recognized most characters except for 5! I would definitely recommend easyocr over tesseract. Here is my code:
def ocr_easyocr(path2img):
image = cv2.imread(path2img)
reader = easyocr.Reader(["en"], gpu=False)
detections = reader.readtext(image)
plate_no = []
[plate_no.append(line[1]) for line in detections]
return "".join(plate_no)
3. Build an app to take an image as input and then output a string
Here comes the most exciting part!
For users to make use of what we have built, we need a web application to upload image and read the decoded license plate string.
To break it down even further:
- 3.1 Display title and subtitle
- 3.2 Display a file uploader for users to upload an image
- 3.3 Show recognized license plate number as text output
- 3.4 Display the uploaded image with predicted bounding box
3.1 Display title and subtitle
First, let’s install streamlit by running pip install streamlit.
Next, open the Streamlit UI by running streamlit hello in the terminal.

The UI will pop up in the default browser. Have fun exploring the demo!

3.2 Display a file uploader for users to upload an image
Now, let’s add a title for our web app. I created a python script in src/ and named it app.py.
import streamlit as st
def app():
st.header("License Plate Recognition Web App")
st.subheader("Powered by YOLOv5")
st.write("Welcome!")
if __name__ == "__main__":
app()
Then I ran the command streamlit run src/app.py in the terminal.

Refresh the web page you will see the title and subtitle appear there! You don’t need html syntax at all!

Time to add more widgets! I want a file uploader with buttons for users to click. The new app function is below.
def app():
st.header("License Plate Recognition Web App")
st.subheader("Powered by YOLOv5")
st.write("Welcome!")
# add file uploader
with st.form("my_uploader"):
uploaded_file = st.file_uploader(
"Upload image", type=["png", "jpg", "jpeg"], accept_multiple_files=False
)
submit = st.form_submit_button(label="Upload")
Run the streamlit run command again and you will see the file uploader appear. You don’t need any css styling.
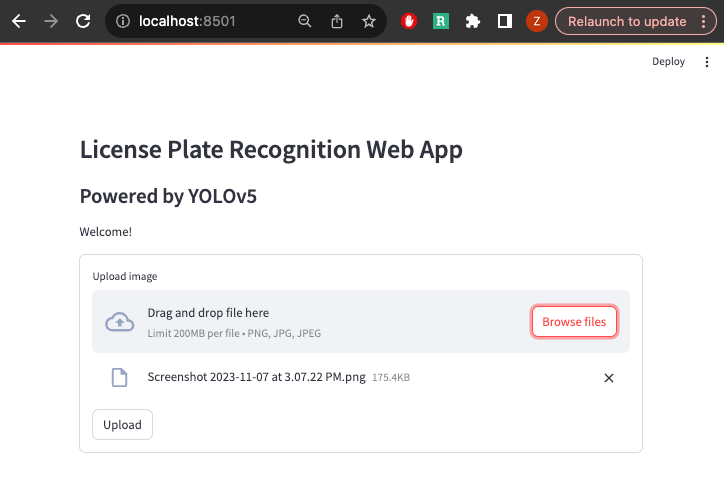
3.3 Show recognized license plate number as text output
Once users upload an image (trigger: click the upload button), we can use the relevant python functions to make an inference. The license plate number will be displayed as text.
def app():
st.header("License Plate Recognition Web App")
st.subheader("Powered by YOLOv5")
st.write("Welcome!")
with st.form("my_uploader"):
uploaded_file = st.file_uploader(
"Upload image", type=["png", "jpg", "jpeg"], accept_multiple_files=False
)
submit = st.form_submit_button(label="Upload")
if uploaded_file is not None:
# save uploaded image
save_path = os.path.join("temp", uploaded_file.name)
with open(save_path, "wb") as f:
f.write(uploaded_file.getbuffer())
if submit:
# display license plate as text
text = run_license_plate_recognition(save_path).recognize_text()
st.write(f"Detected License Plate Number: {text}")
if __name__ == "__main__":
app()

3.4 Display the uploaded image with predicted bounding box
Although we have both input and output in the web app, it is still not enough. It will be better if we can show users the image they uploaded with a bounding box. By adding a small widget, we can reassure the users that the prediction is made for the right vehicle. Especially when prediction is not perfect, it will be easier for users to figure out the discrepancy.

To make it more interactive, I will add a spinner while processing the request.

Once detection has been completed, the image will be displayed below.

I really appreciate Streamlit after using Django. The latter is not something that data scientists can master in one day. Streamlit allows data scientist to concentrate on our work while still able to deploy our solution to users with minimal knowledge of front-end web development.
To view the code repo, please click on this link.
Follow me on LinkedIn U+007C U+1F44FU+1F3FD for my story U+007C Follow me on Medium
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

