



70+ Image Classification Datasets from different industry domains — Part 2
Last Updated on February 6, 2021 by Editorial Team
Author(s): Abhishek Annamraju
A list of single and multi-class Image Classification datasets (With colab notebooks for training and inference) to explore and experiment with different algorithms on!
In the part-1 of this two-part blog series, a list of object detection datasets were presented. In this second part, a list of image classification type datasets is provided along with training and inferencing codes.
An object recognition system involves localizing an object of interest and then tagging it with a label. An image classification system can be considered as an application that attaches single or multiple tags to an image, for example,
* Analysing a pic is of a dog or a cat
* Distinguishing a cancerous cell from a normal one
* Attaching multiple tags based on daylight time (day, night, evening), scene type (indoor, garden area, on-road), quality of the image, etc
One tackle an object recognition problem using complex algorithms such as SSD, EfficientDet, Mask-Rcnn, Yolo, Retinanet, etc. Whereas while taking on an image classification challenge you depend more on neural network (CNNs most of the time) architecture such as Densenets, Resnets, Mobinets, Vgg-nets, etc. You may approach the training using transfer learning where you pre-train your model on a large dataset so that it learns how to extract important features from an image. Or, you design your own network and train it from scratch.
And as mentioned in the blog-1 as well, it is really important to test your theoretical knowledge on datasets from different domains. The way you handle medical imaging dataset tends to differ from the way you handle a dataset of fashion products.
Our opensource team at Monk Computer Vision Org compiled this list of image classification datasets and created short tutorials over each of them for you to utilize these datasets and try out different transfer learning experiments with varied hyperparameters
In this blog, datasets from following industries are listed
★ Art
★ Agriculture
★ Automobile and Advanced Driver Assistance Systems
★ Fashion
★ Food and Groceries
★ Wildlife
★ Sports
★ Satellite Imaging
★ Medical Imaging and Healthcare
★ Security and Surveillance
★ Scene type understanding
….. and much more!!!!!
The complete list at one place is available on Github with associated usage instructions and training codes
Automobile and ADAS Related Datasets
A) German Traffic Sign Classification Dataset
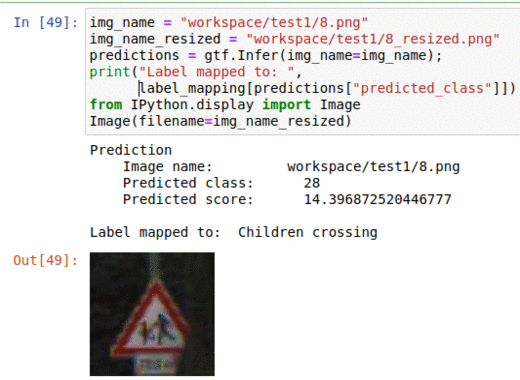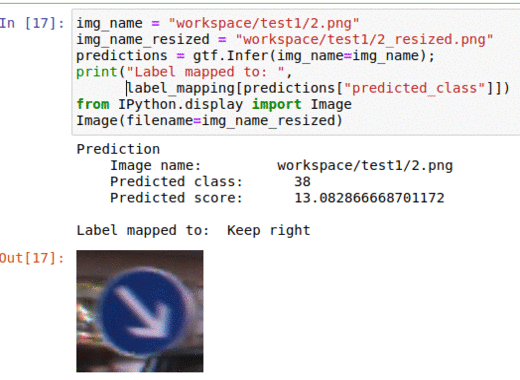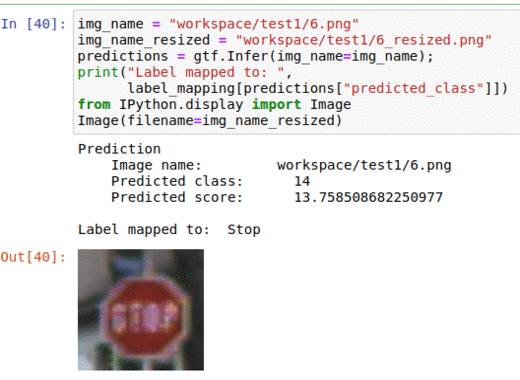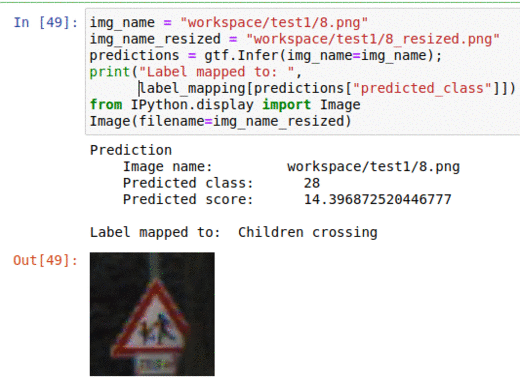
* Goal — To classify traffic sign types
* Application — Essential for autonomous vehicles and adas systems to classify traffic signs pose detection to allow smooth traffic passage
* Details — 50K+ images with 40+ classes
* How to utilize the dataset and create a classifier using Pytorch’s Resnext pipeline
B) Driver distraction monitoring dataset
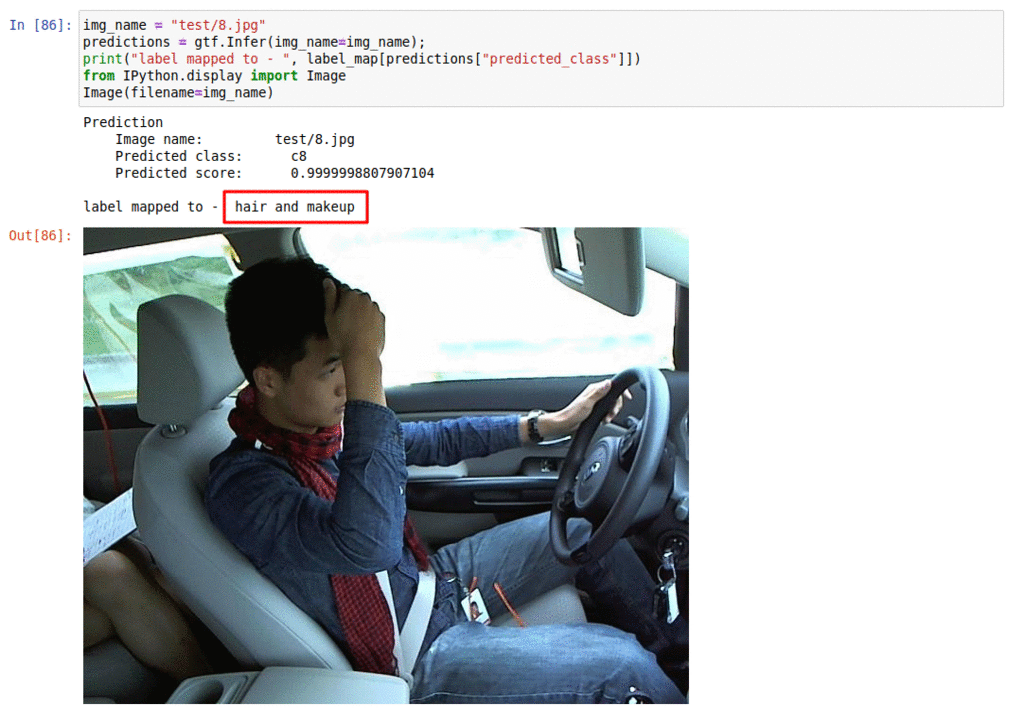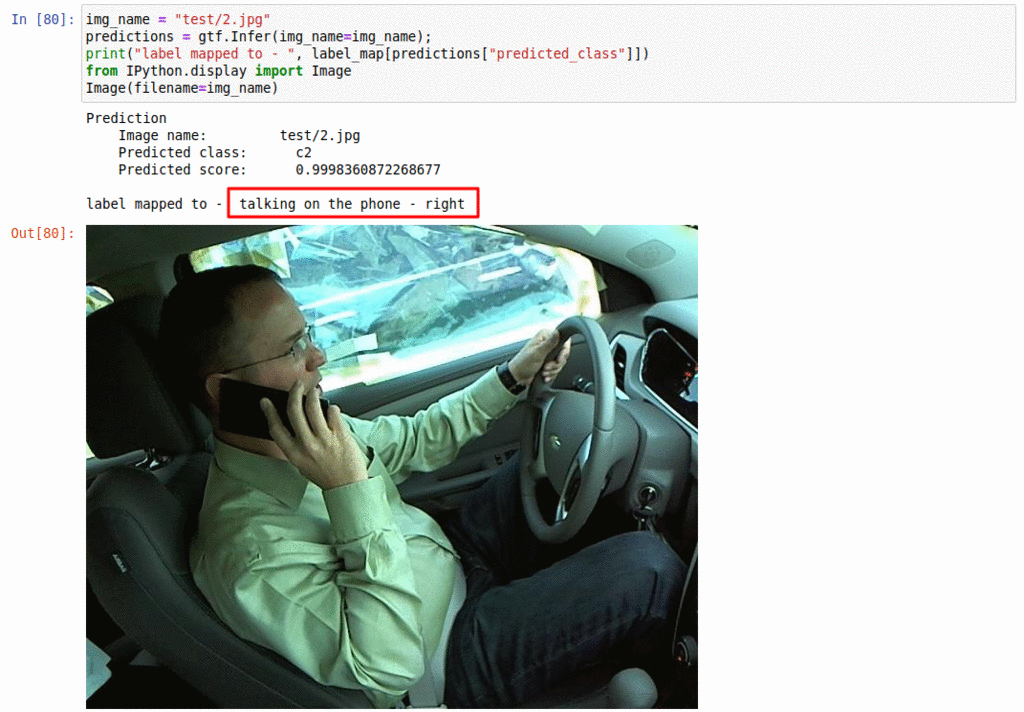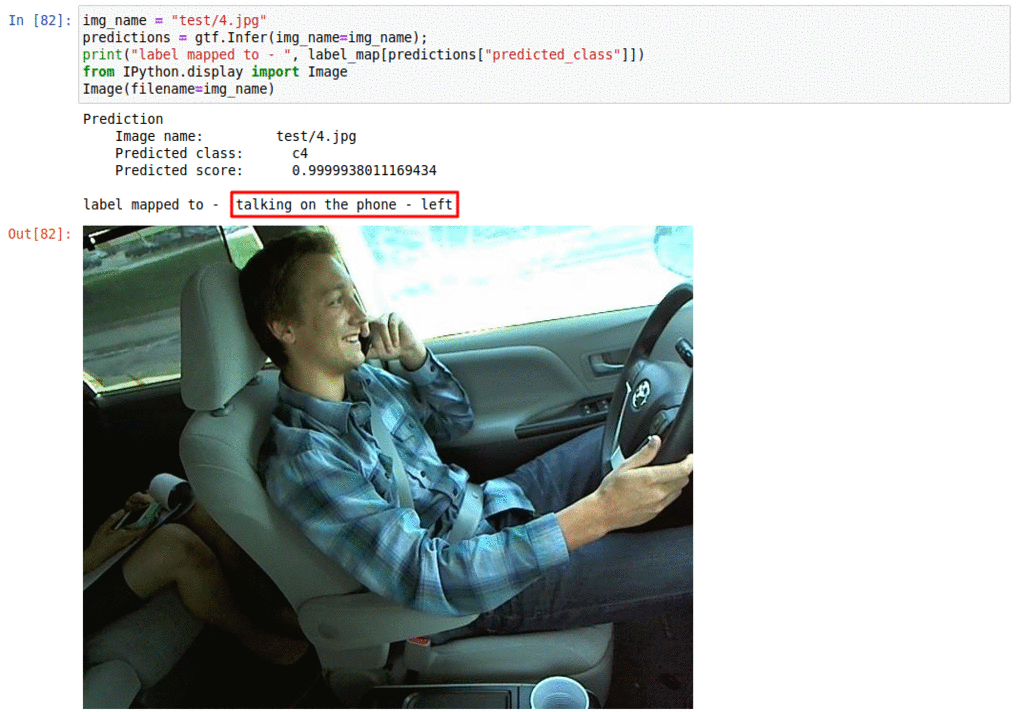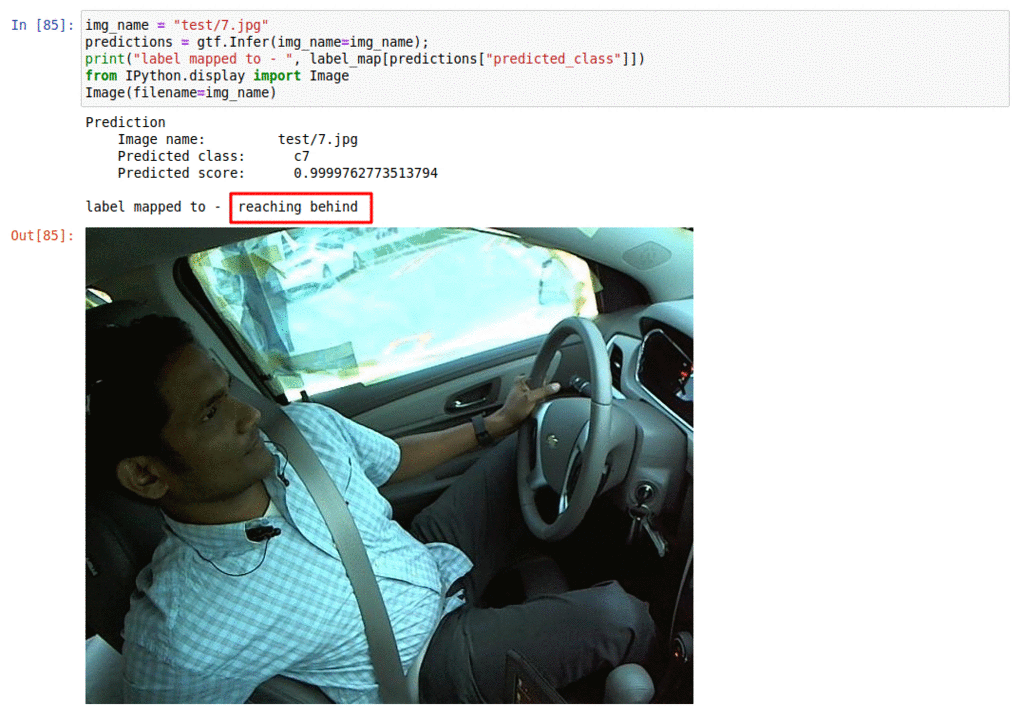
* Goal — To monitor driver activities
* Application — Essential for alerting the driver of any distractions while driving
* Details — 20K+ images with 10+ classes of distraction such as talking on the phone, operating radio, etc
* How to utilize the dataset and create a classifier using Keras’s Resnet pipeline
C) Vehicle Make Model Type Classification

* Goal — To classify vehicle type, it’s make, model and body type
* Application — Essential for traffic analysis and tool booths for automated taxations
* Details — 50K+ images with multi class type labels
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
D) MIO-TCD Vehicle Type Classification from Traffic Cam Videos

* Goal — To classify vehicle type, captured from cctv traffic cams
* Application — Essential for traffic analysis
* Details — 130K+ images with 11 vehicle classes type
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
Animals Related Datasets
A) Simple Cats & Dogs Dataset
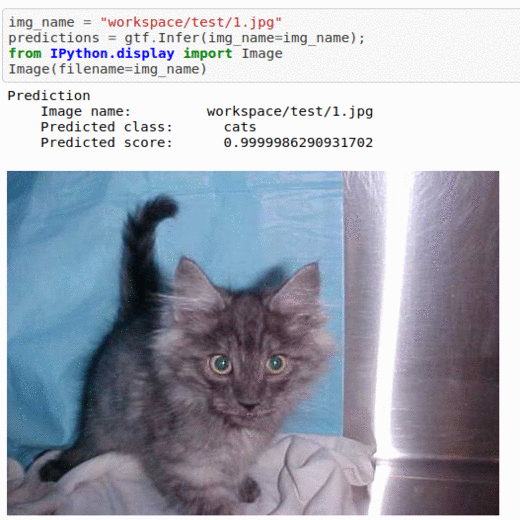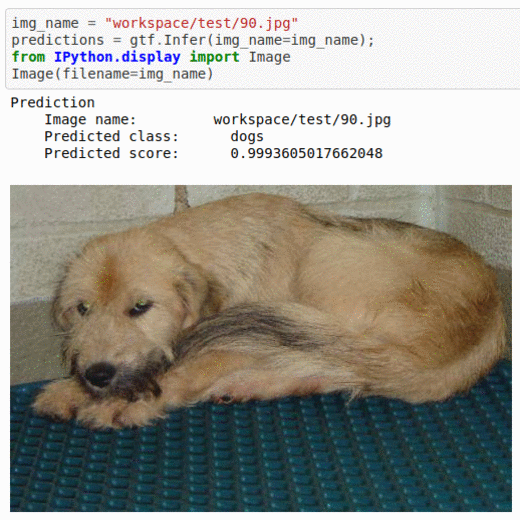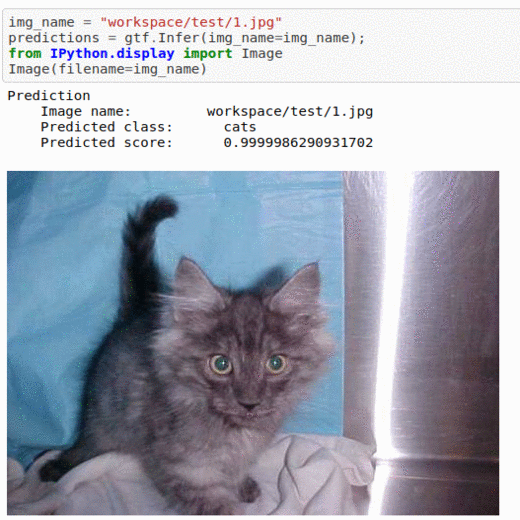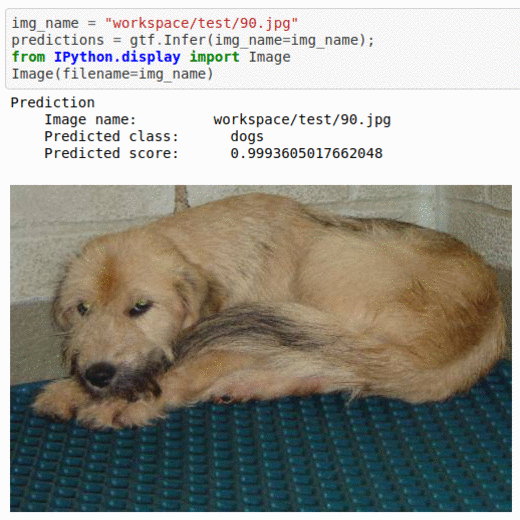
* Goal — To differentiate between images of dogs and cats
* Application — Sorting a large database of images
* Details — 10K+ images with 2 classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
B) Monkey Species Classification Dataset
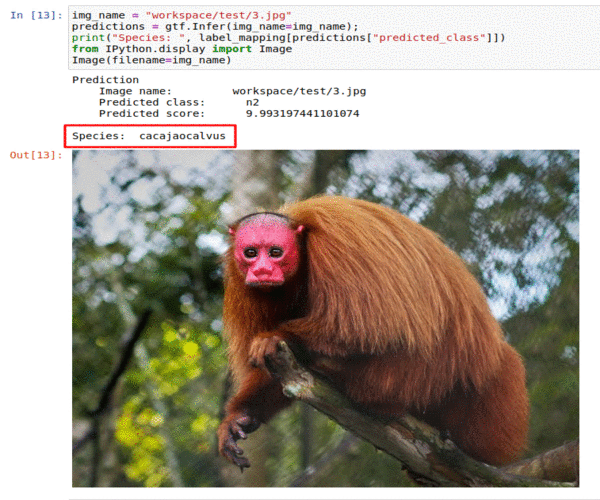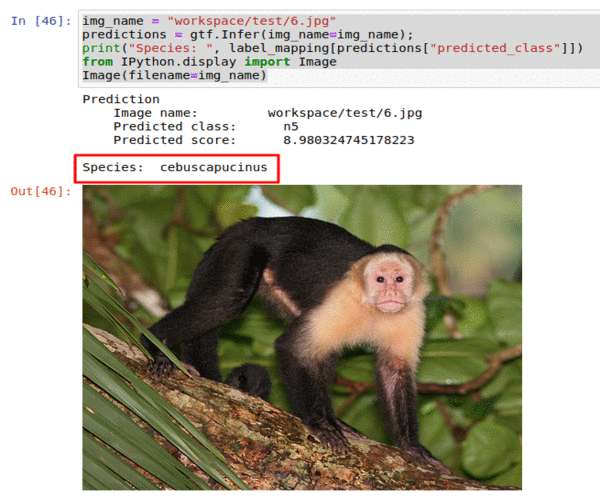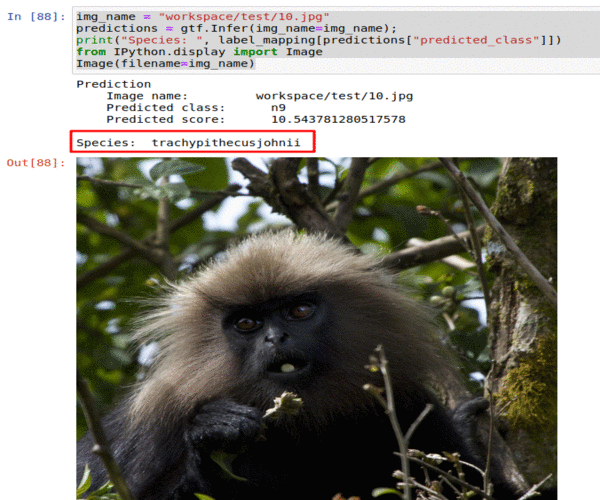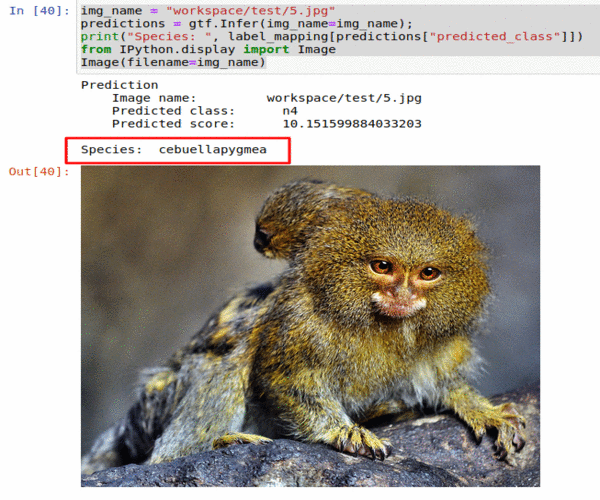
* Goal — To classify images into 10 different monkey species
* Application — Sorting a large database of images, tracking endangered species
* Details — 1K images spread over 10 classes
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
C) Stanford Dog Breed Dataset
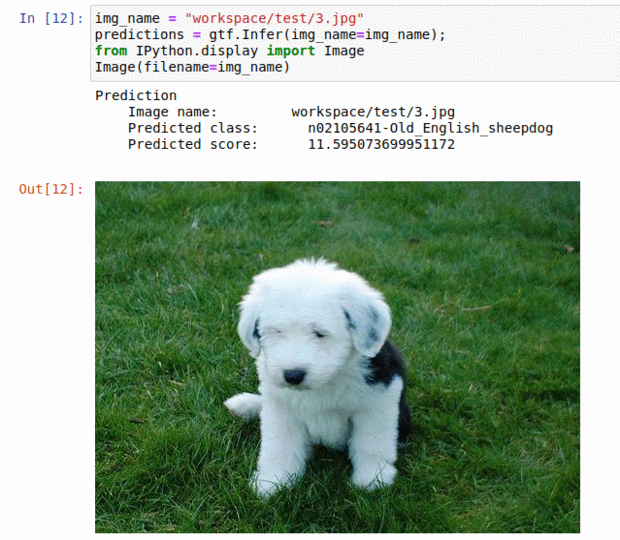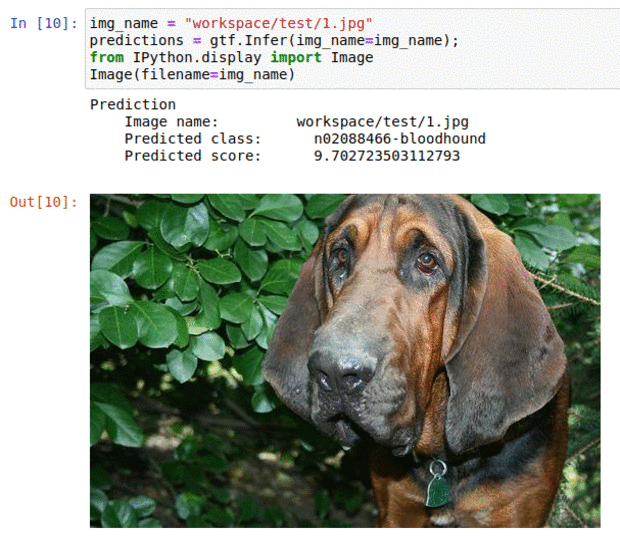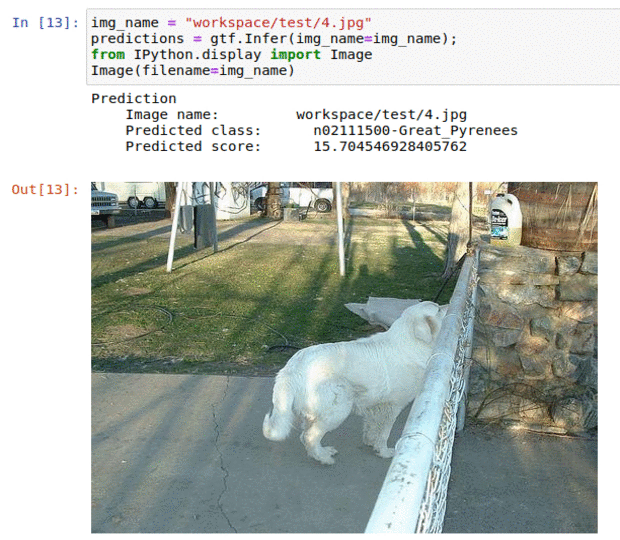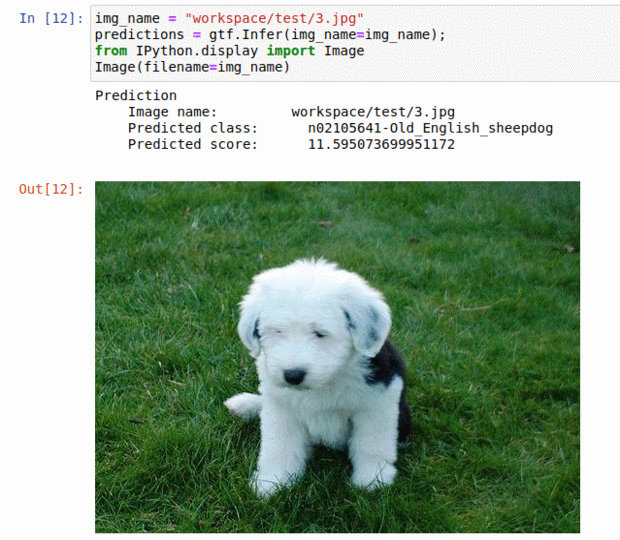
* Goal — To classify images into 120 different dog breeds
* Application — Sorting a large database of images, tracking different breeds
* Details — 20K+ images spread over 120 classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
D) Oregon Wildlife Classification Dataset
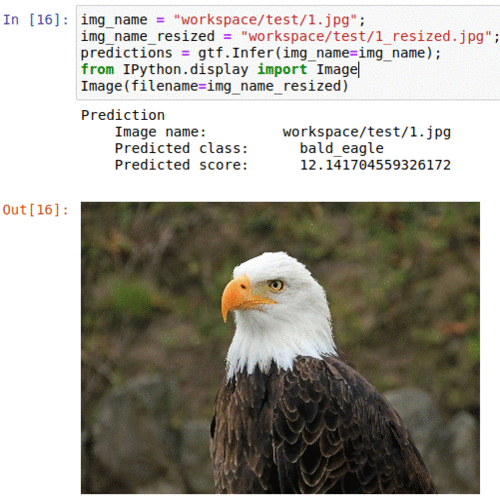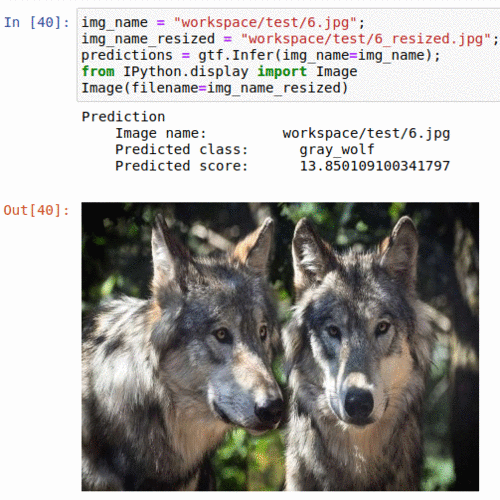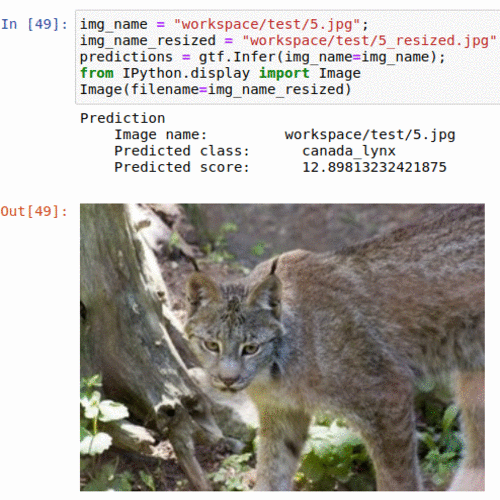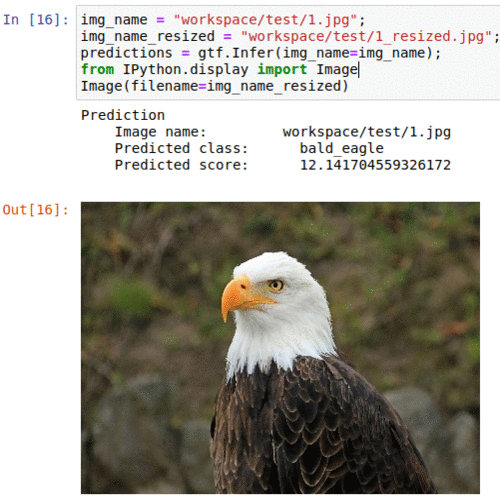
* Goal — To classify wild animals into 20 different types
* Application — Tracking animals in the wild
* Details — 10K+ images spread over 20 classes
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
E) 225 Bird Species Dataset
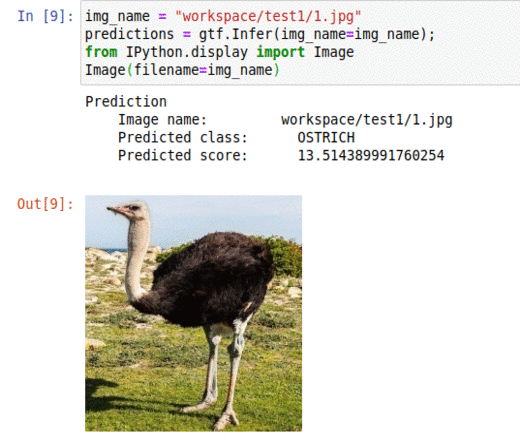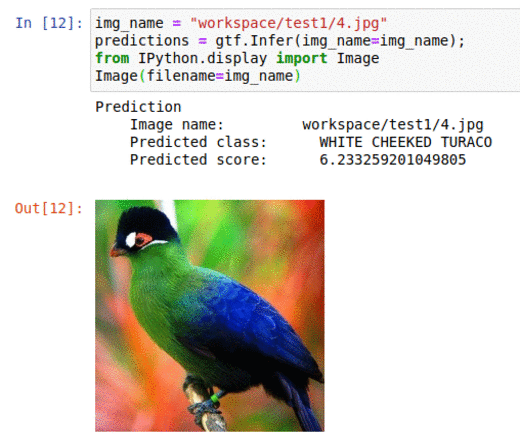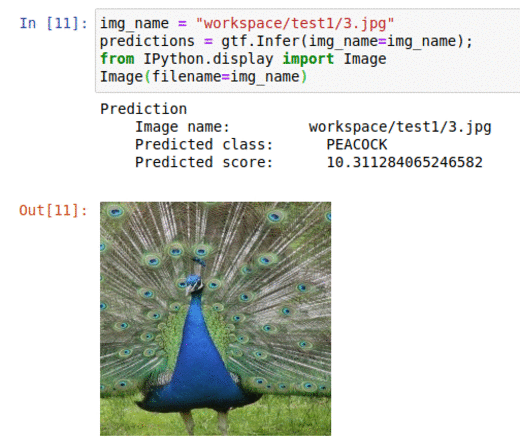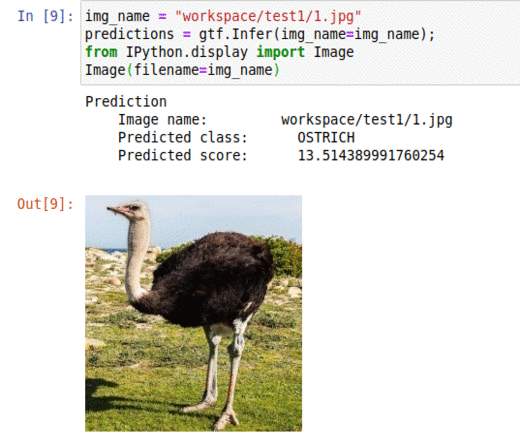
* Goal — To classify different bird species
* Application — Tracking birds in the wild, auto-tag images with specie types
* Details — 30K+ images spread over 225 classes
* How to utilize the dataset and create a classifier using Mxnets’s Resnet Pipeline
* Another such bird specie dataset and associated training code
F) Snake Species Classification Dataset
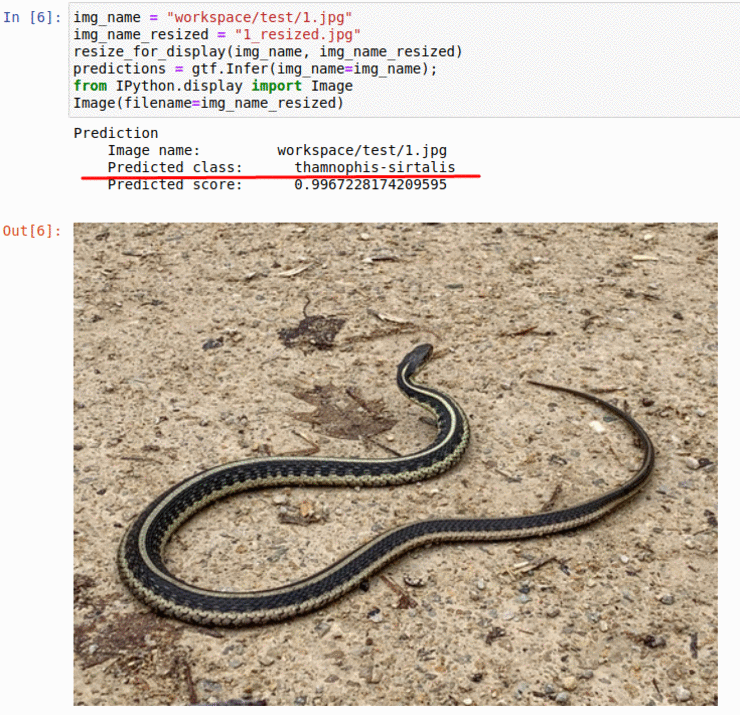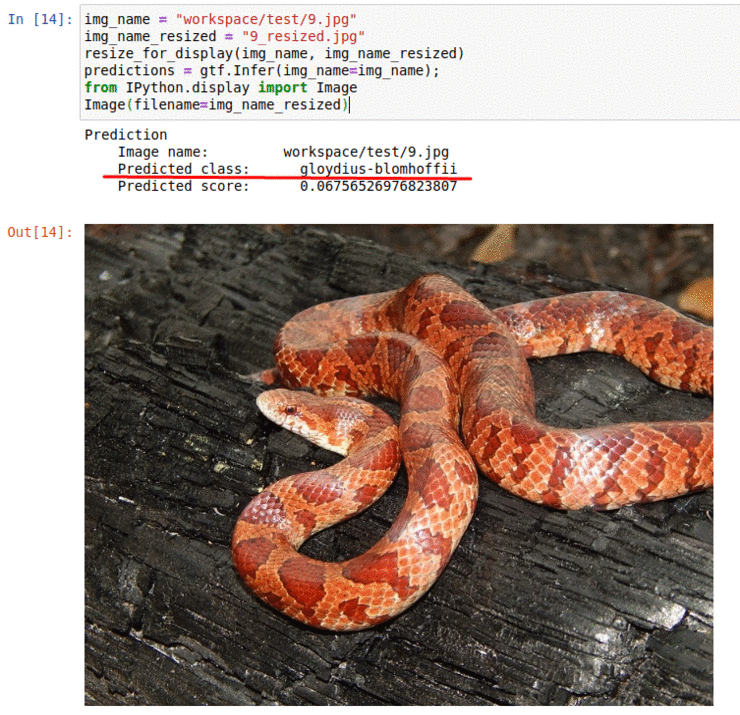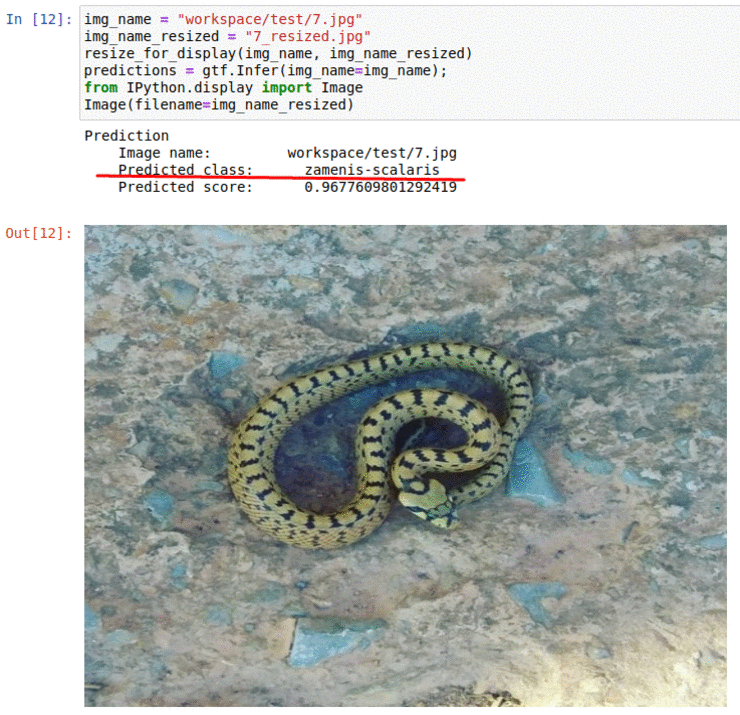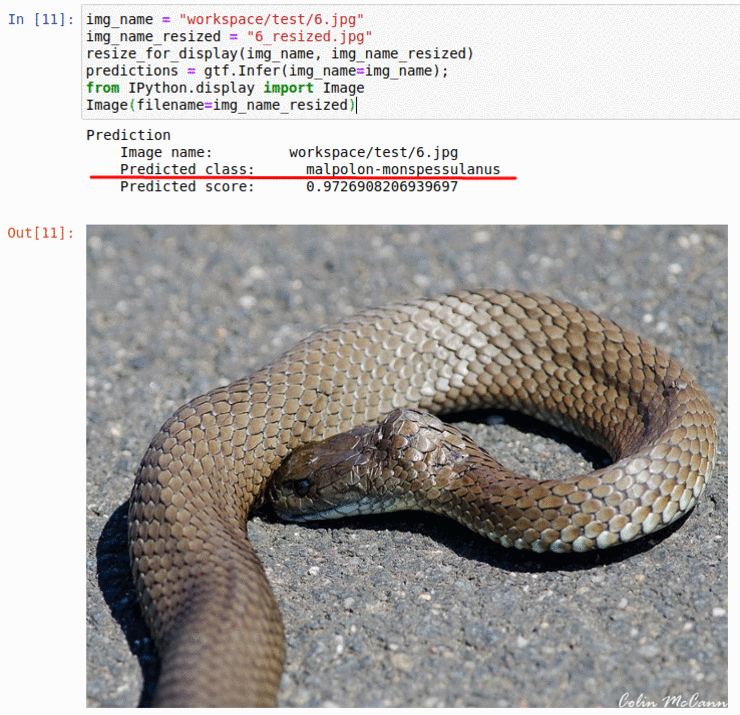
* Goal — To classify different snake species
* Application — Tracking snakes in the wild, monitoring endangered species
* Details — 240K+ images spread over 700+ classes
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
G) Butterfly Specie Classification Dataset
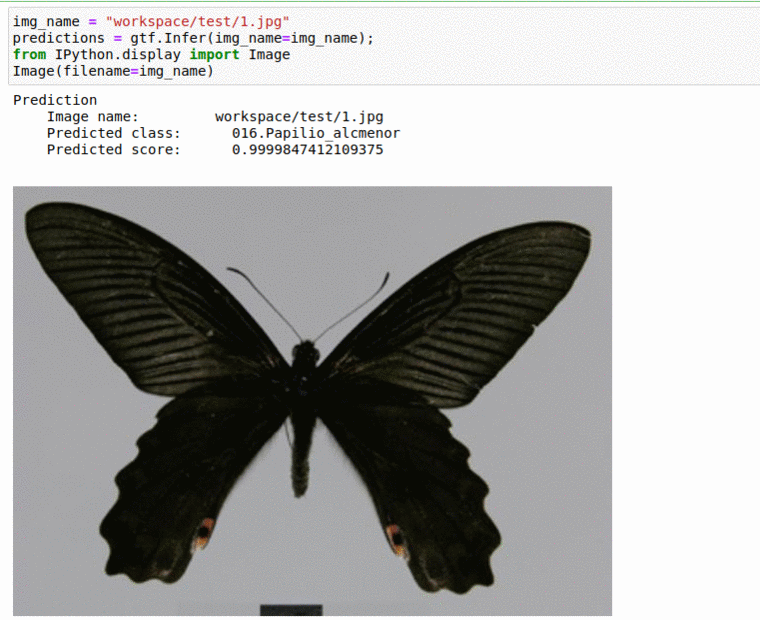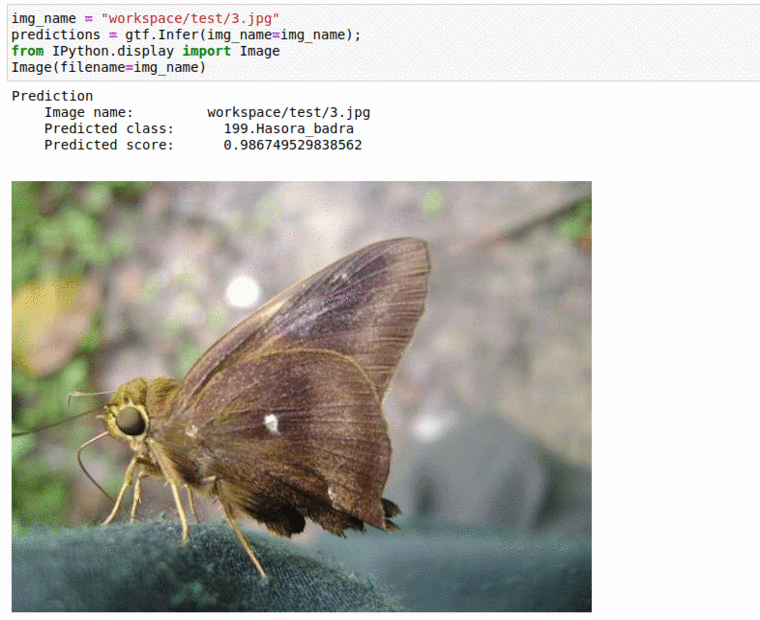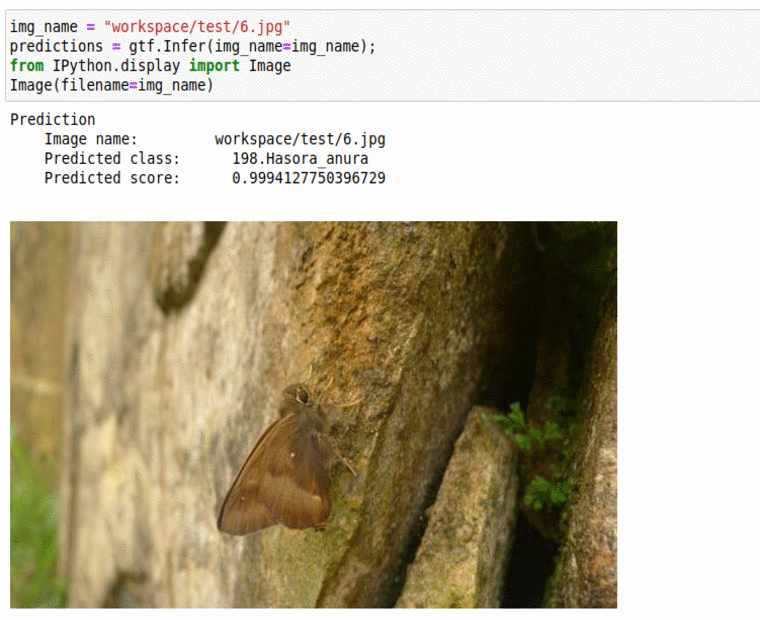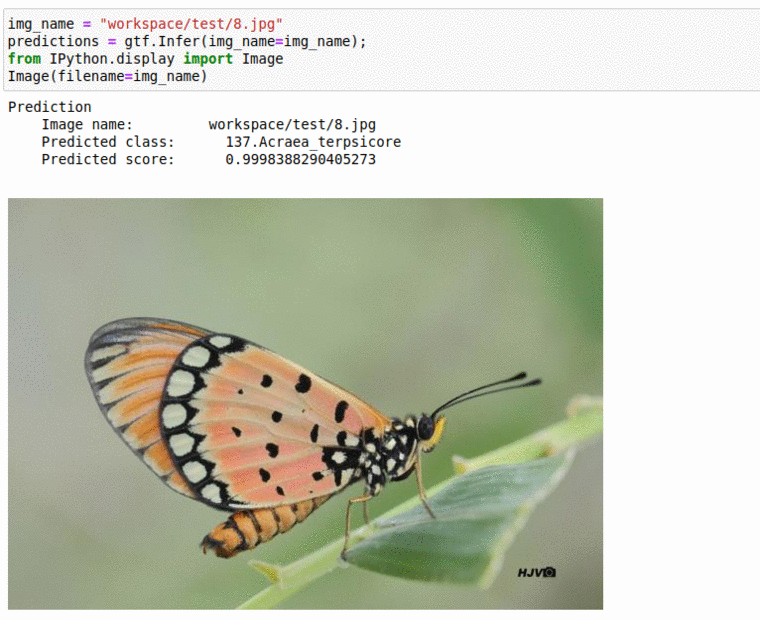
* Goal — To classify different butterfly species
* Application — Tracking butterfly in the wild, monitoring endangered species
* Details — 2K+ images spread over 50+ classes
* How to utilize the dataset and create a classifier using Mxnets’s Densenet Pipeline
Medical Imaging Related Datasets
A) Malarial Cellular Image Dataset

* Goal — To detect if a cell is infected with malaria or not
* Application — Early detection of presence of malaria in cells
* Details — 25K+ images with 2 different classes
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
B) Skin Cancer Mnist HAM10000 Dataset

* Goal — To detect if a cell is infected with malaria or not
* Application — Early detection of presence of malaria in cells
* Details — 10K images with 10+different classes
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
C) Blood Cell Sub-Type Classification
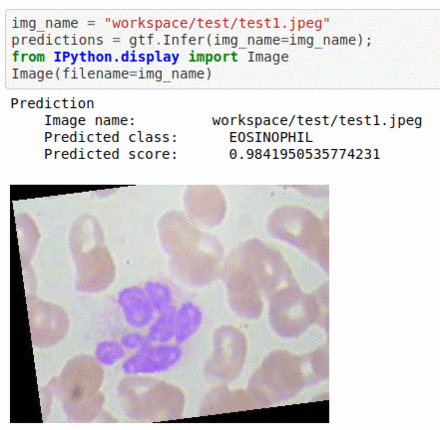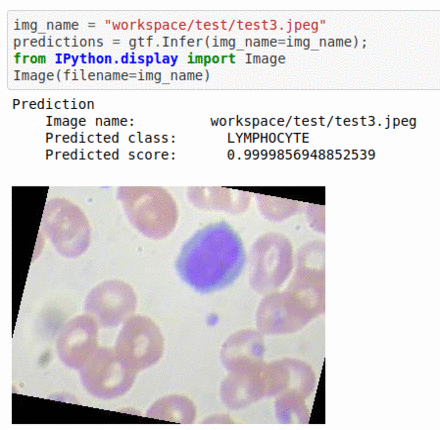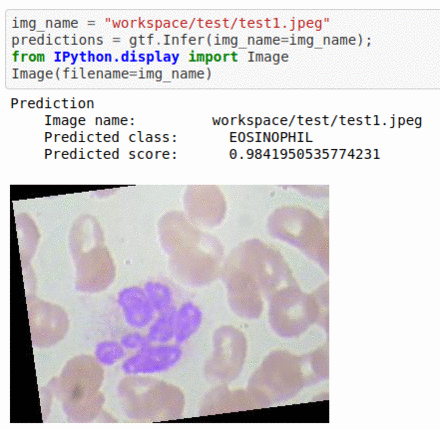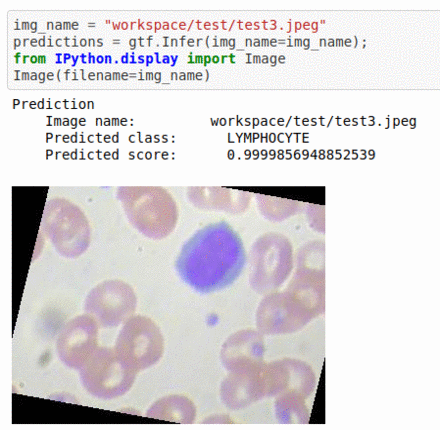
* Goal — To detect blood cell components
* Application — Automated classification helps in expediting certain pathological processes
* Details — 3K images for 4 classes of cell types — Eosinophil, Lymphocyte, Monocyte, and Neutrophil
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
D) Pneumonia Chest X-Ray Dataset
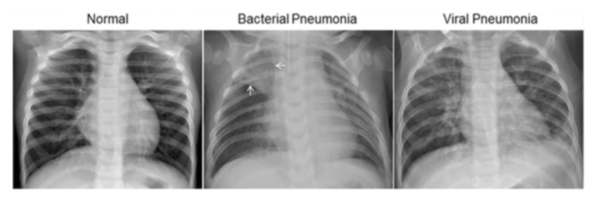
* Goal — To differentiate between a normal and pneumonia chest x-rays
* Application — Quick initial testing for early diagnosis
* Details — 5K+ images for 2 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
* Another related dataset is Covid Chest X-Ray Dataset and associated training code
E) Breast Histopathology Image Dataset
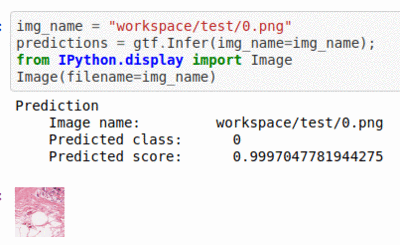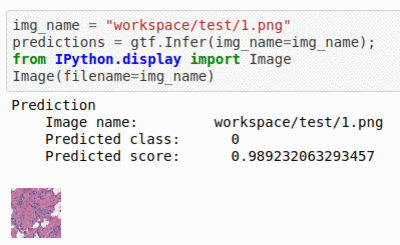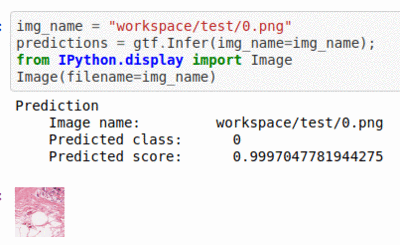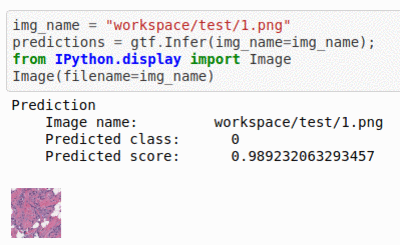
* Goal — To detect instance of Invasive Ductal Carcinoma
* Application — Quick initial testing for early diagnosis
* Details — 5K+ images for 2 different classes
* How to utilize the dataset and create a classifier using Keras’s Mobilenet V2 Pipeline
F) Retinal OCT Image Dataset
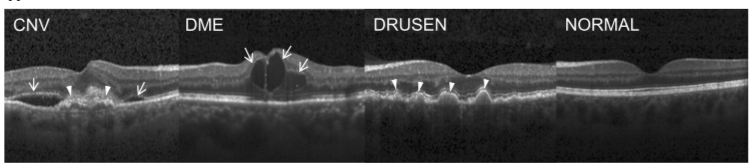
* Goal — To classify retinal oct images into 4 different retinal diseases— NORMAL, CNV (choroidal neovascularization), DME (diabetic macular edema), DRUSEN
* Application — Quick initial testing for early diagnosis
* Details — 80K+ images for 4 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
G) APTOS Blindness Detection Dataset
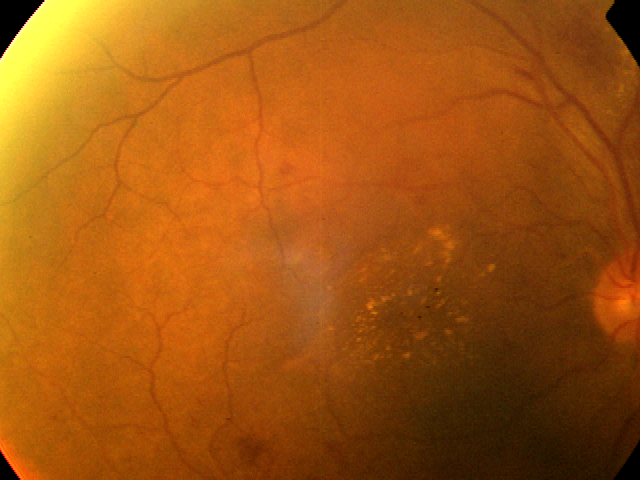
* Goal — To detect severity of blindness based on images captured using fundus photography
* Application — Quick initial testing for early diagnosis
* Details — 3.5K+ images for 5 different classes
* How to utilize the dataset and create a classifier using Keras’s Resnet Pipeline
* Another similar dataset is Diabetic Retinopathy Dataset and training code on it
H) Cataract Detection Dataset
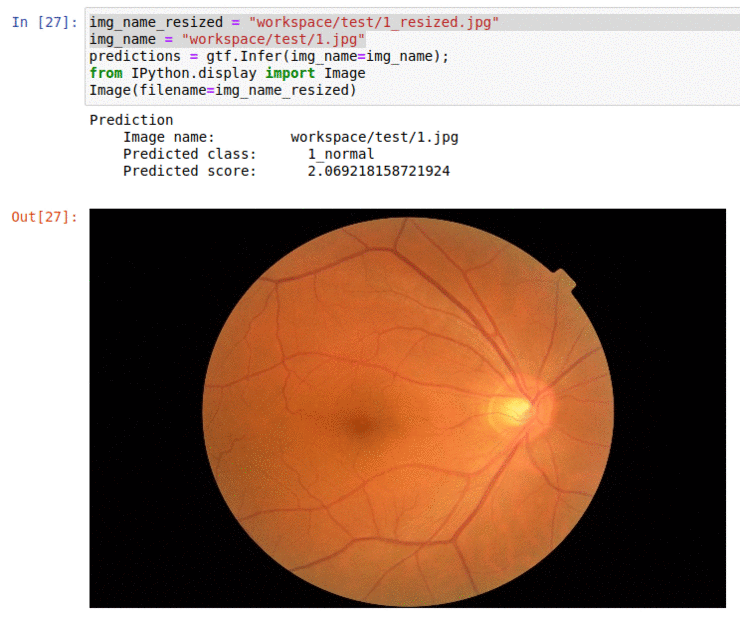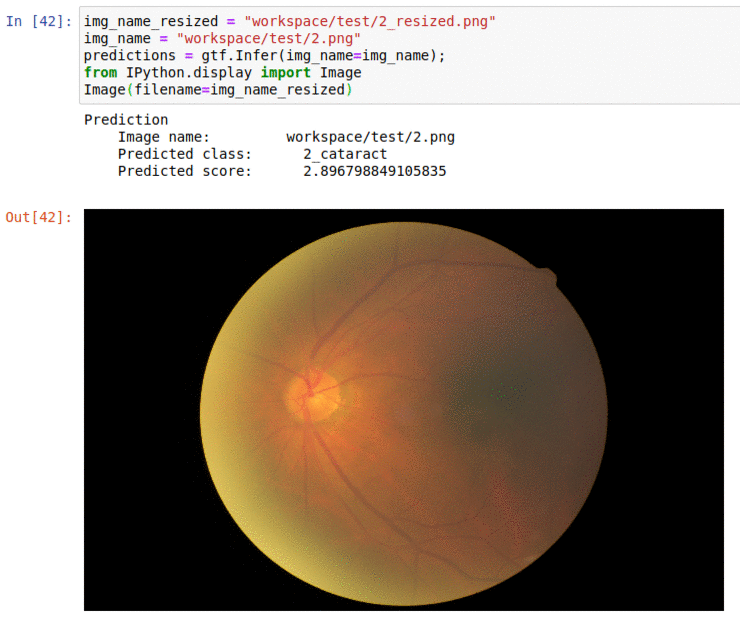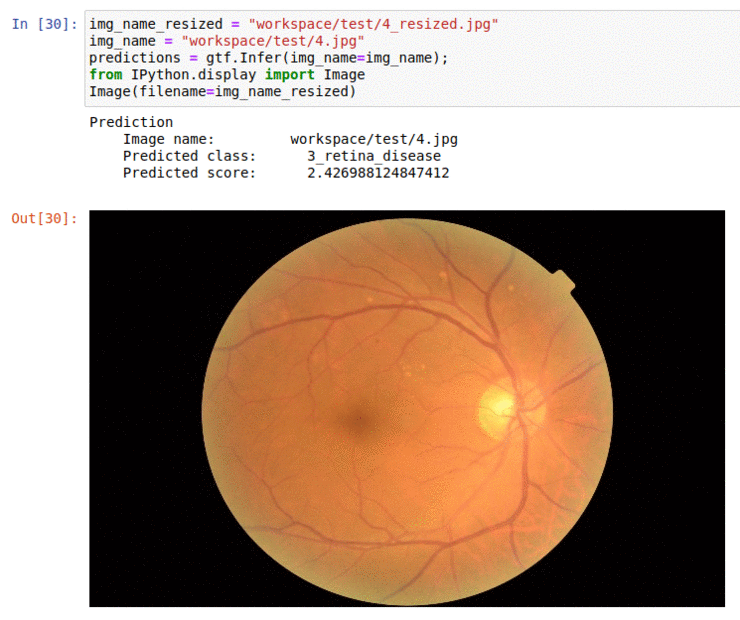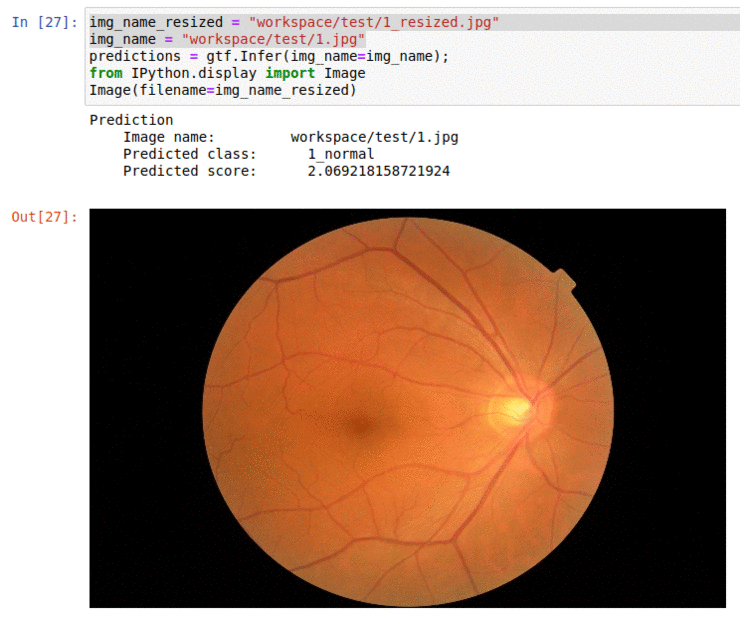
* Goal — To detect presence of cataract and glaucoma dataset
* Application — Quick initial testing for early diagnosis
* Details — 1K+ images for 4different classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
I) Intel and MobileODT Cervical Cancer Dataset

* Goal — To detect presence of cervical cancer
* Application — Cervical cancer is easy to prevent if caught in its pre-cancerous stage
* Details — 1K images for 3 classes — type-1, type-2, type-3
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
J) Human Protein Atlas Image Classification Dataset
* Goal — To predict protein organelle localization. The dataset comprises 27 different cell types of highly different morphology, which affect the protein patterns of the different organelles.
* Application — Identify a protein’s location(s) from a high-throughput image
* Details — 120K images for 27 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
K) Runmila AI Institute & minoHealth AI Labs Tuberculosis Classification Dataset
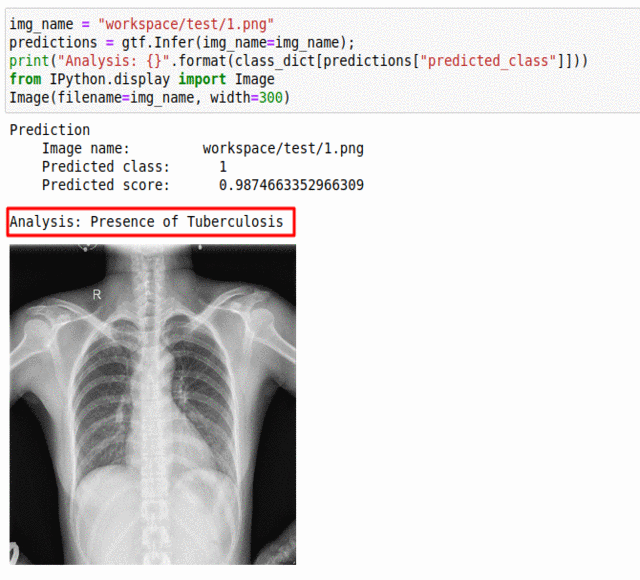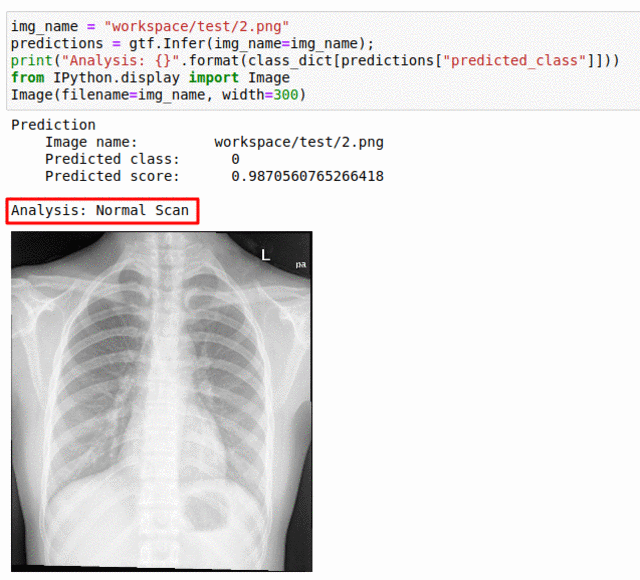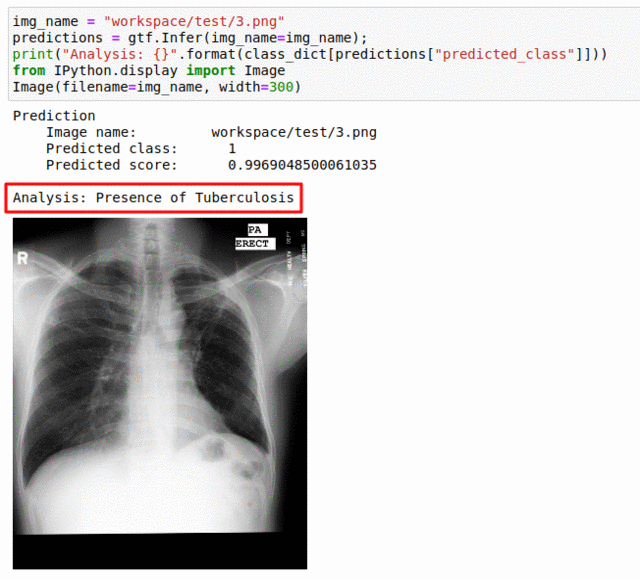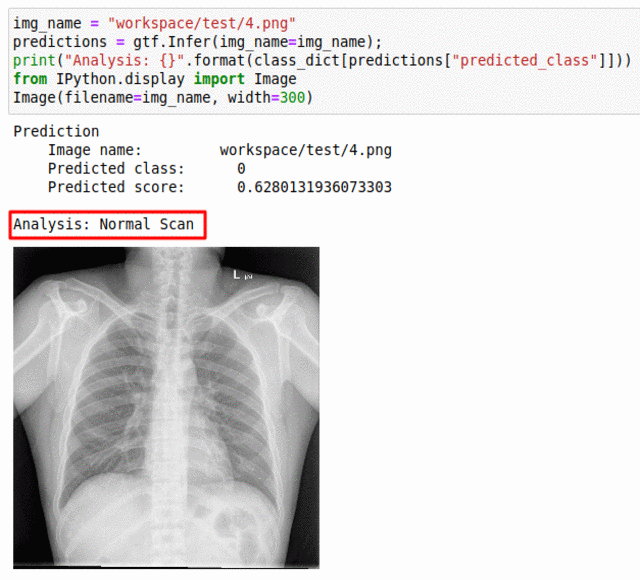
* Goal — To predict presence of tuberculosis in Chest X-Ray scans.
* Application — Quick detection can help with early diagnosis
* Details — 1K images for 2 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
Retail and Groceries Related Datasets
A) Food vs Non-Food Image Dataset
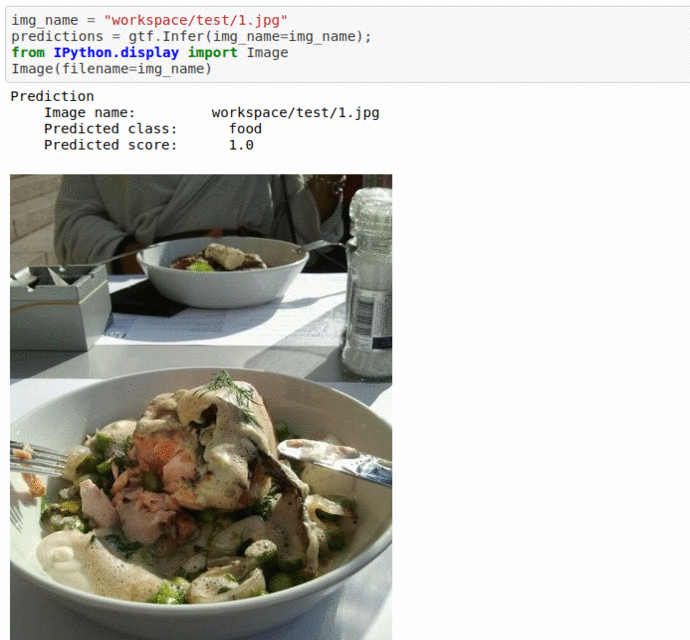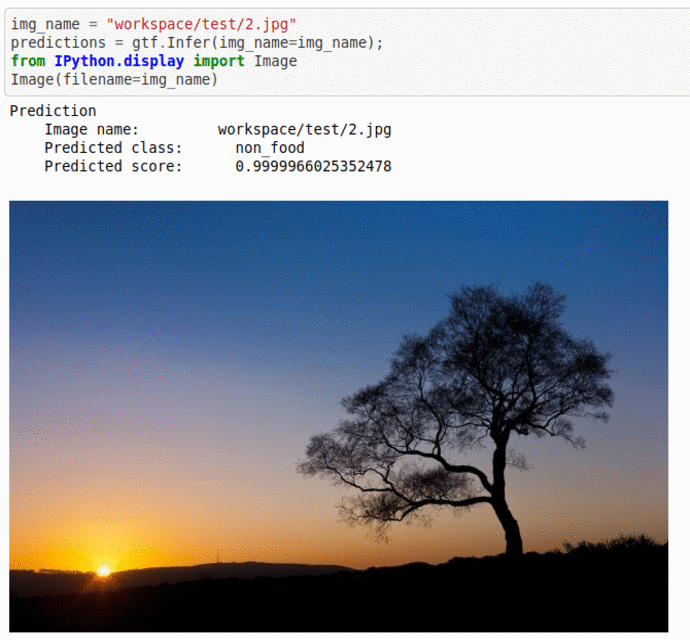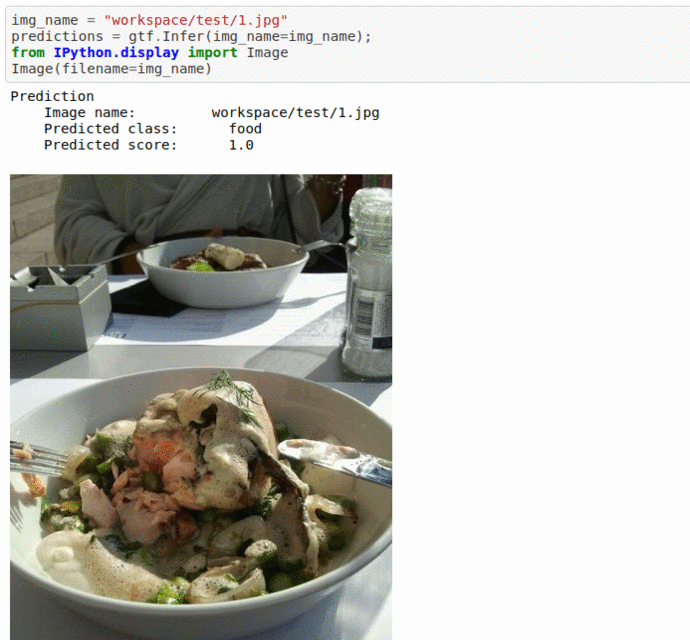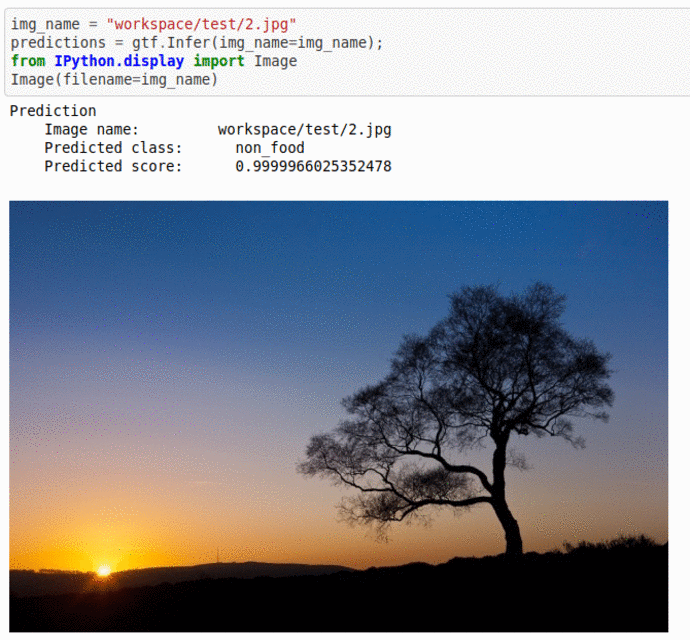
* Goal — To classify images with presence of food or not.
* Application — Auto-tag images for search and retrieval
* Details — 5K images for 2 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Mobilenet V3 Pipeline
B) Freiburg Groceries Dataset
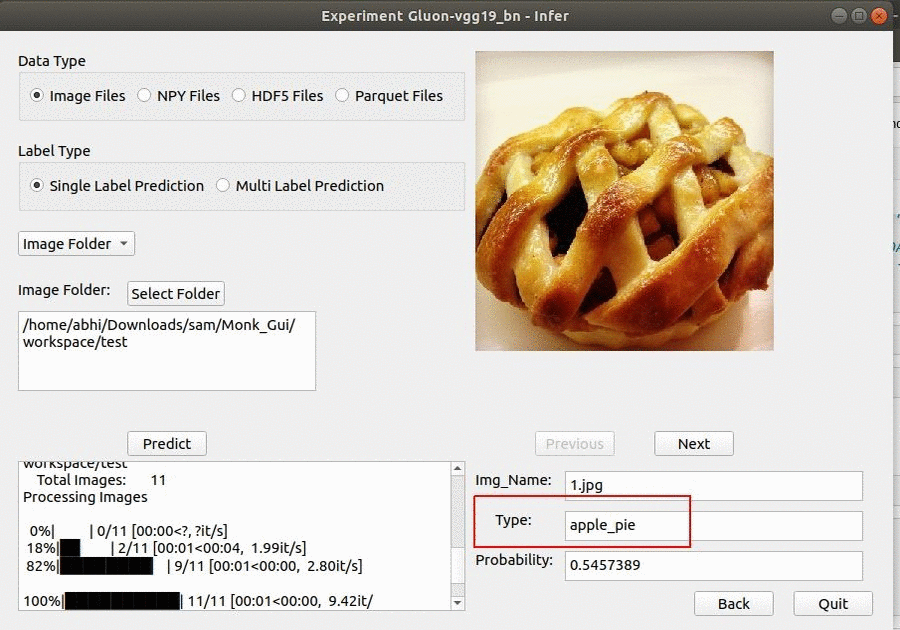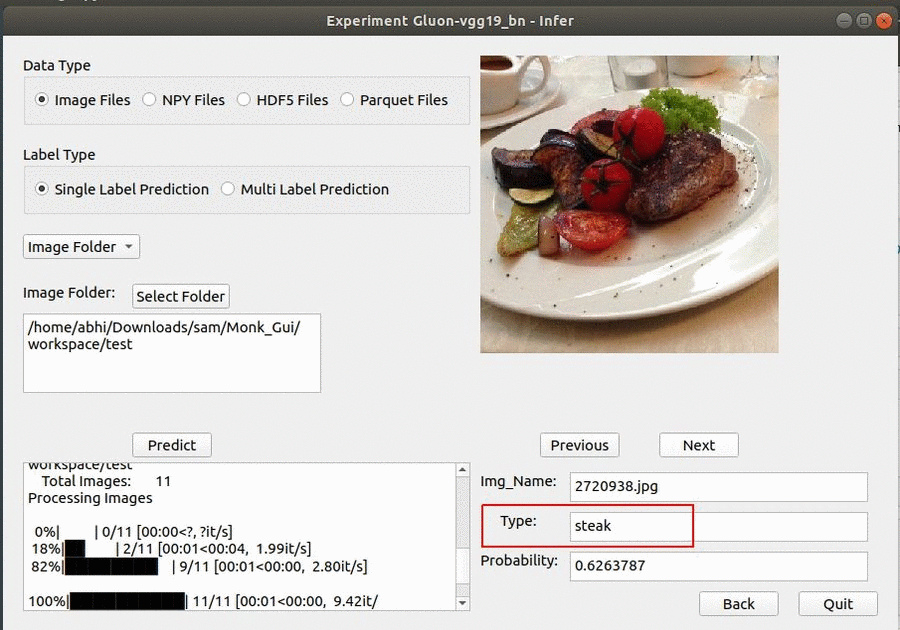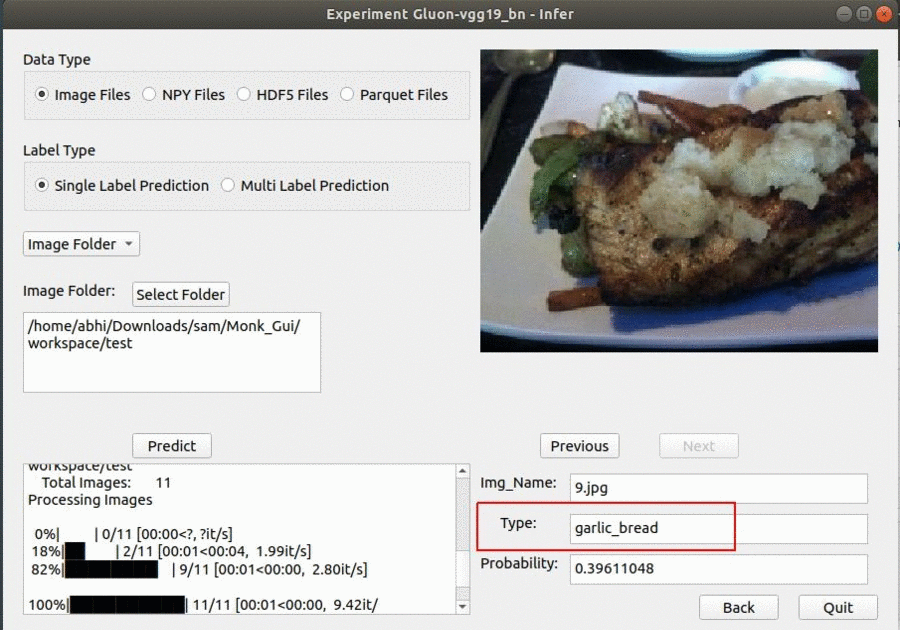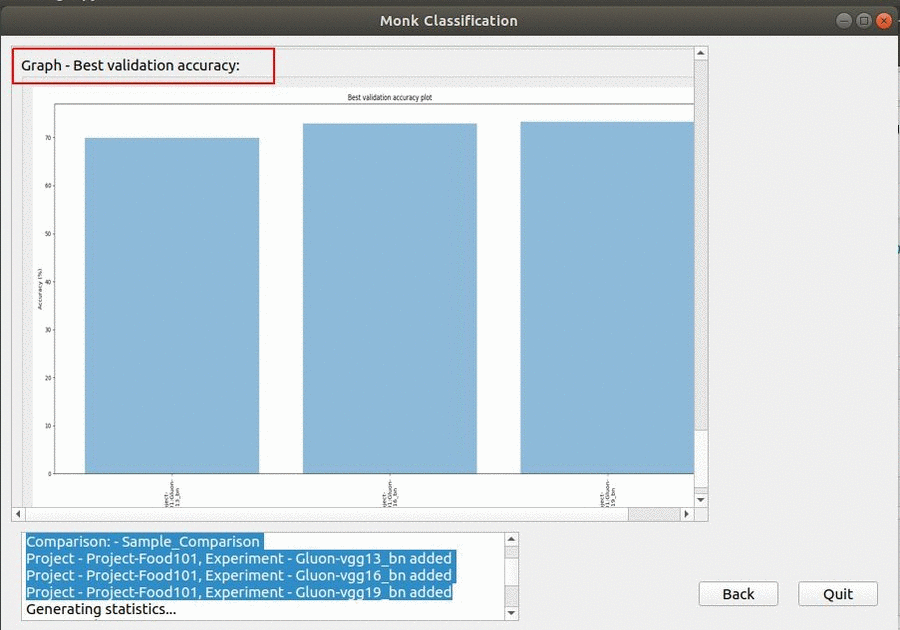
* Goal — To classify different grocery items in the image.
* Application — Auto-tag images for quick-checkout
* Details — 5K images for 25 different classes of products
* How to utilize the dataset and create a classifier using Mxnet’s Mobilenet V3 Pipeline
C) Fashion Product Image Dataset
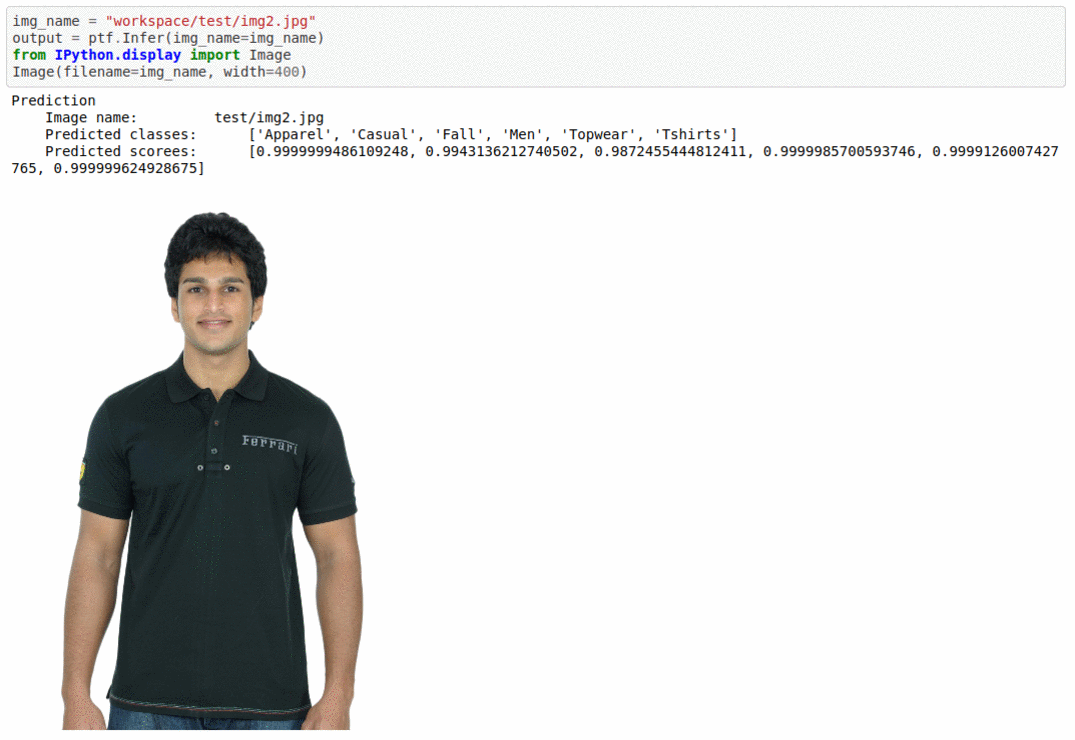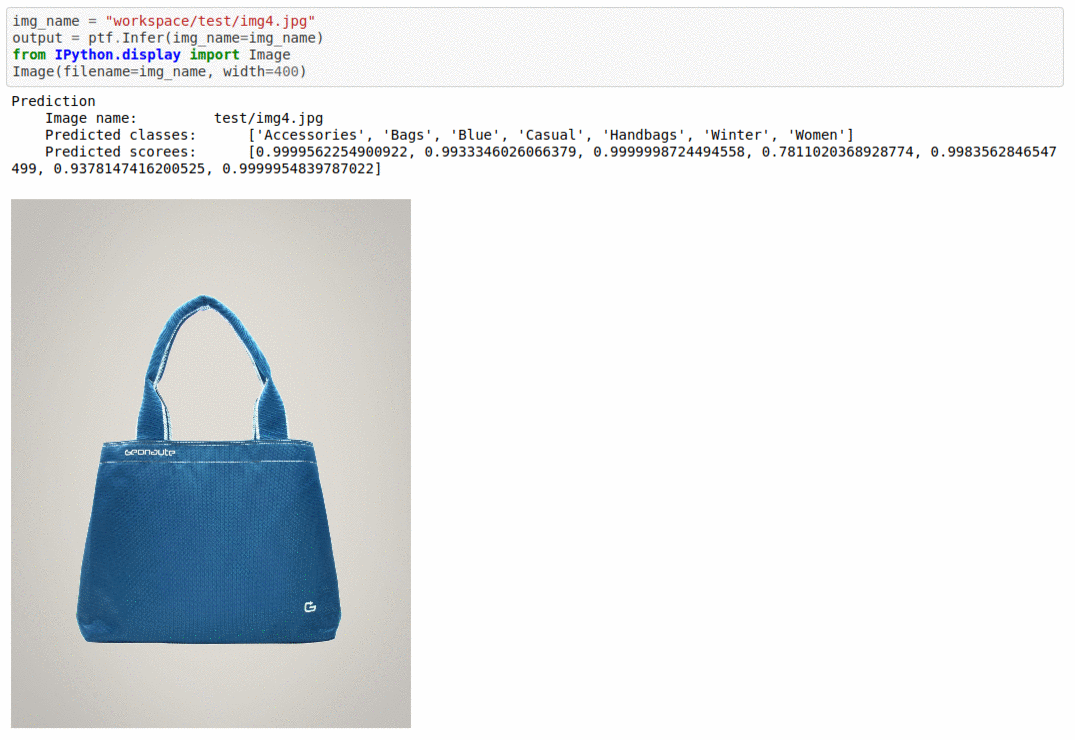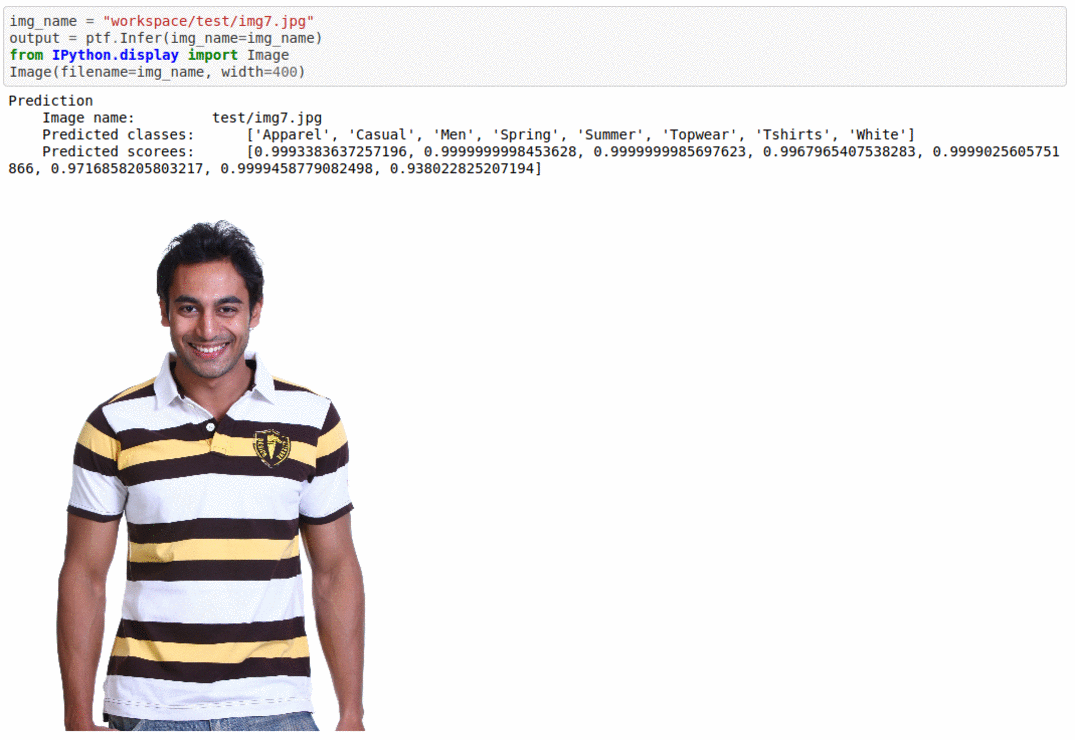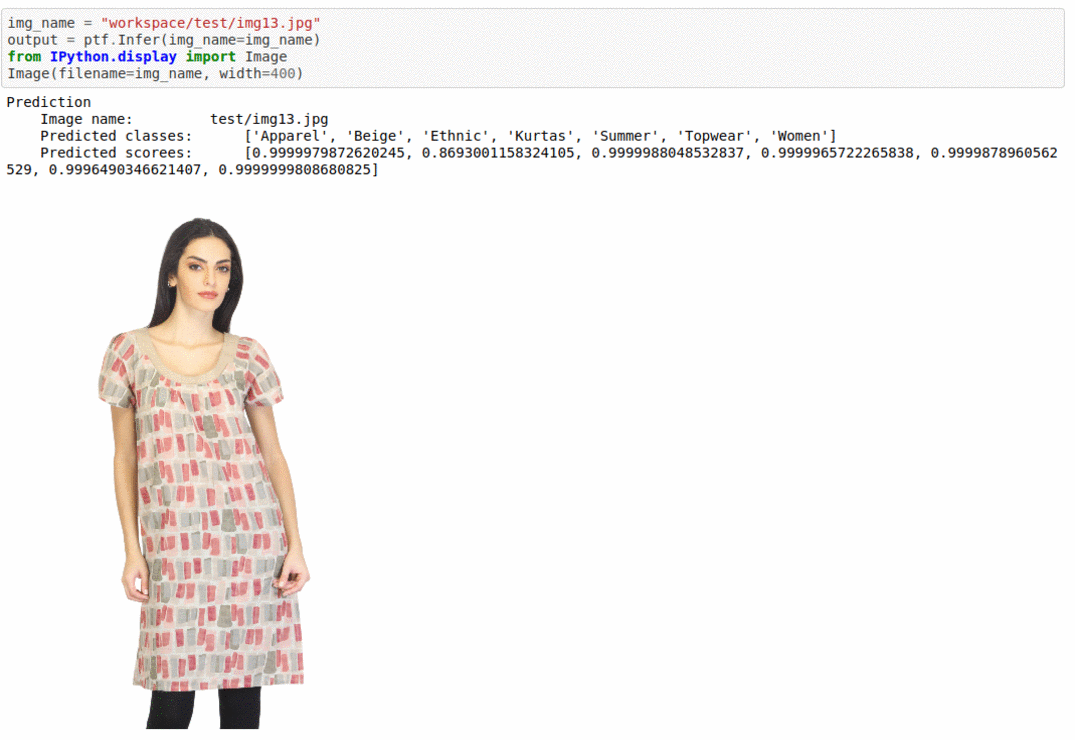
* Goal — To add multiple tags to different fashion product items in the image.
* Application — Auto-tag images for better search and retrieval
* Details — 44K images with multiple tags per images
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
D) Apparel Images Dataset

* Goal — To classify different apparel items in the image.
* Application — Auto-tag images for better search and retrieval
* Details — 10K images with 20+ single label tags
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
E) Zalando Store Fashion Image Dataset

* Goal — To classify different clothing items in the image.
* Application — Auto-tag images for better search and retrieval
* Details — 10K+ images spread over 6 different types of clothing
* How to utilize the dataset and create a classifier using Keras’s VGG-Net Pipeline
F) Food-101 Dataset
* Goal — To classify different food items in images.
* Application — Auto-tag images for social media posts
* Details — 101K images, 1K images for each of the 101 different classes
* How to utilize the dataset and create a classifier using Mxnet’s VGG-Net Pipeline
Agriculture Related Dataset
A) Rice (Leaf) Disease Detection Dataset

* Goal — To detect different rice plant diseases.
* Application — Early and accurate detection is essential to take necessary measures in saving the rest of the crop
* Details — 2K+ images spread over 3 types of diseases — Brown spots, Hispa, and Leaf Blast
* How to utilize the dataset and create a classifier using Pytorch’s VGG-Net Pipeline
B) Broad Leaved Dock Image Dataset
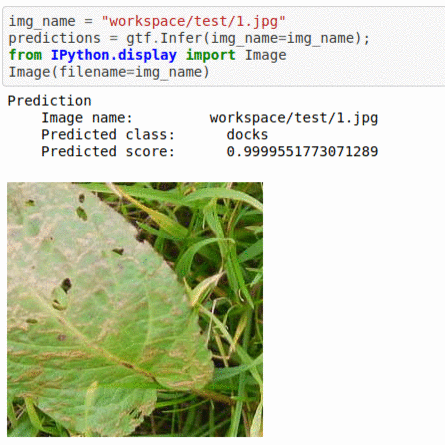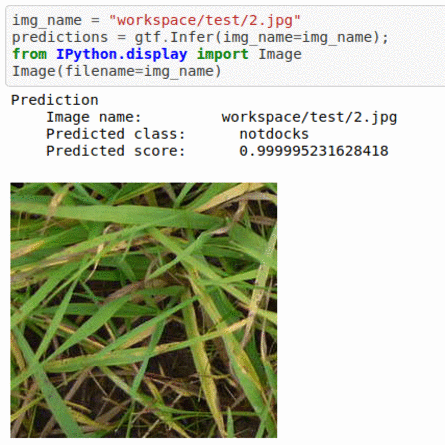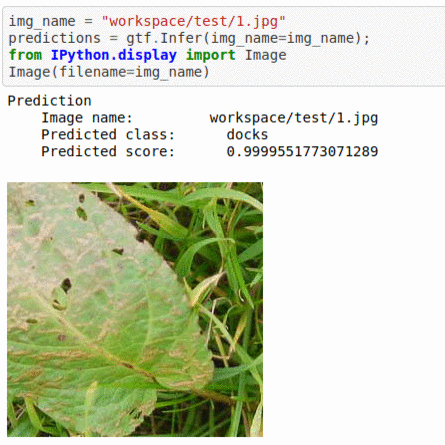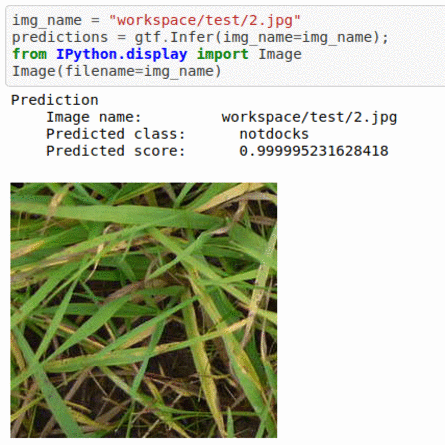
* Goal — To detect presence of broad leaved docks in images.
* Application — Automated detection helps weed sprayer target right locations
* Details — 2K+ images with 2 different classes
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
C) DeepWeeds Weed type Classification Dataset
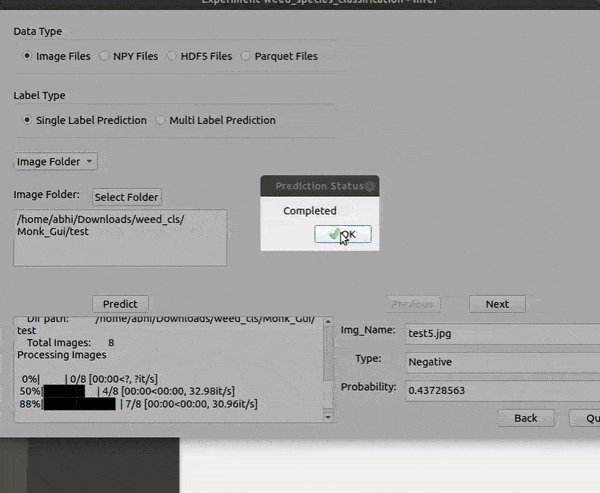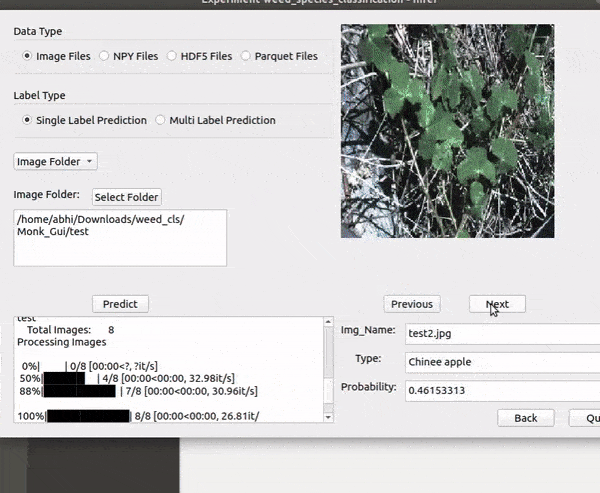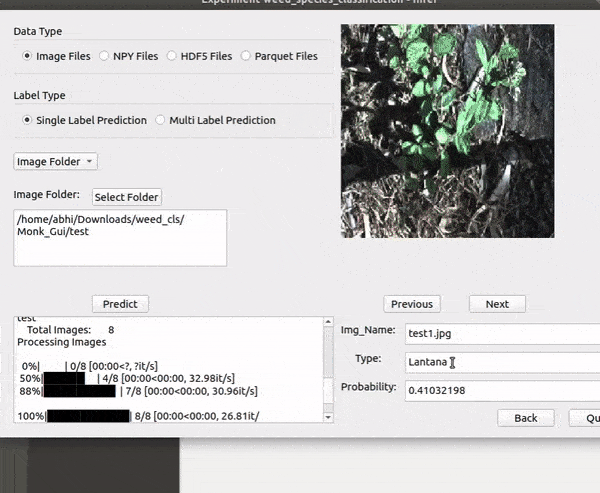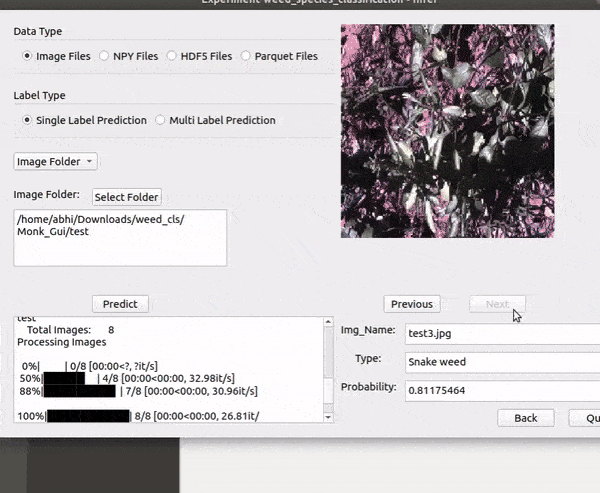
* Goal — To recognize different weed species.
* Application — Automated detection helps weed sprayer target right locations
* Details — 17K+ images with 8 different classes of weed.
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
D) Leaf Snap Dataset

* Goal — To recognize different plant species.
* Application — Automated visual recognition helps with monitoring different species as per the need
* Details — 500+ images with 10+ different classes of plant species.
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
E) Plant Pathology FGVC7 Dataset
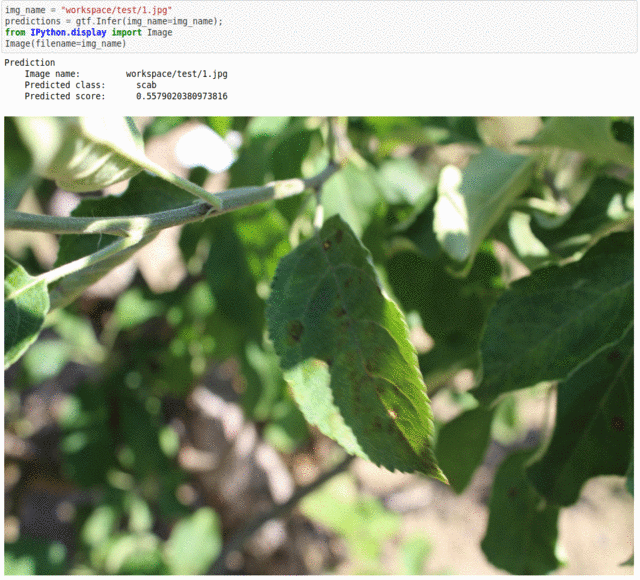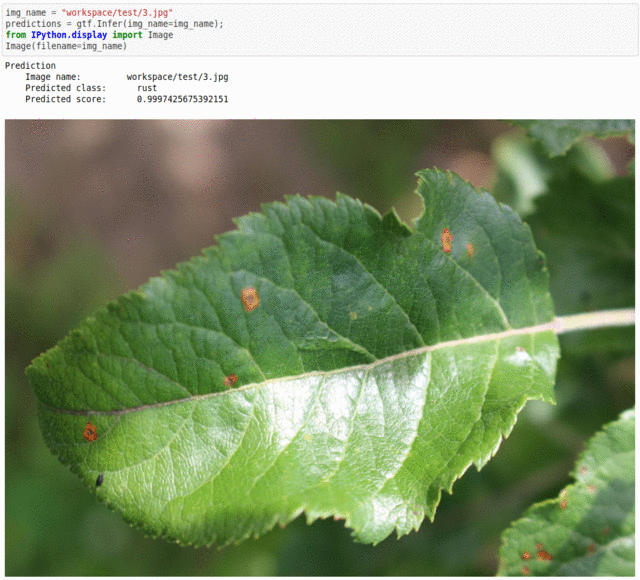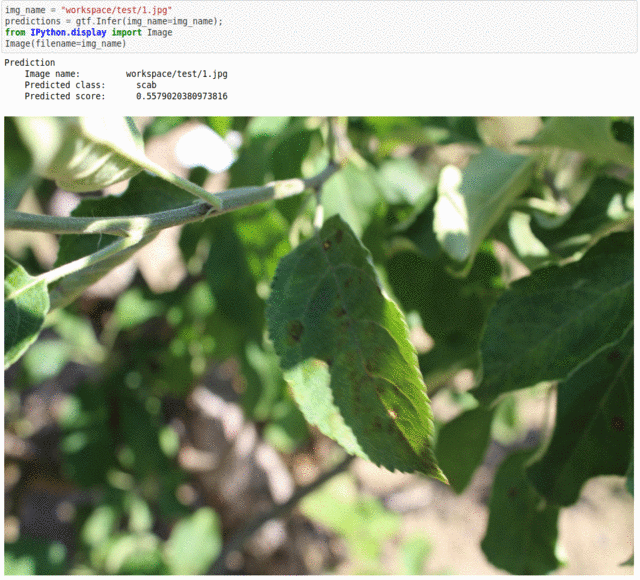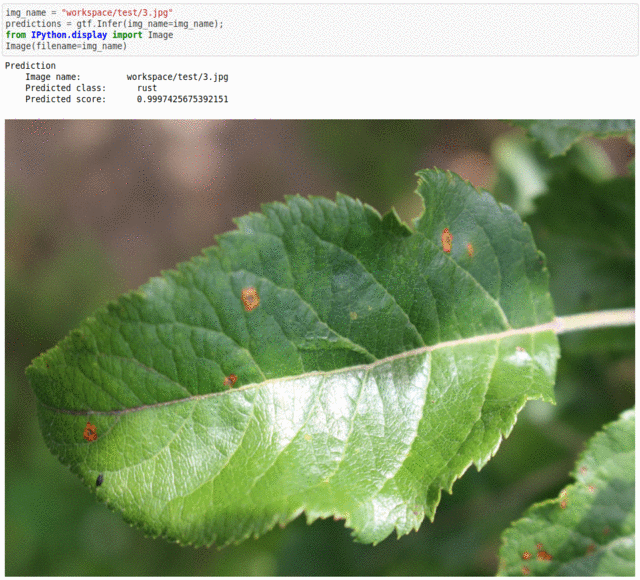
* Goal — To recognize plant diseases.
* Application — Early and accurate detection is essential to take necessary measures in saving the rest of the crop
* Details —3.5K+ images with 5+ different classes of plant diseases.
* How to utilize the dataset and create a classifier using Keras’ Resnet Pipeline
F) Aerial Cactus Identification Dataset

* Goal — To detect presence of cactus spread in satellite images.
* Application — Helps with understanding spread of cacti over arid and desert regions
* Details — 17K+ 32×32 patch images with 2 different classes.
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
G) Invasive species monitoring dataset
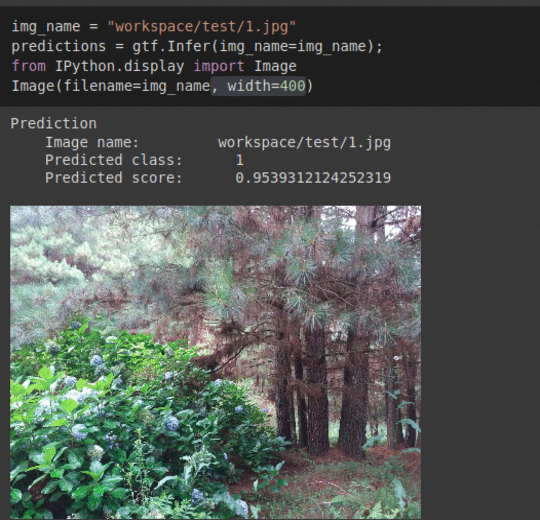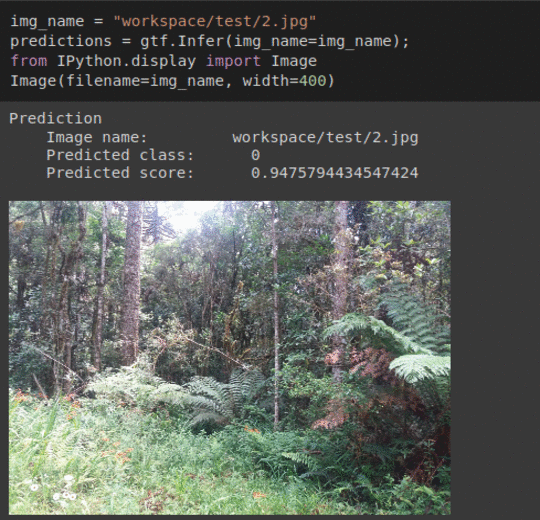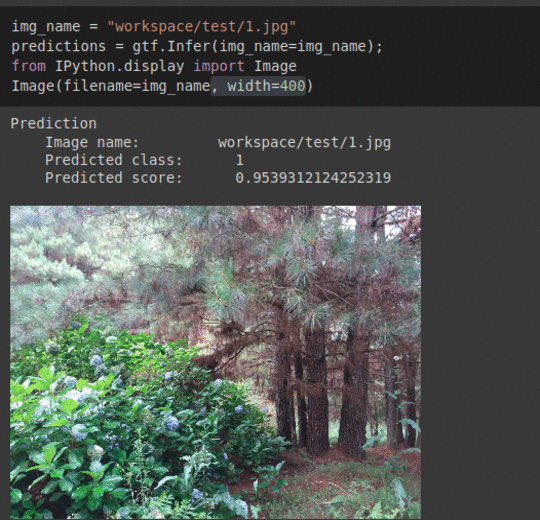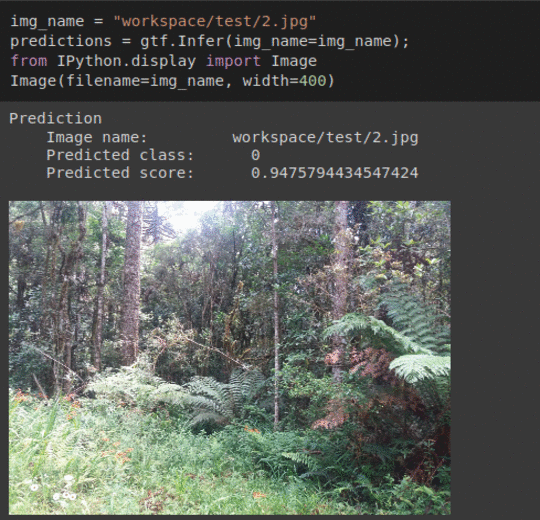
* Goal — To detect presence of invasive weed species Hydrangea in forests.
* Application — Early detection helps with taking proper measure to keep the forest ecosystem in balance
* Details —2.5K+ images with 2 different classes.
* How to utilize the dataset and create a classifier using Keras’ Resnet Pipeline
H) Plant Seedling Dataset

* Goal — To classify different plant species with images of seedlings and find presence of weed.
* Application — Early detection helps with taking proper measures to remove the unwanted plants
* Details — 2.5K+ images with 12 different classes of plants.
* How to utilize the dataset and create a classifier using Keras’ Mobilenet V2 Pipeline
I) CGIAR Plant Disease Classification Dataset
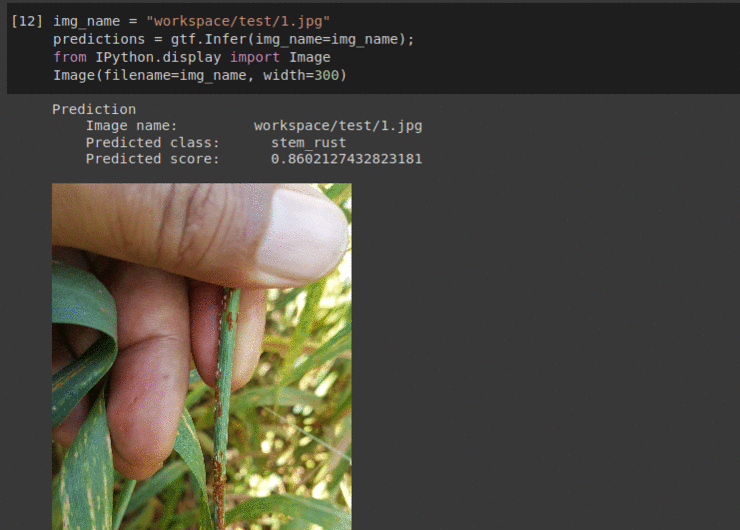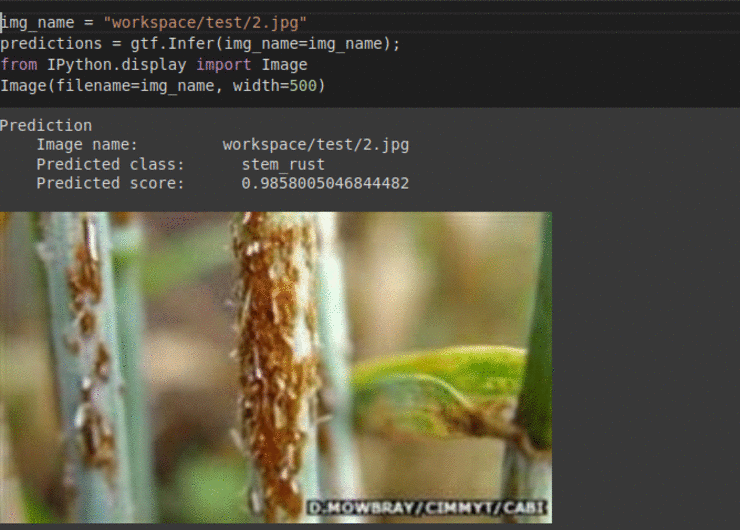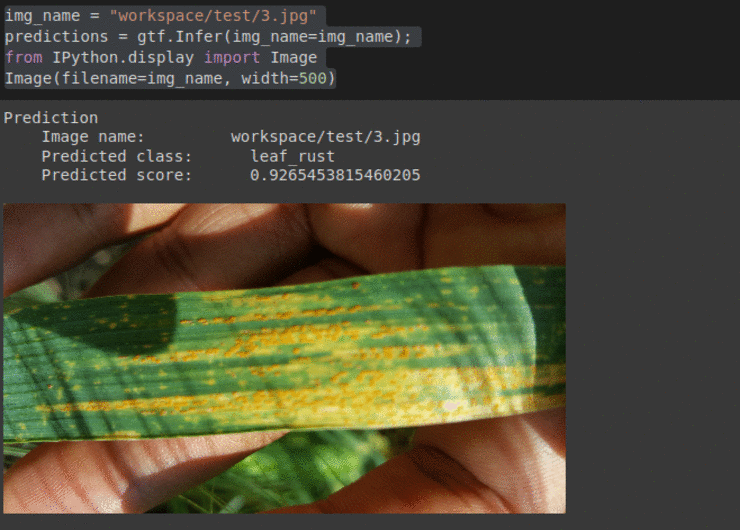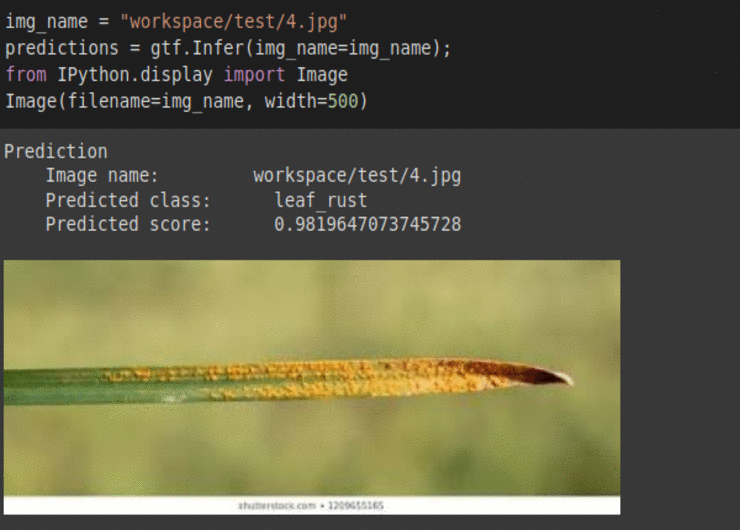
* Goal — To detect different leaf and stem diseases.
* Application — Early detection helps with taking proper measures to save rest of the vegetation
* Details — 500+images with 4 different classes of diseases.
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
J) Plant Village Plant Disease Classification
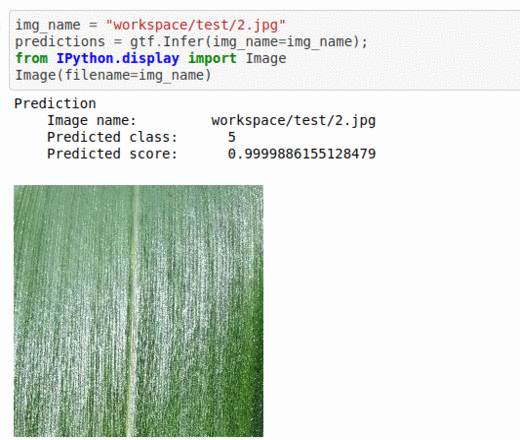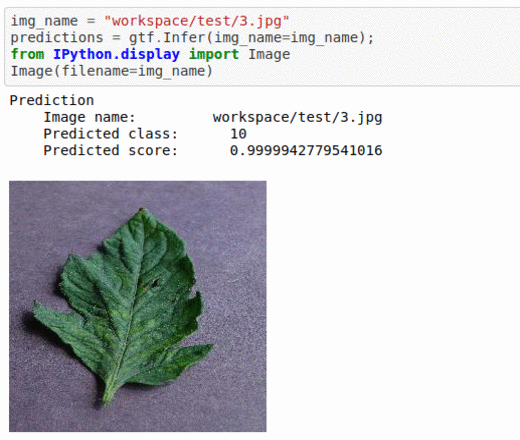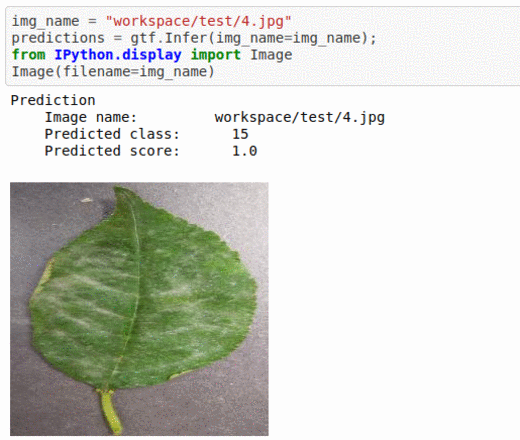
* Goal — To detect different leaf and stem diseases.
* Application — Early detection helps with taking proper measures to save rest of the vegetation
* Details — 1K+images with 10 different classes of diseases.
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
K) CGIAR Wheat Growth Prediction Dataset
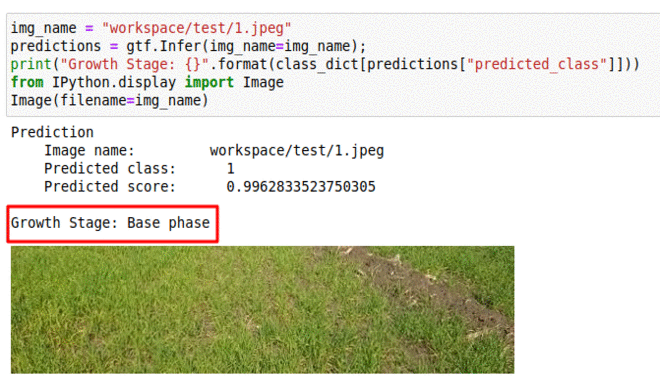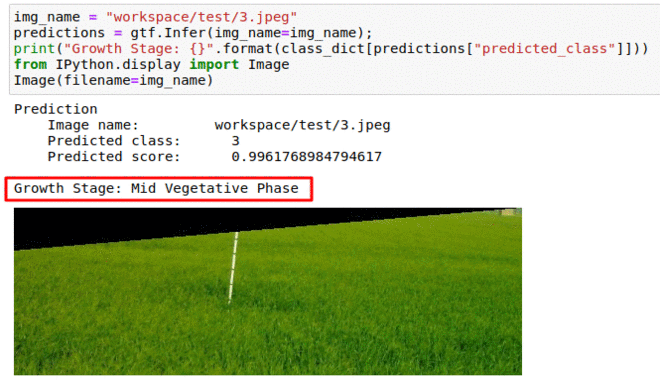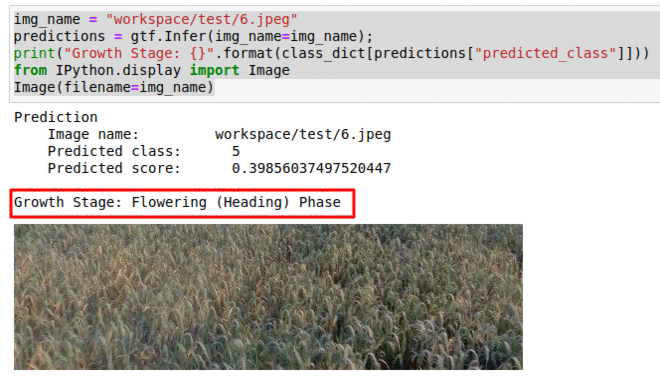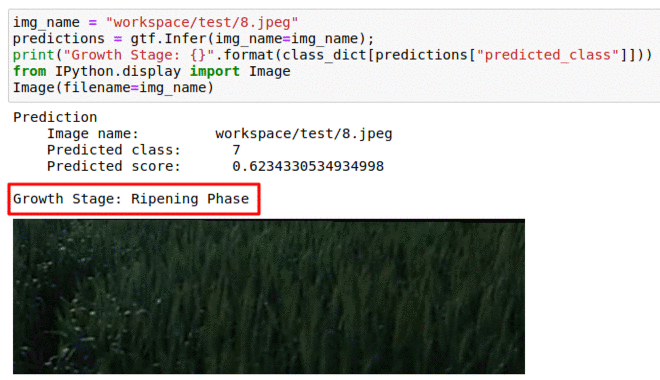
* Goal — To monitor different stages of wheat growth.
* Application — Helps to keep track of yield
* Details — 15K+images with weekly labelled stages of crop growth.
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
L) Swedish Leaf Type Classification Dataset
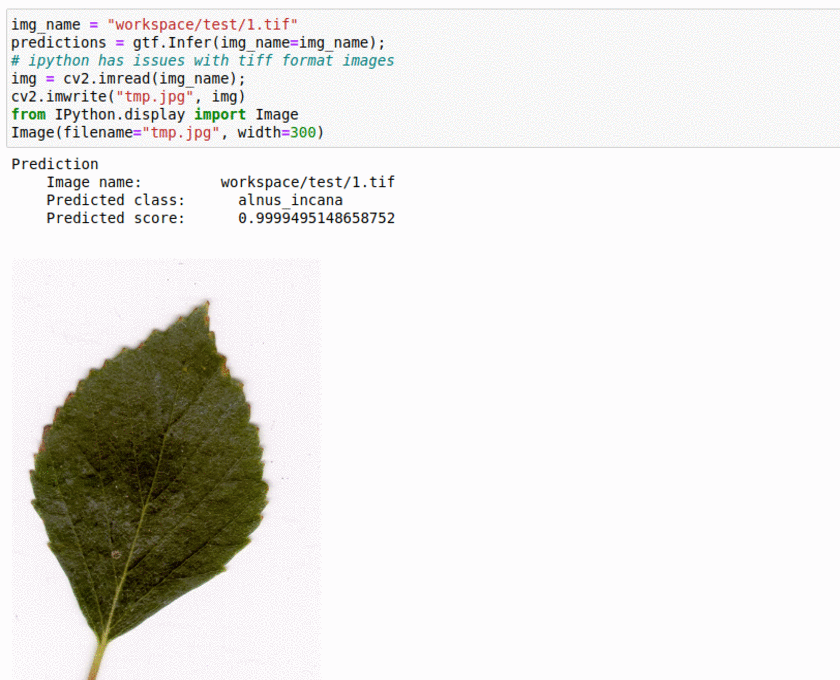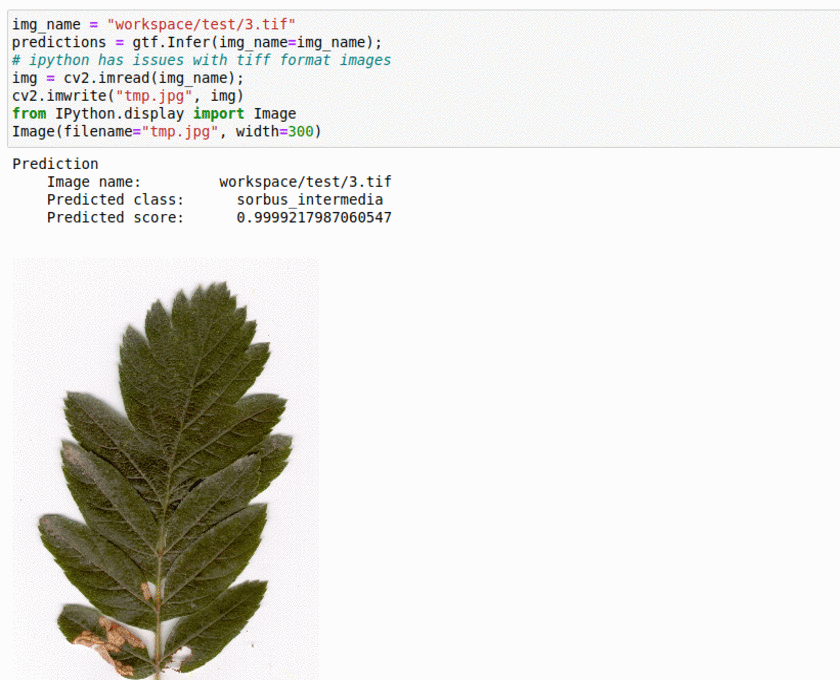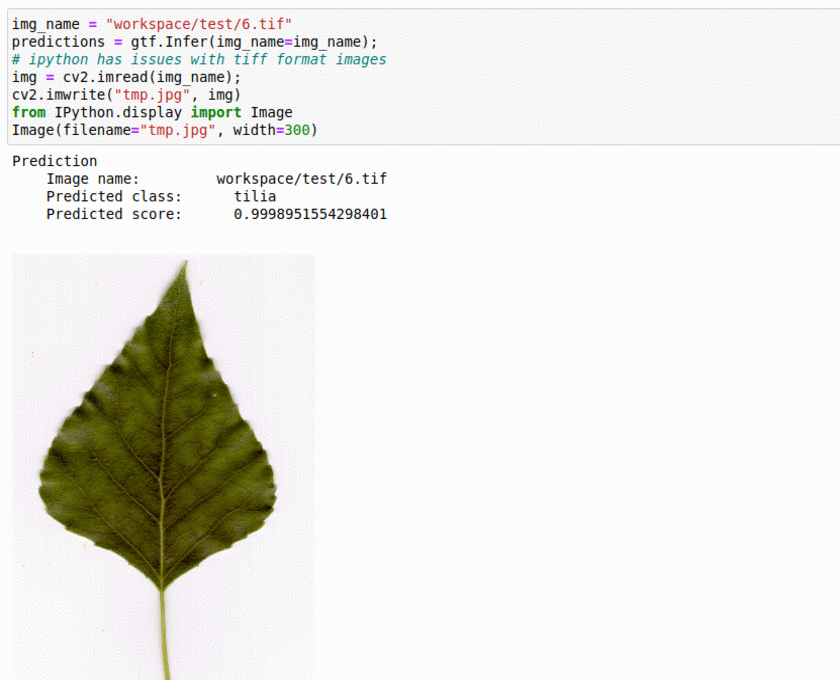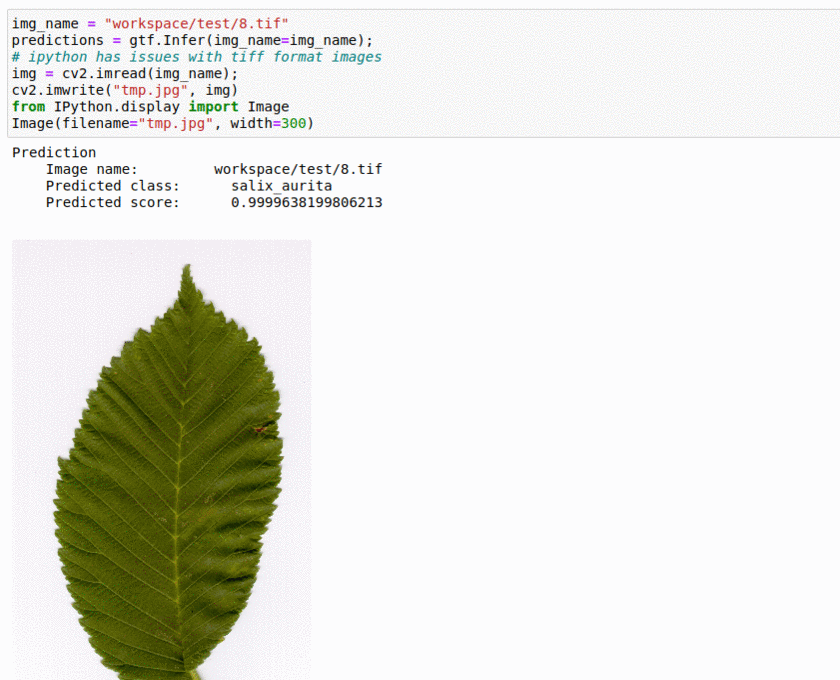
* Goal — To classify different leaf species.
* Application — Monitor different species and take actions for their growth
* Details — 1K+images with 10+ leaf types.
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
M) PlantDoc Plant Disease Dataset
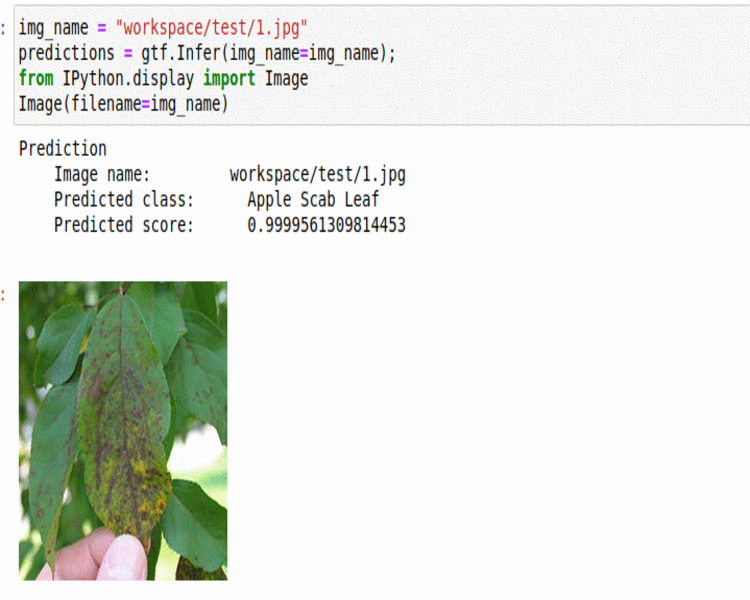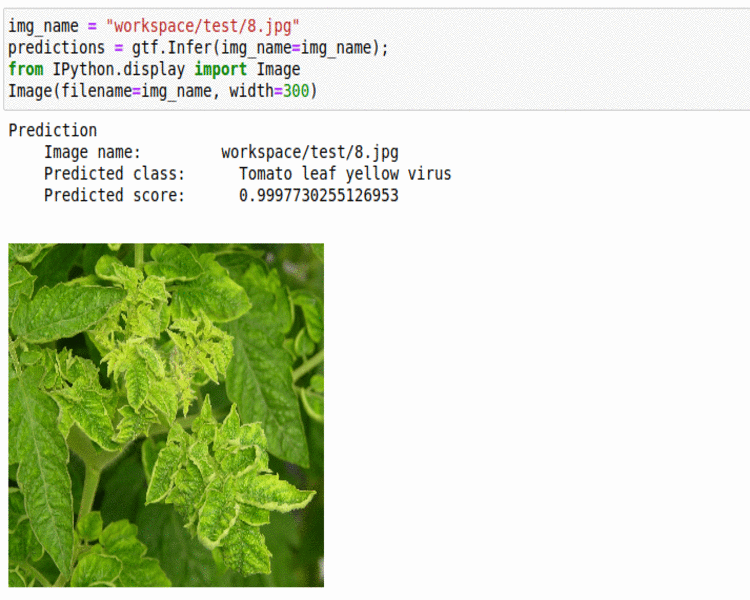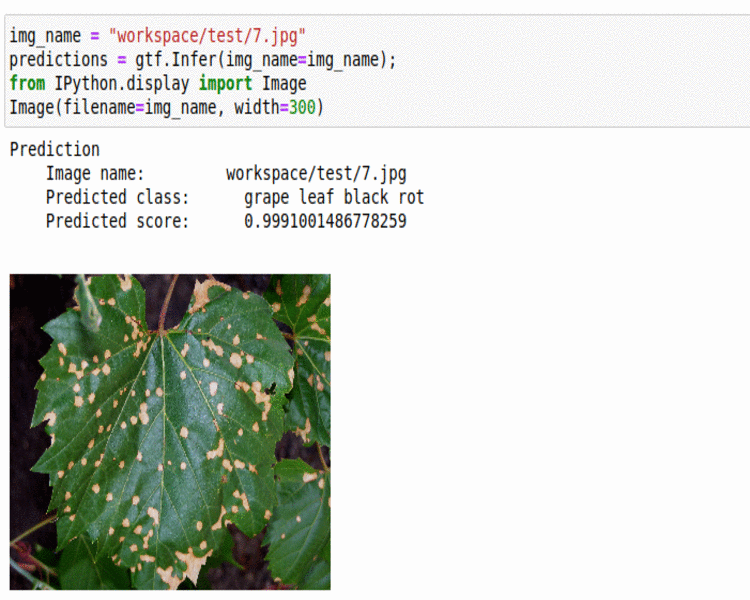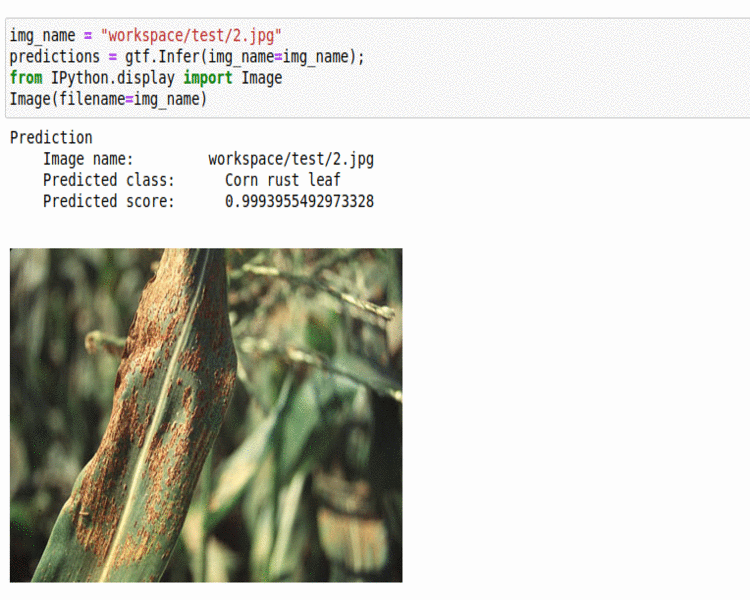
* Goal — To classify different plant diseases.
* Application — Early Detection helps with taking proper measures to save the crop.
* Details — 2.5K+images spread over 17 disease types.
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
Art and Animation Related Datasets
A) Lego Brick Type Classification Dataset
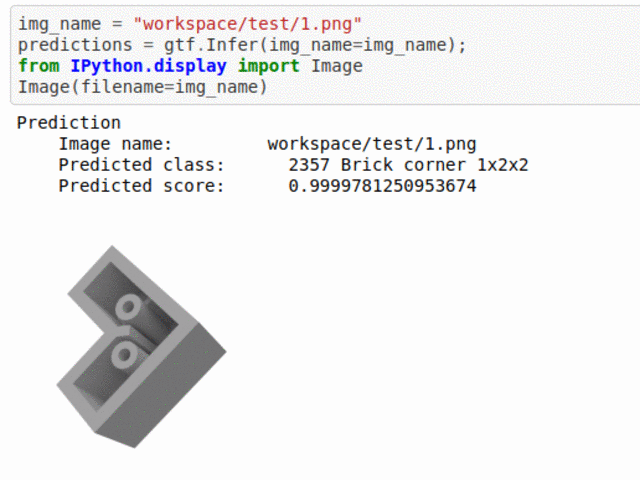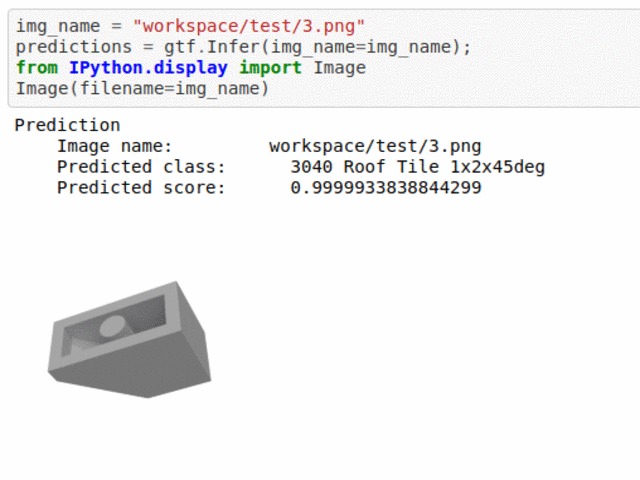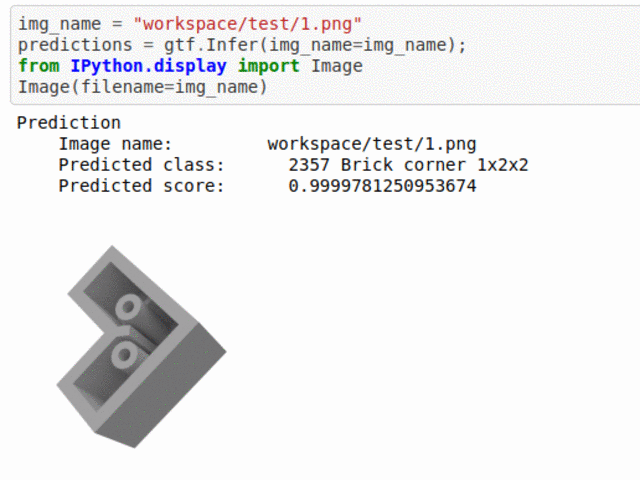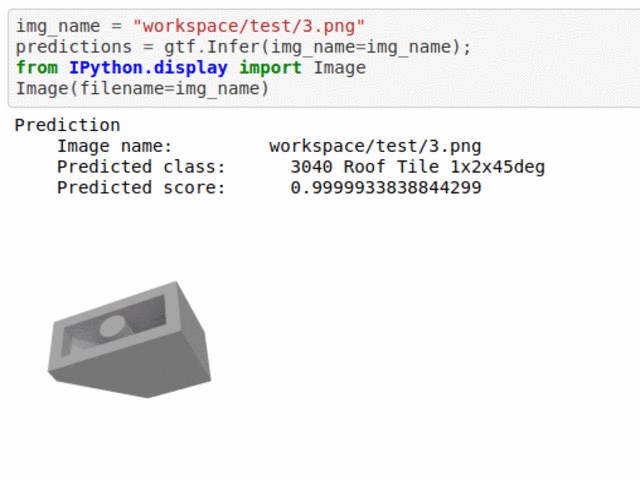
* Goal — To classify different lego types.
* Application — Monitor lego bricks in production line.
* Details — 1K+images spread over 5 lego crick types.
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
B) Architectural element type classification dataset
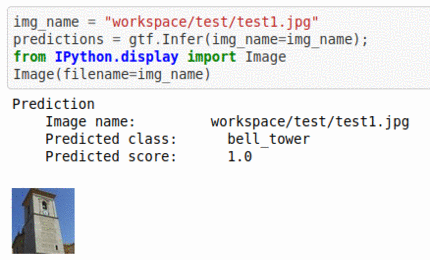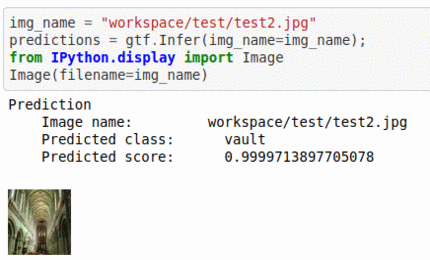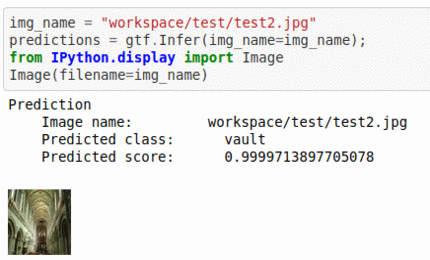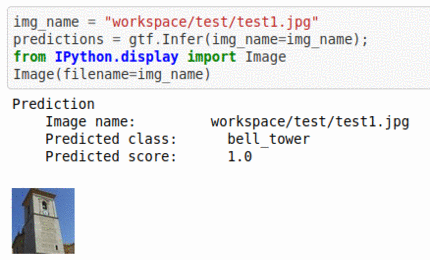
* Goal — To classify different architectural structure types.
* Application — Auto-tag natural images.
* Details — 10K+images spread over 10 different types of structures.
* How to utilize the dataset and create a classifier using Mxnet’s Mobilenet V1 Pipeline
C) Pokemon Classification Dataset
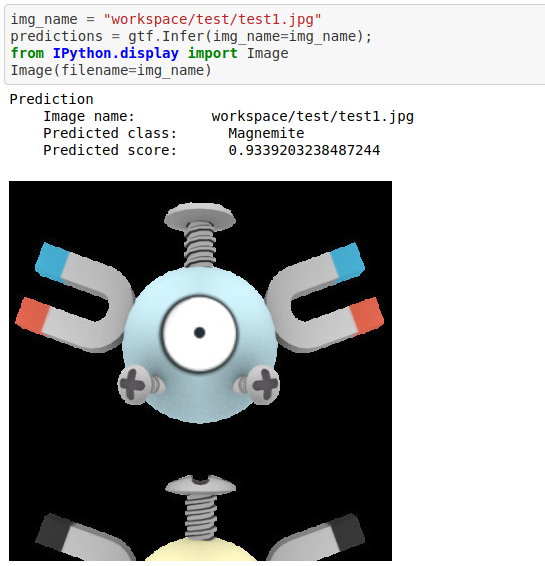
* Goal — To classify different pokemon types.
* Details — 7K+images spread over 20 different types of pokemons.
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
D) Simpsons Character Dataset

* Goal — To classify different simpsons characters.
* Details — 5K+images spread over 14 different characters.
* How to utilize the dataset and create a classifier using Pytorch’s Vgg-Net Pipeline
E) Art Type Classification

* Goal — To classify different art types — paintings, drawings, sculpture, iconography, graphic art.
* Details — 5K+images with 5 different classes.
* How to utilize the dataset and create a classifier using Pytorch’s Alexnet Pipeline
F) Hackerearth Autogala Competition Dataset
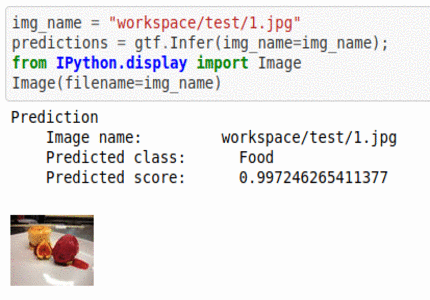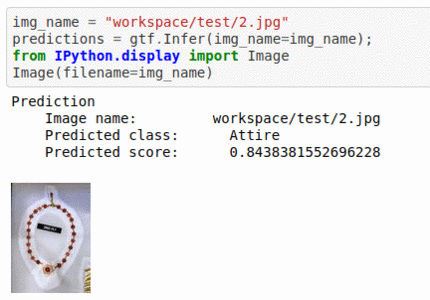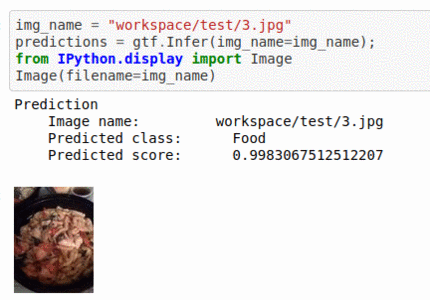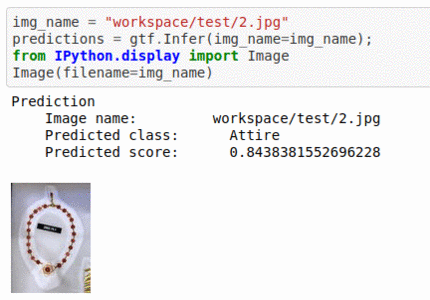
* Goal — To auto-tag images and classify into food items, attire, design and decorative items, etc.
* Application — Auto-tagging helps with better search and retrieval
* Details — 4.5K+images with 4 different classes.
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
Scene Type Understanding Dataset
A) Weather & Daylight Type Classification Dataset
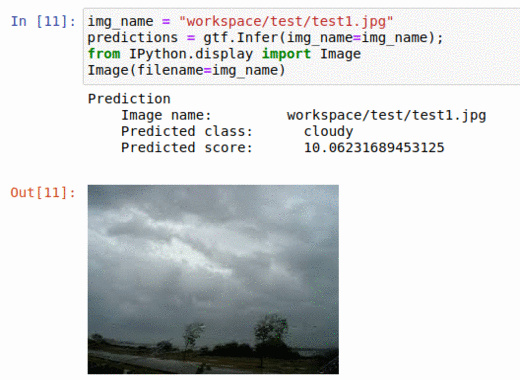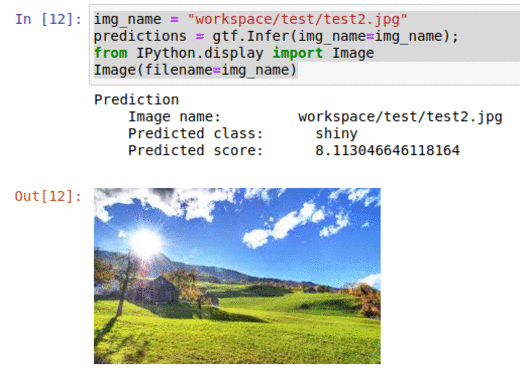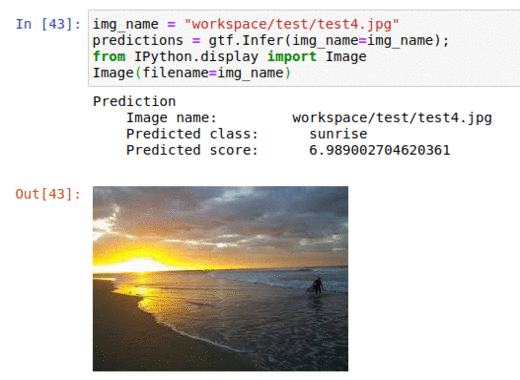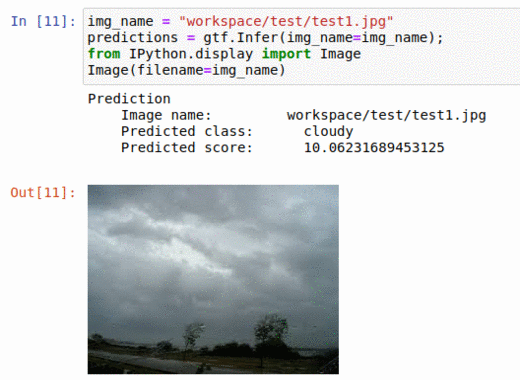
* Goal — To classify images as per the weather.
* Application — Auto-tagging helps with better search and retrieval
* Details — 1K+images with 5+ different classes — sunrise, rainy, cloudy, evening, night, etc
* How to utilize the dataset and create a classifier using Pytorch’s Wide-Resnet Pipeline
B) Intel Image Classification Dataset
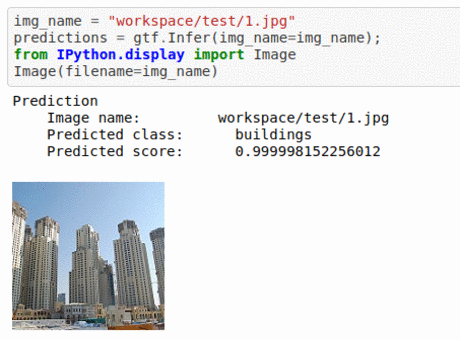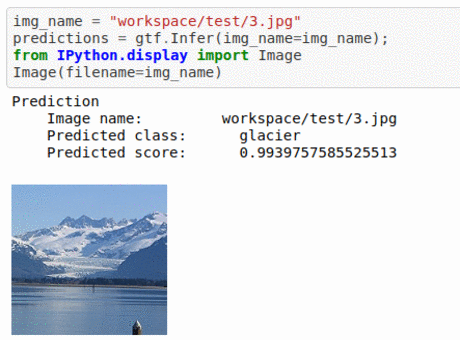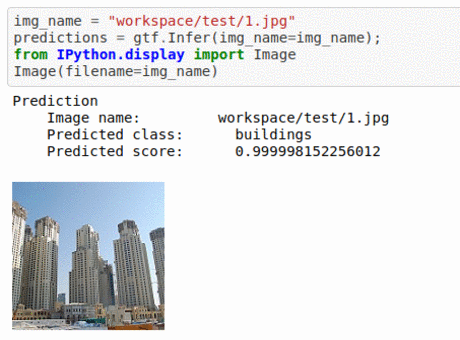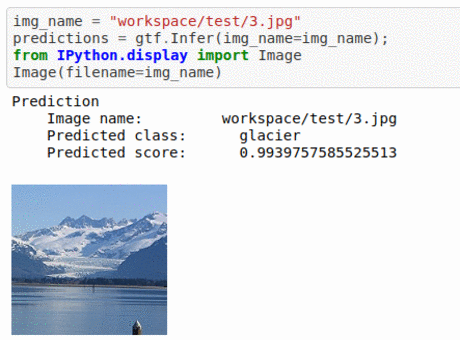
* Goal — To classify based on the place at which it was taken.
* Application — Auto-tagging helps with better search and retrieval
* Details — 25K+images with 6 different classes —urban area, forest, glacier, mountains, sea, etc
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
C) Places-365 Scene Recognition Dataset
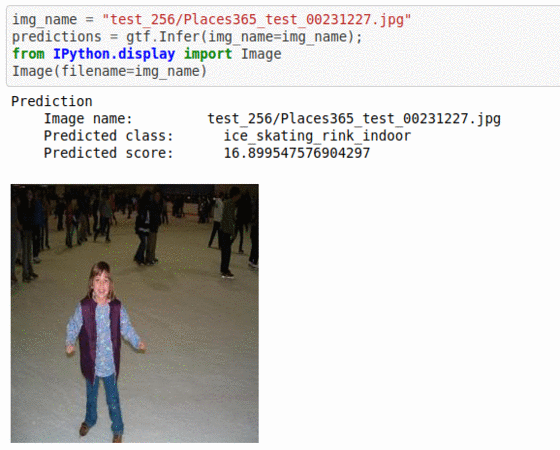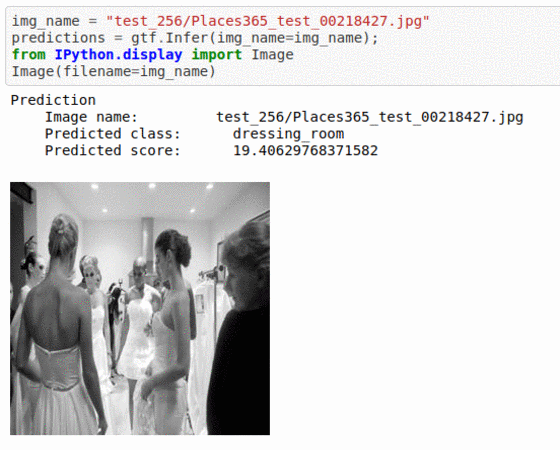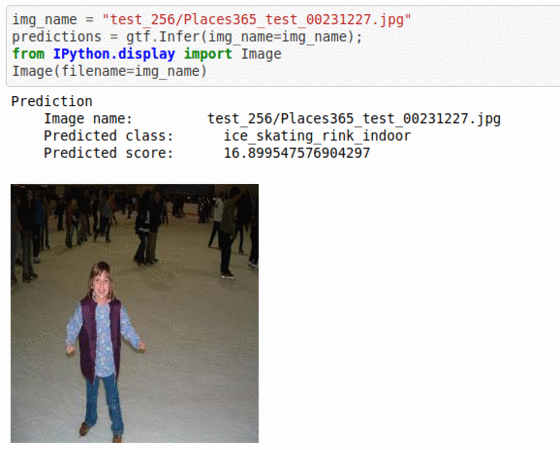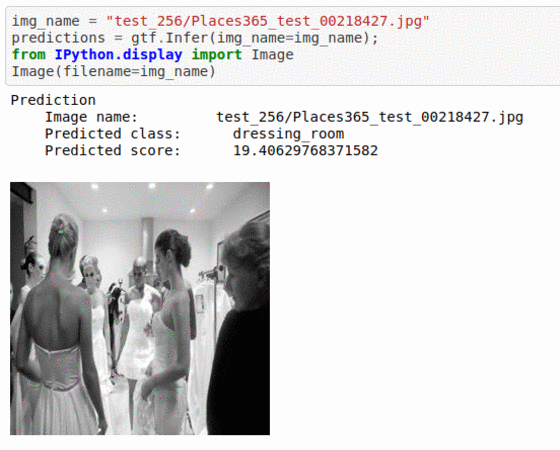
* Goal — To classify based on the place at which it was taken.
* Application — Auto-tagging helps with better search and retrieval
* Details — 20K+images with a broad set of 365 scene types
* How to utilize the dataset and create a classifier using Mxnet’s Vgg16 Pipeline
D) House Room Type Classification
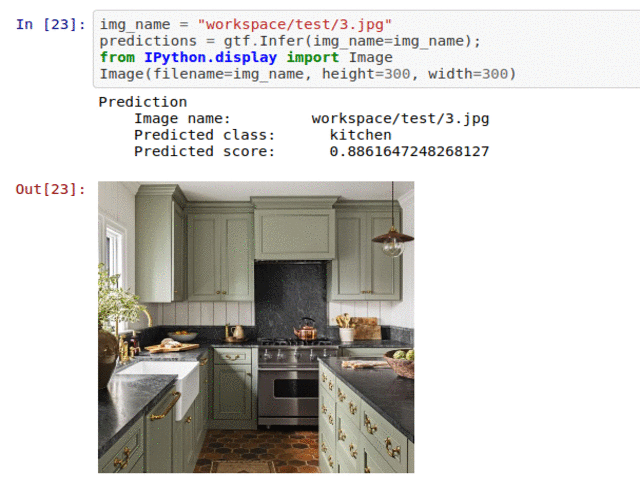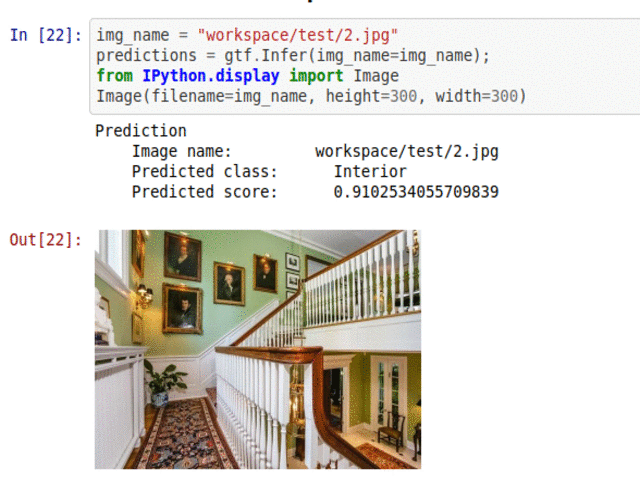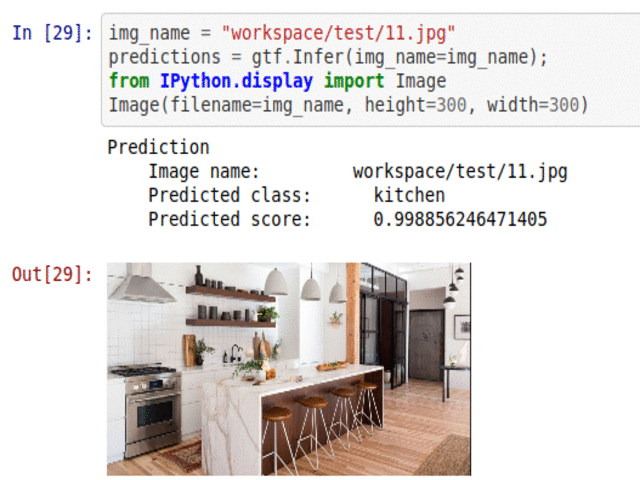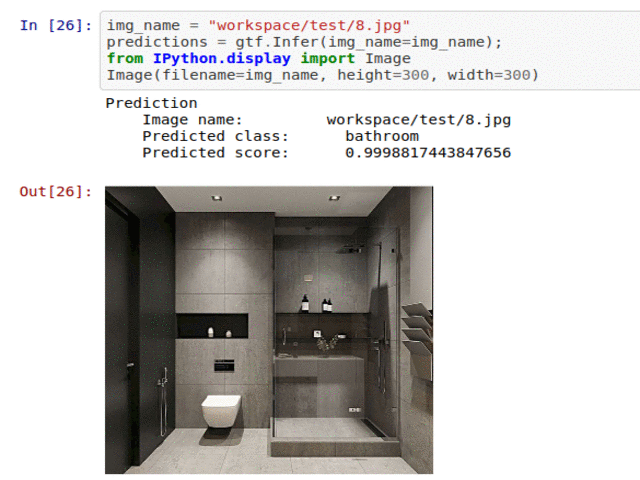
* Goal — To classify different house areas.
* Application — Tagging helps with attaching price tags to housing properties
* Details — 5K+images with 6 different scene types
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
* Another dataset for scene type recognition but for on-road adas imagery
E) UIUC Sport Event Type Classification
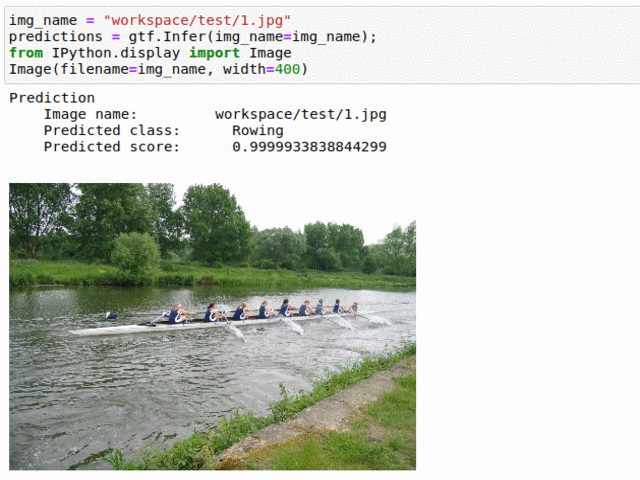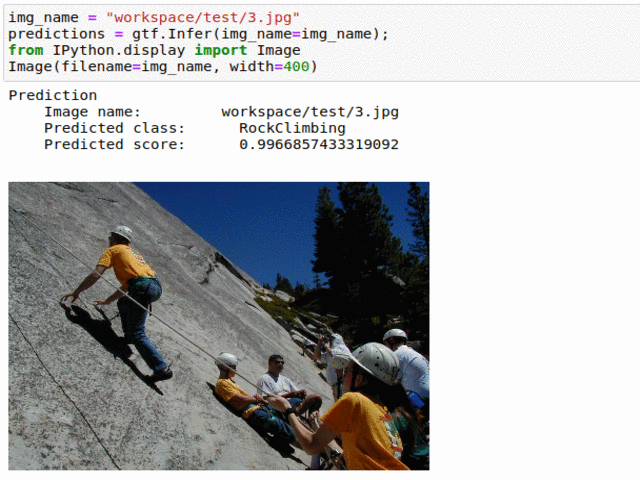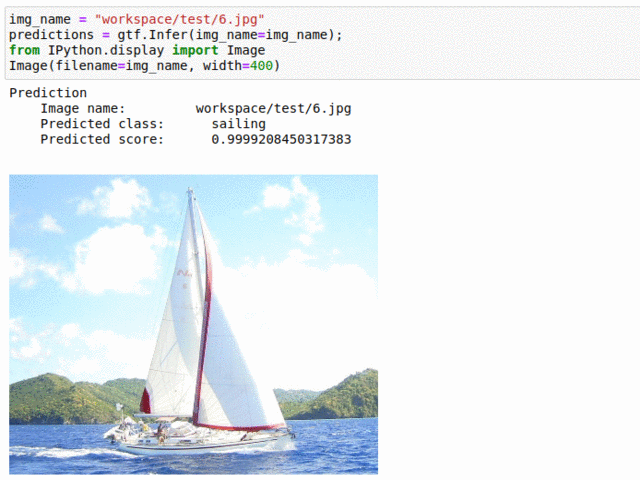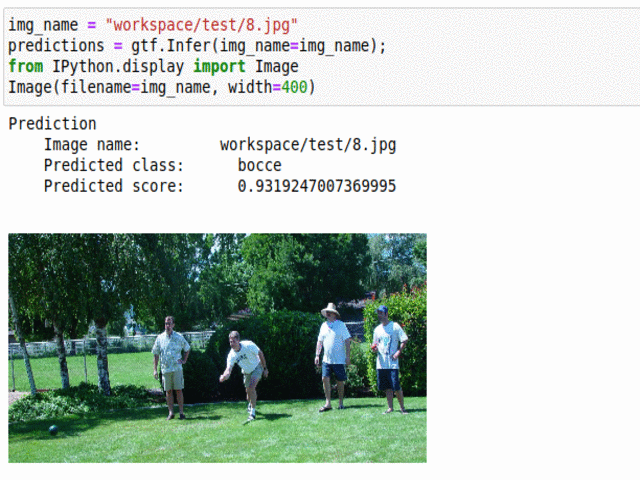
* Goal — To classify different sport events.
* Application — Auto-Tagging for better search and retrieval
* Details — 5K+images with 6 different scene types
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
Satellite Imagery Related Datasets
A) Planet Understanding Amazon Dataset
* Goal — To add multi-label tags based on weather and land-use
* Application — Monitor areas of amazon forests
* Details — 40K+images with multiple tags such as cloudy, clear, forest, rivers, agriculture, etc
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
B) HistAreal V1.0 Land Usage Classification Dataset
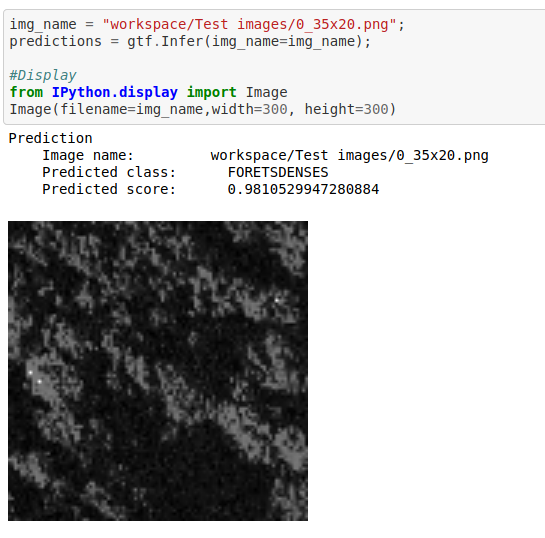
* Goal — To classify satellite imagery patches based on land-use
* Application — Monitor and keep track of how land is being used, as well as keep track of water reserve areas
* Details — 10K+images with multiple tags such as urban, forest, rivers, agriculture, etc
* How to utilize the dataset and create a classifier using Mxnet’s Vgg-Net Pipeline
* Another such dataset focusses on monitoring coffee fields in Brazil, associated training code
C) UC Merced Land Use Classification Dataset
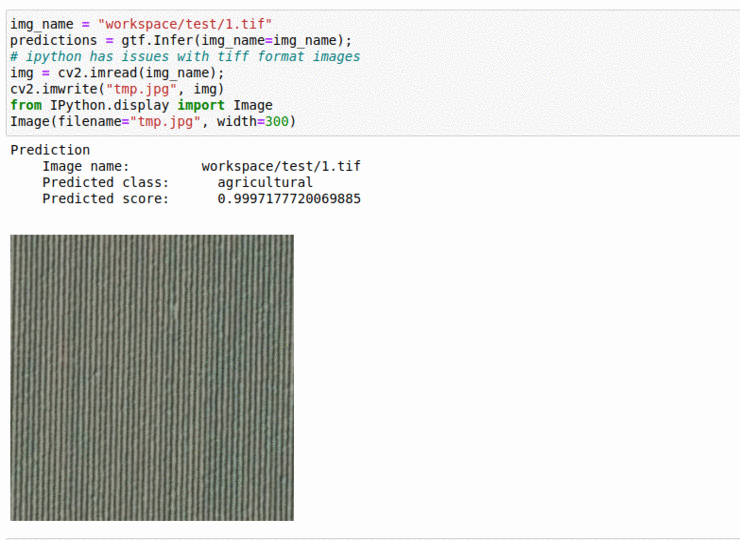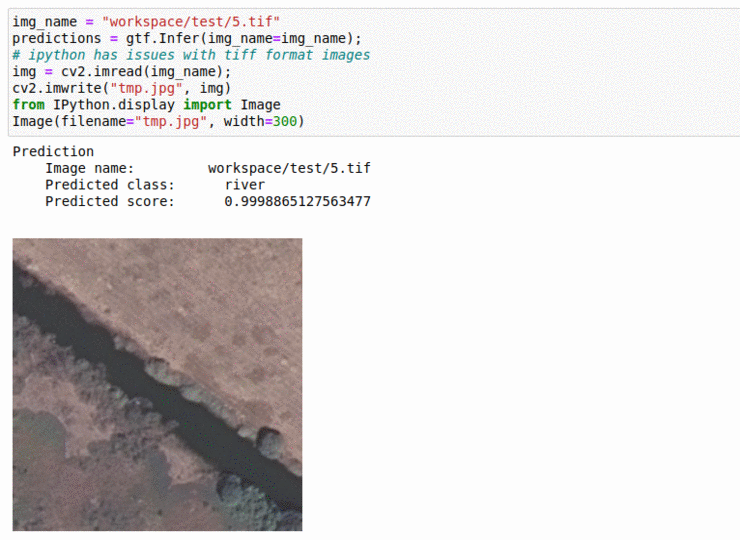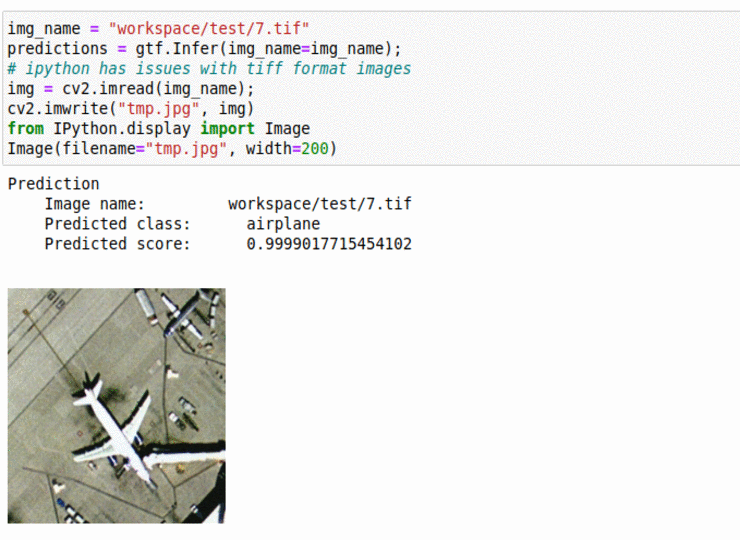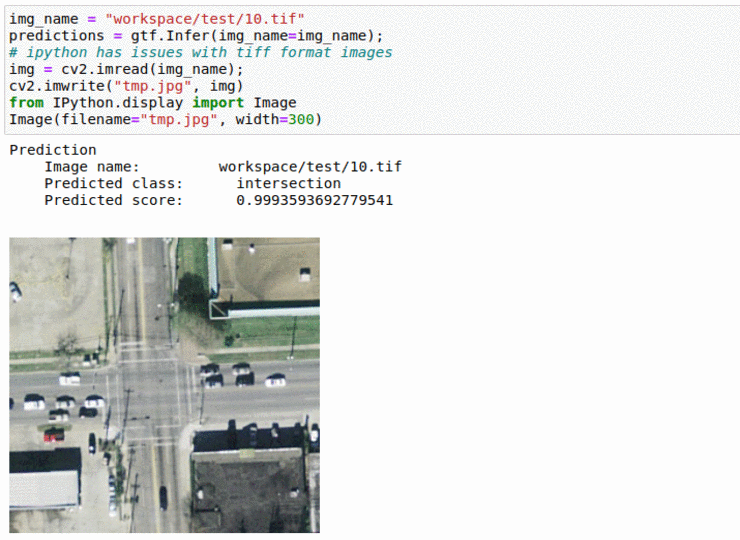
* Goal — To classify satellite imagery patches based on land-use
* Application — Monitor and keep track of how land is being used, as well as keep track of water reserve areas
* Details — 2K+images with multiple tags such as urban, forest, rivers, agriculture, etc
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
Other Datasets
A) CIFAR-10 Dataset
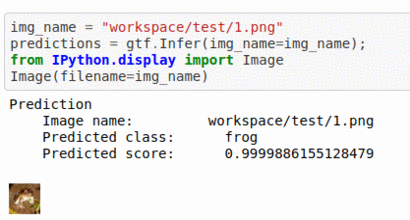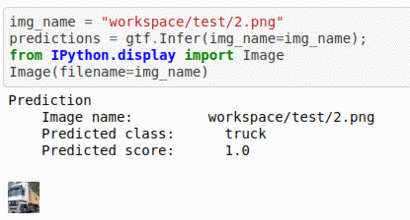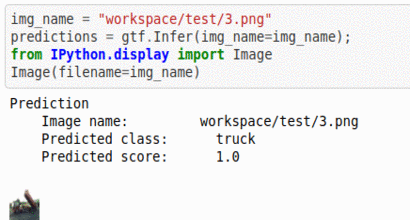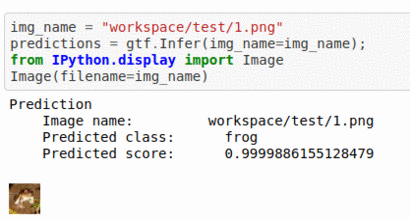
* Goal — To classify Images Based on contents
* Details — 60K+images 10 classes
* How to utilize the dataset and create a classifier using Pytorch’s Vgg-Net Pipeline
More Datasets on similar path
* Cifar-100 Dataset and associated training code
* STL-10 Dataset and associated training code
* Caltech-256 Dataset and associated training code using Pytorch’s ShuffleNet Pipeline
* Natural-Images-10 Dataset and associated training code
B) Hand-Written Math Symbol Dataset
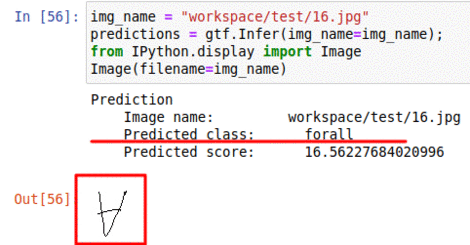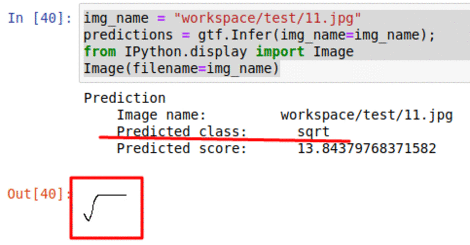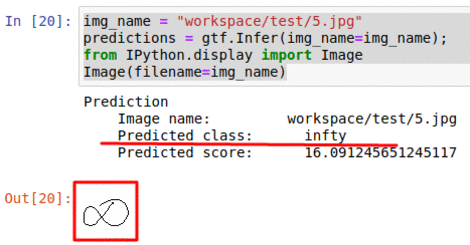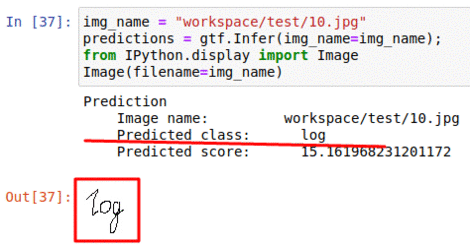
* Goal — To classify hand-written math symbols
* Application — Digitize hand written math text
* Details — 1K+ 45×45 sized images with 20+ different symbol classes
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
C) Face Mask Dataset
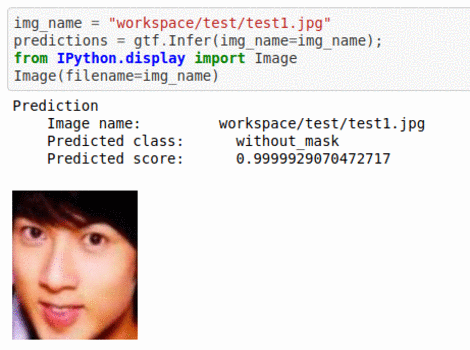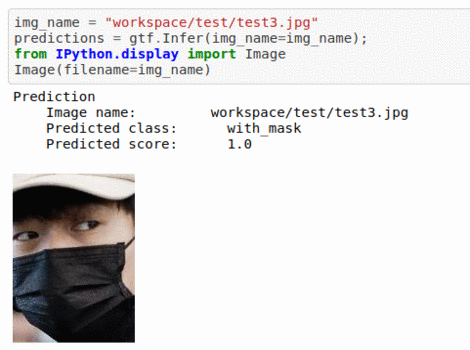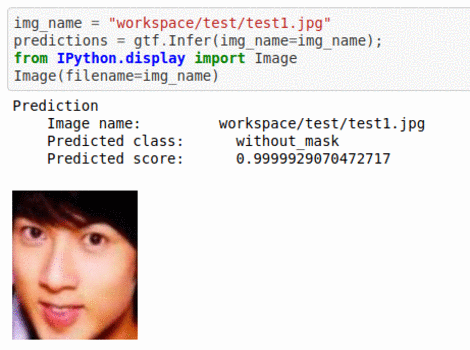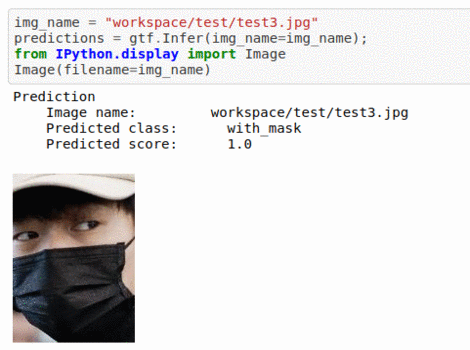
* Goal — To classify whether people are wearing face masks or not
* Application — Monitor if proper protection is being taken care off
* Details — 500+ images with 2 different classes
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
D) American Sign Language Alphabet Dataset
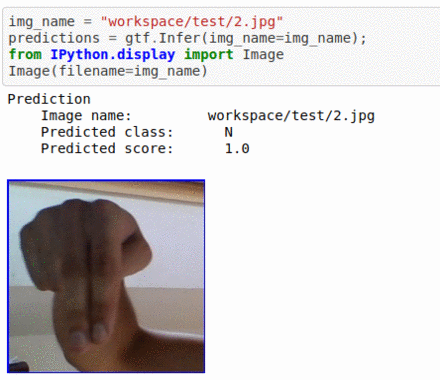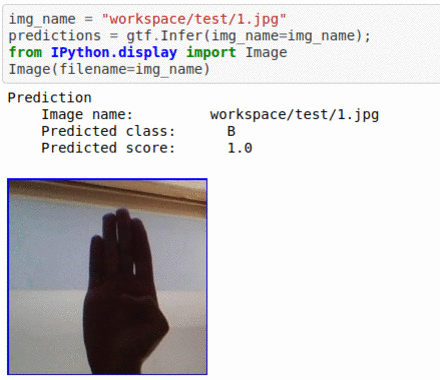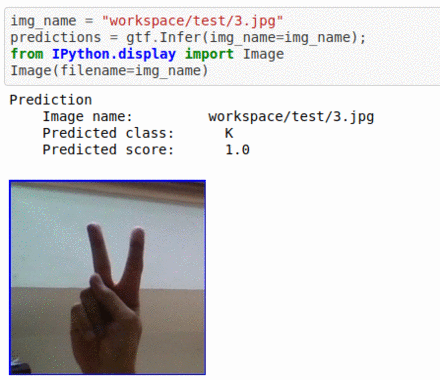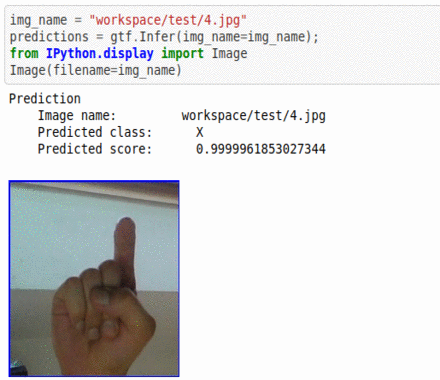
* Goal — To classify different ASL alphabets
* Application — Basic element in complete sign language recognition demo
* Details — 85K+ images with 26 different alphabet classes
* How to utilize the dataset and create a classifier using Mxnet’s Densenet Pipeline
E) Yoga-82 Pose Estimation Dataset

* Goal — To classify different Yoga Posses
* Application — First step in analysing different pose estimations
* Details — 20K+ images with 82 different yoga pose classes
* How to utilize the dataset and create a classifier using Pytorch’s Densenet Pipeline
F) Hackerearth Dance Pose Identification Challenge
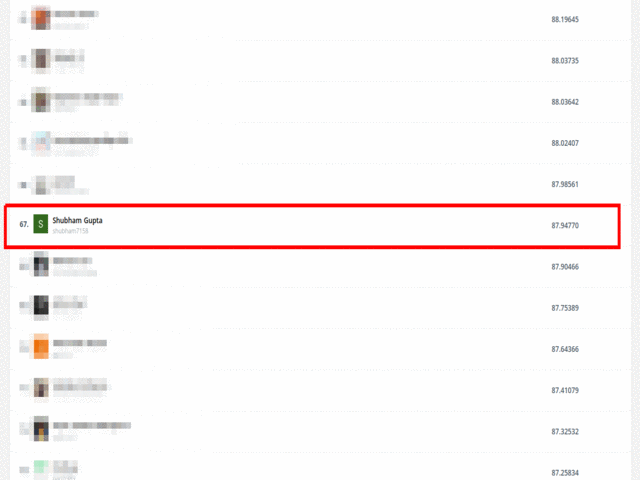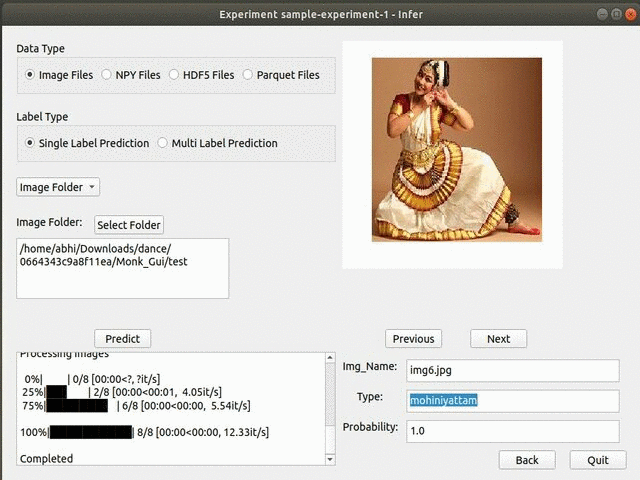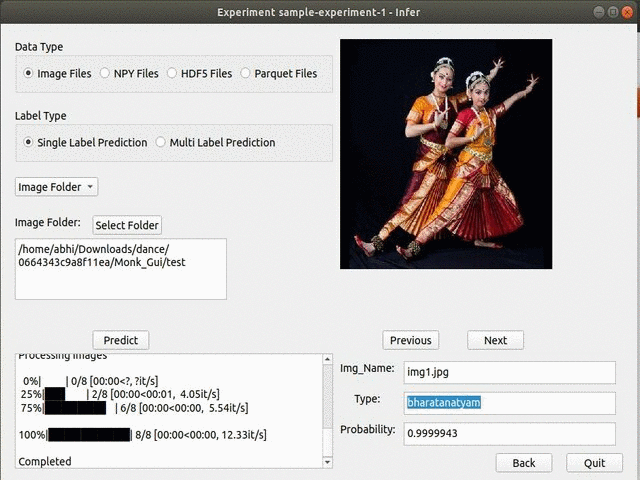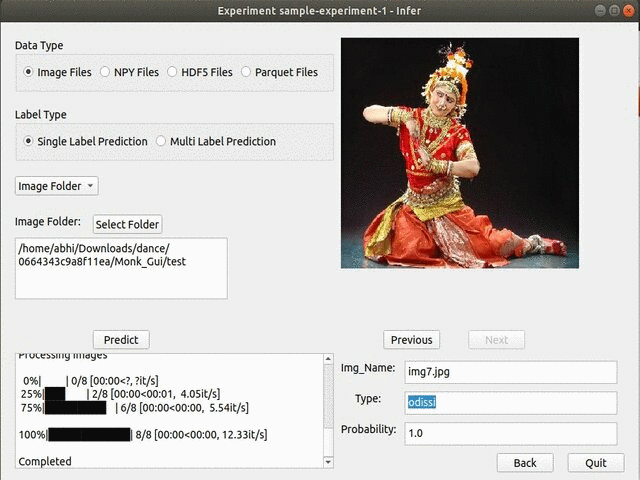
* Goal — To classify different dance styles
* Details — 300+ images with 8 different dance style classes
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
G) Bill Type Classification Dataset
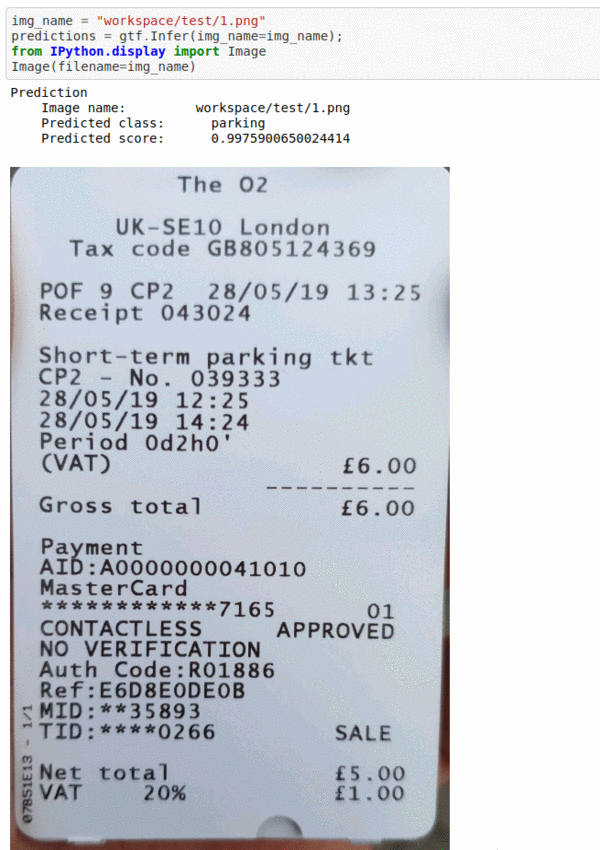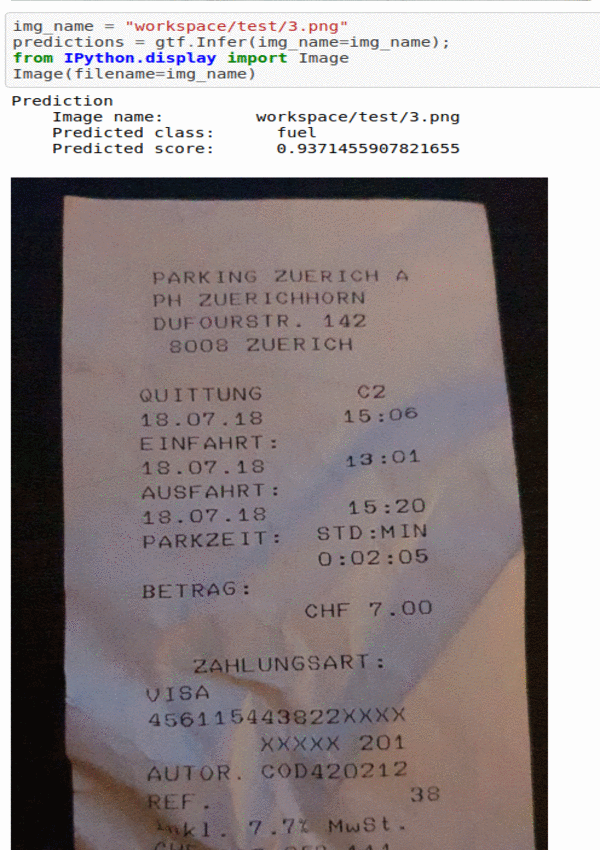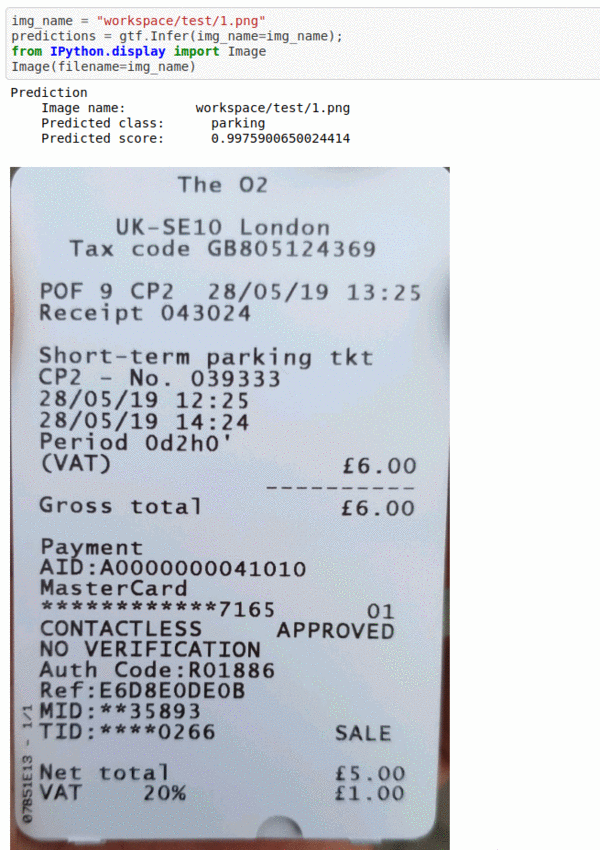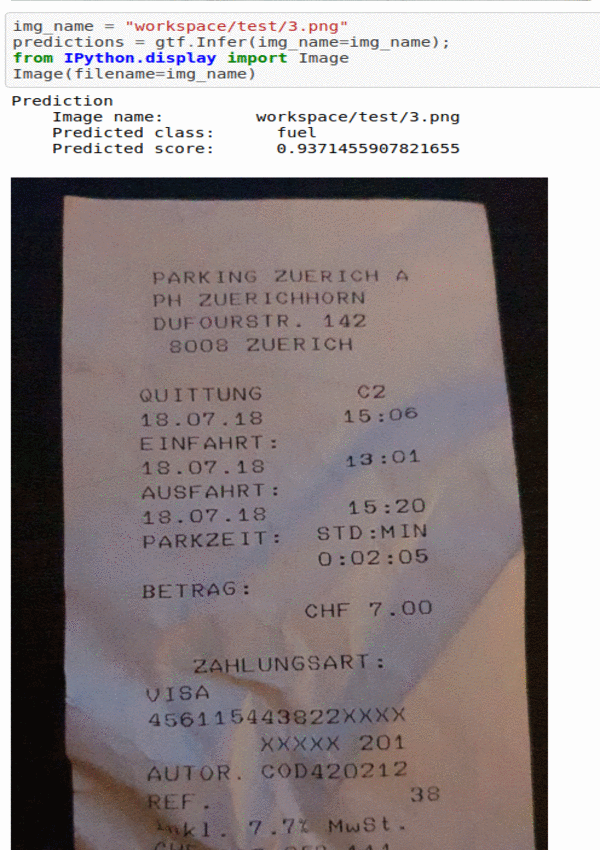
* Goal — To classify different bill receipts
* Application — First step in reading different bill receipts
* Details — 500K+ images spread over 4 different classes of receipts
* How to utilize the dataset and create a classifier using Pytorch’s Resnext Pipeline
H) IEEE Camera Model Type Classification Dataset
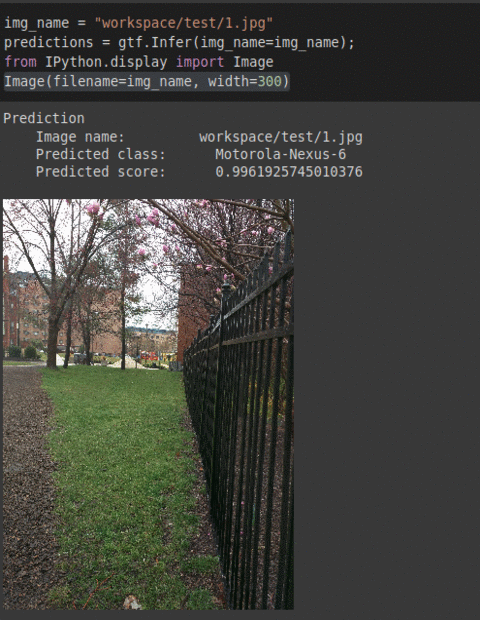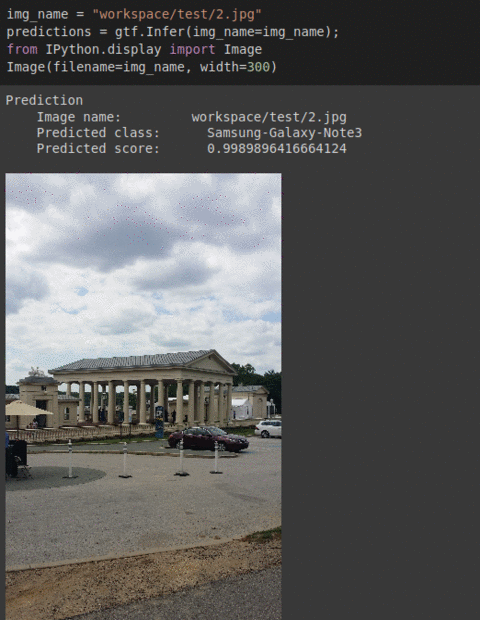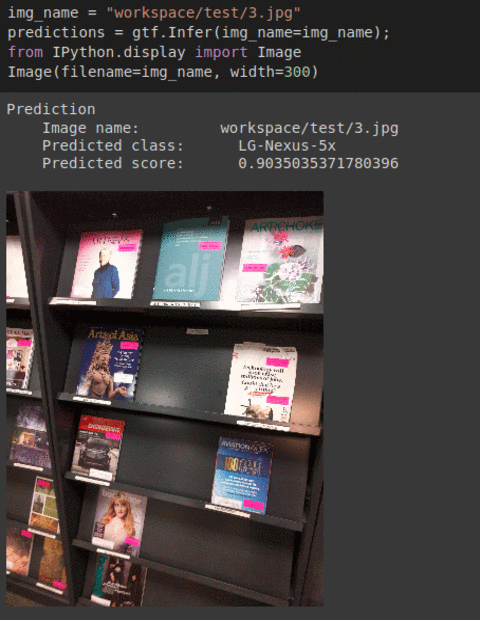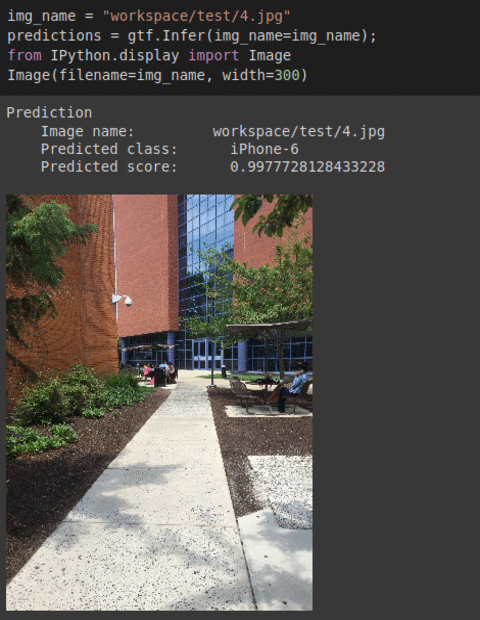
* Goal — To predict which phone’s camera the images were taken
* Details — 500+ images spread over 4 different classes of receipts
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
I) Fire Presence Detection Dataset
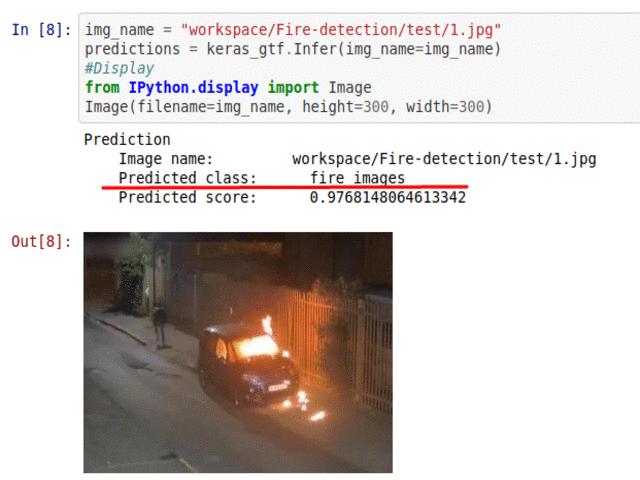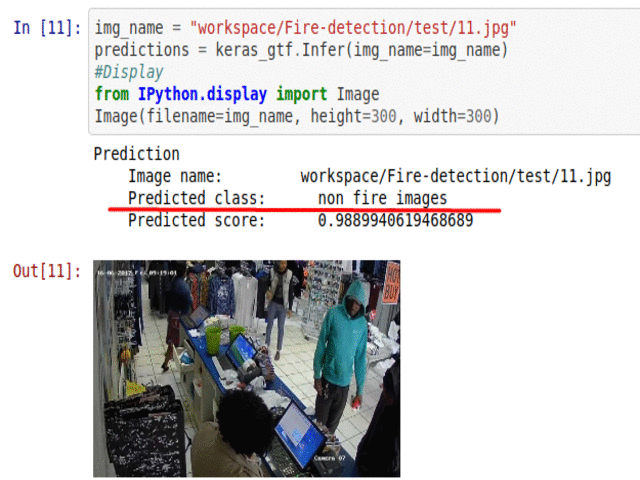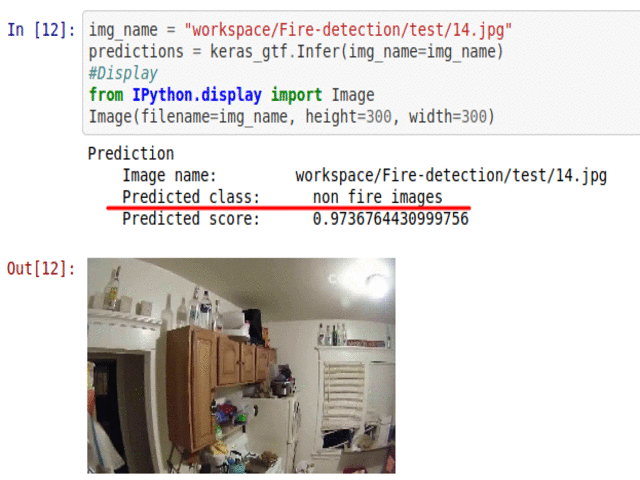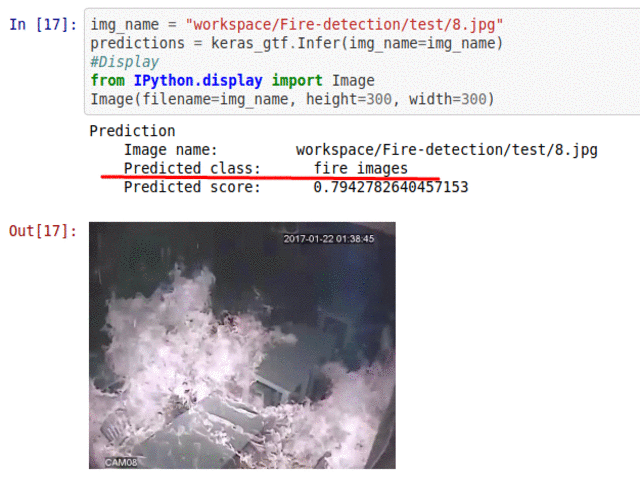
* Goal — To detect presence of fire in images
* Application — Early detection is ciritcal for saving life and property
* Details — 500+ images from different scenarios
* How to utilize the dataset and create a classifier using Keras’ Densenet Pipeline
J) Bengali text Grapheme Classification Dataset
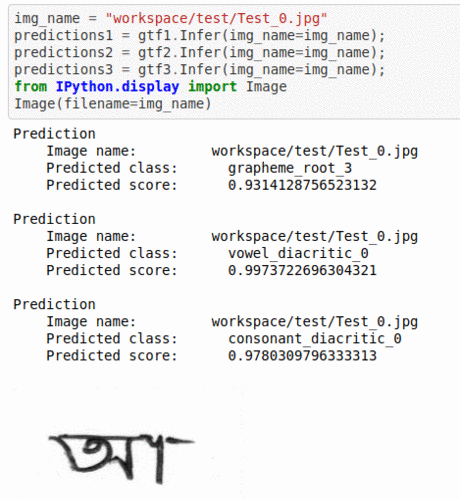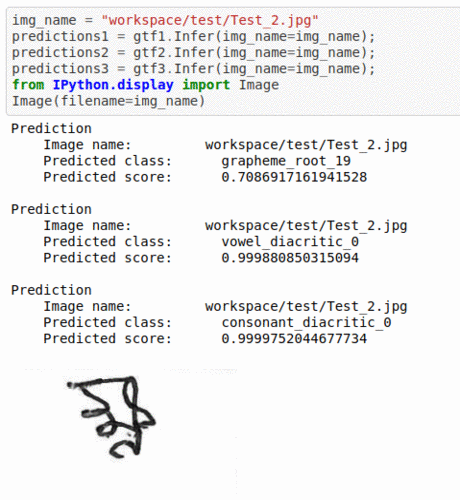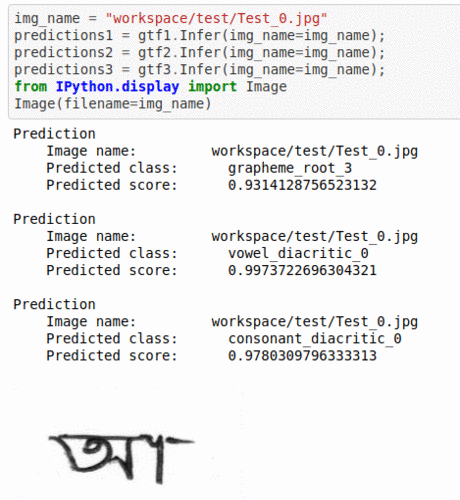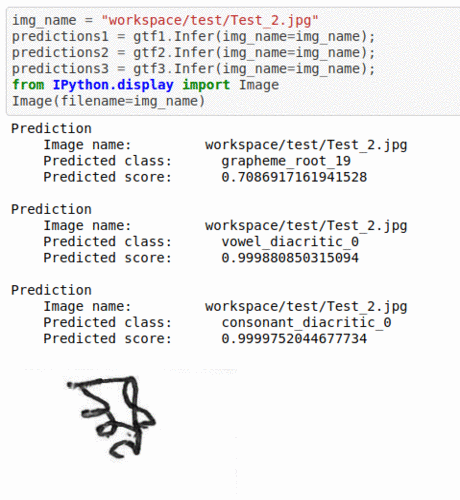
* Goal — To detect grapheme root, vowel diacritic and consonant diacritic type in reading Bengali language text
* Application — Crucial step in OCR and NLP applications
* Details — 10K+ images with multi-class labels
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
K) Russian Handwritten Digits Classification Dataset
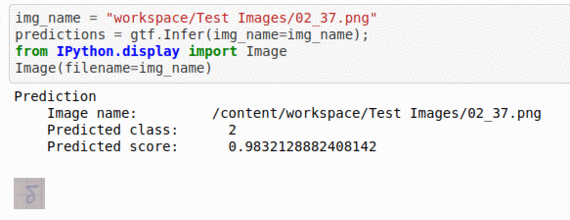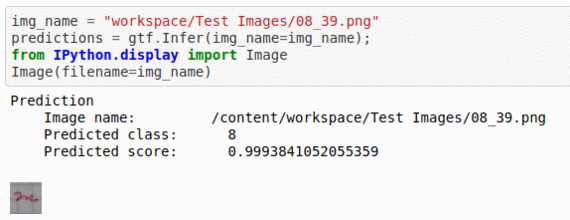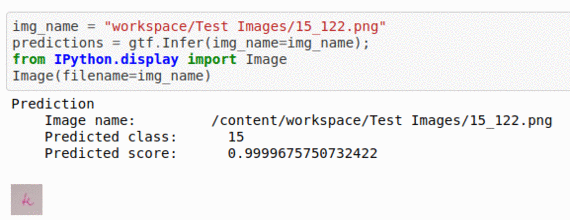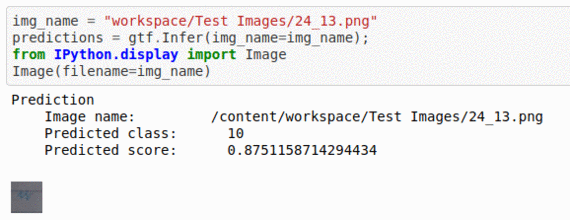
* Goal — To detect different Russian language characters
* Application — Crucial step in OCR and NLP applications
* Details — 2K+ images with 30+ different labels
* How to utilize the dataset and create a classifier using Mxnet’s Resnet Pipeline
L) Microsoft Image Understanding Dataset
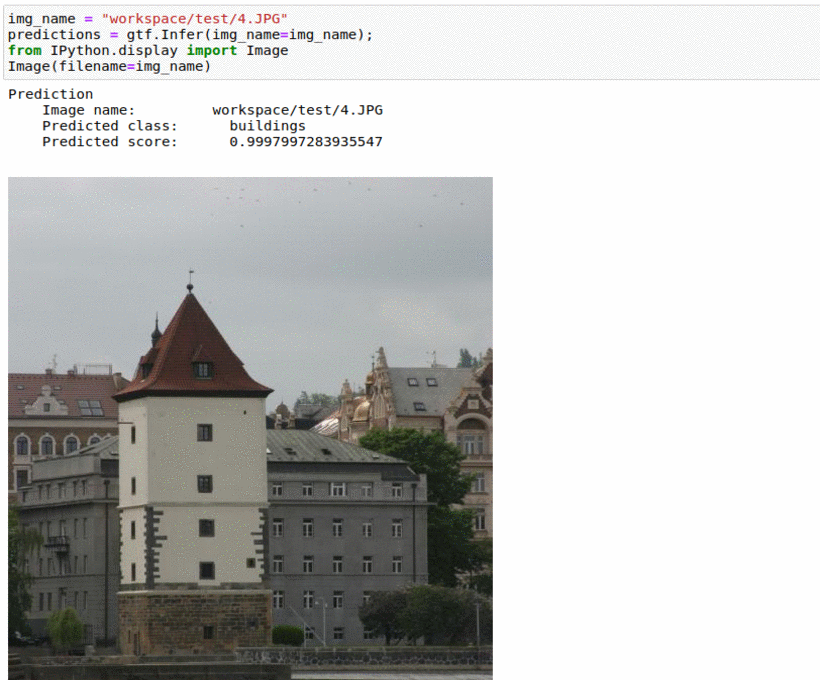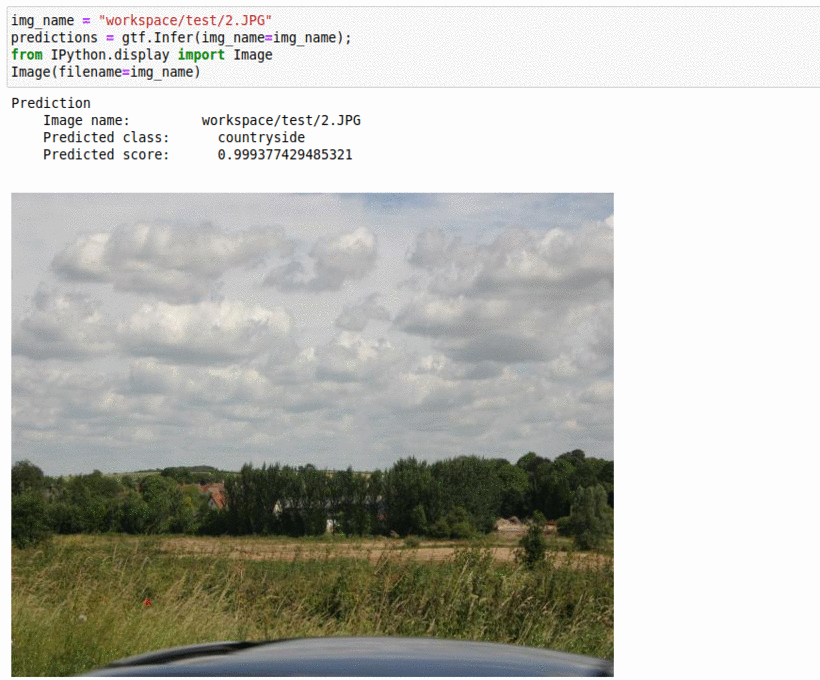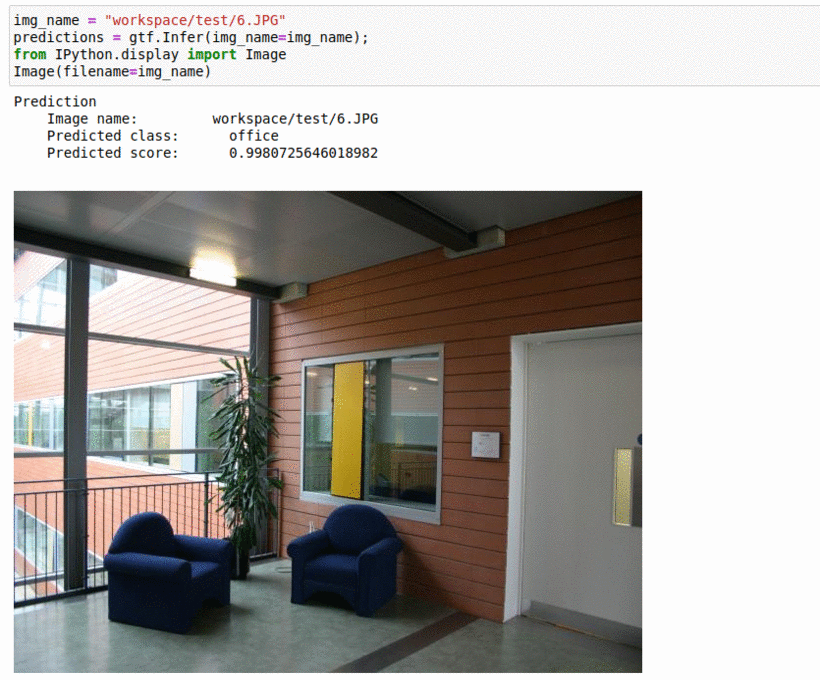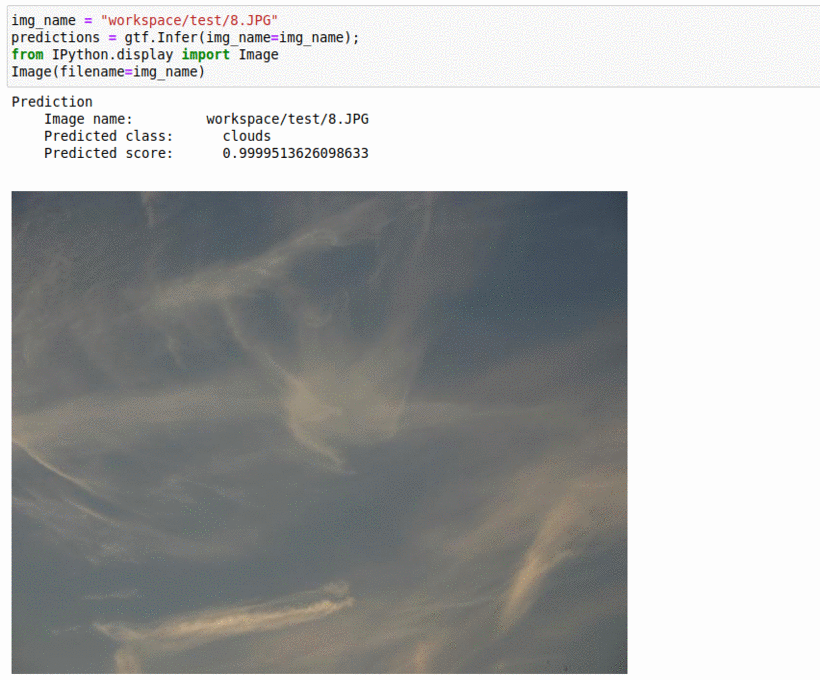
* Goal — To detect important elements in images
* Application — Auto-tag images for better indexing
* Details — 2K+ images with 5+ different labels
* How to utilize the dataset and create a classifier using Pytorch’s Resnet Pipeline
M) Office Home Dataset
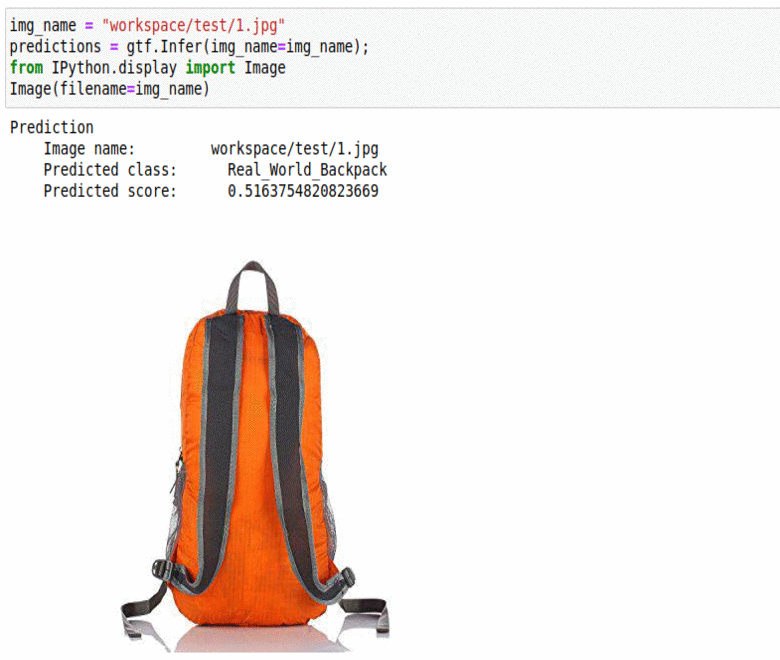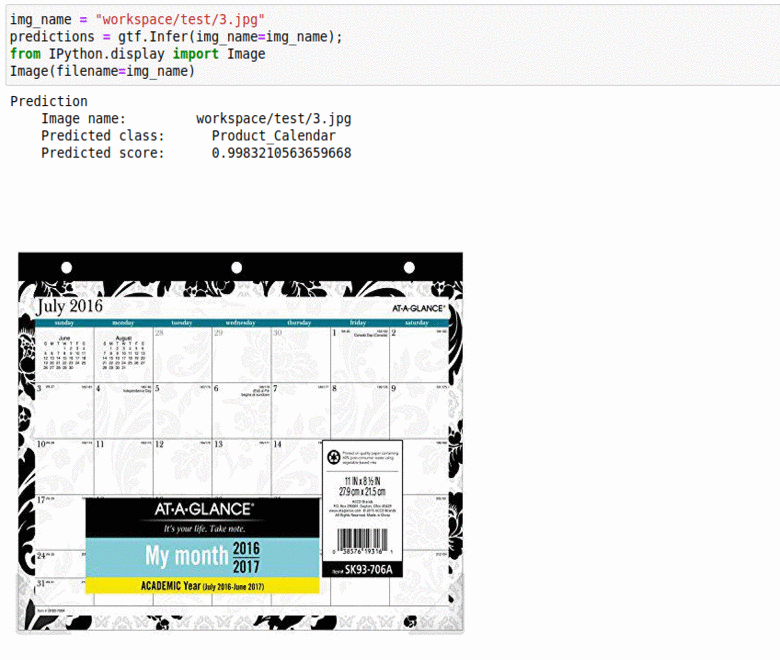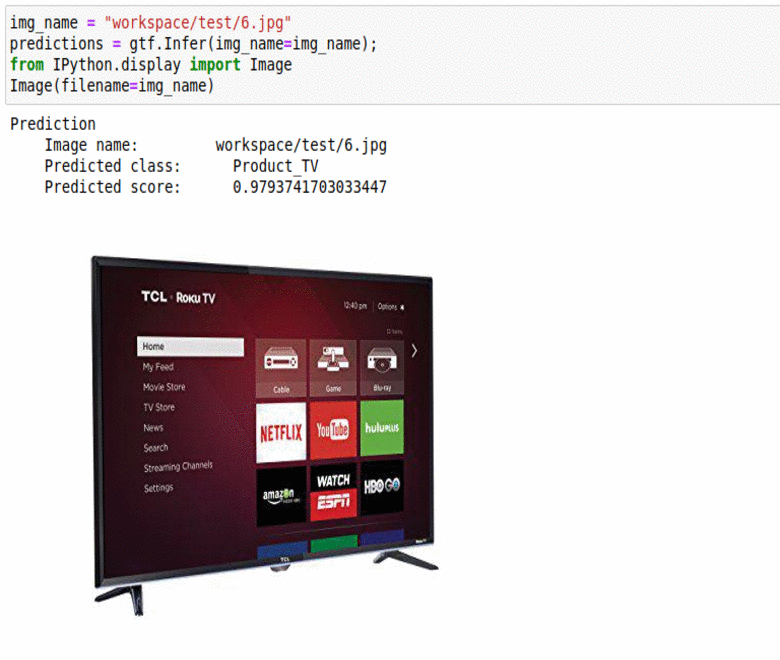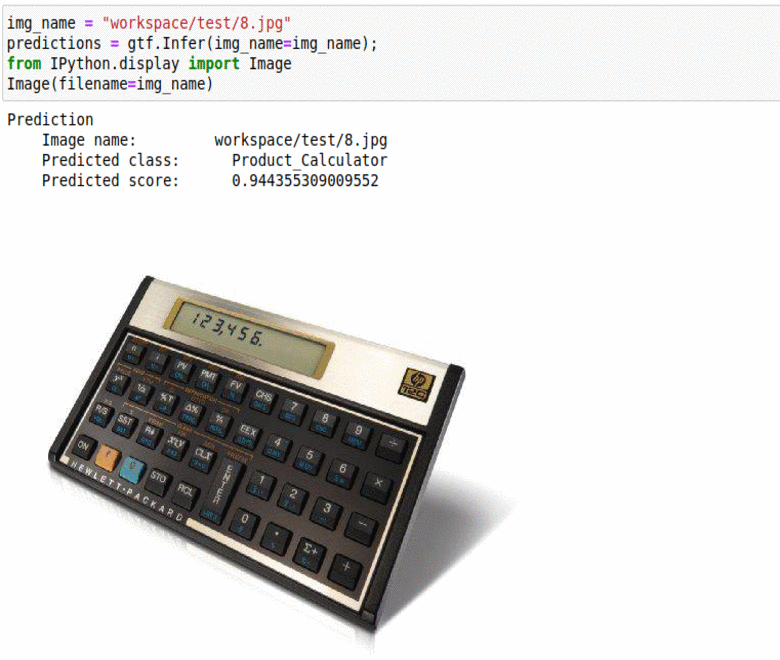
* Goal — To classify common objects found in offices and homes
* Application — Auto-tag images for better indexing
* Details — 5K+ images with 10+ different object labels
* How to utilize the dataset and create a classifier using Pytorch’s Vgg-Net Pipeline
Appendix
For more details on the tutorials visit our Github page
Tutorial Credits to all the opensource contributors at the Monk Image Classification Library
70+ Image Classification Datasets from different industry domains — Part 2 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")
Recent Posts




")

