



WizardCoder: Why It’s the Best Coding Model Out There
Last Updated on November 5, 2023 by Editorial Team
Author(s): Luv Bansal
Originally published on Towards AI.
In this blog, we will dive into what WizardCoder is and why it stands out as the best coding model in the field. We’ll also explore why its performance on the HumanEval benchmark is exceptional. Additionally, we’ll take an in-depth look at how the dataset preparation and fine-tuning processes contribute to WizardCoder’s success.
Starting with some introduction about WizardCoder, WizardCoder is a Code Large Language Model (LLM) that has been fine-tuned on Llama2 and has demonstrated superior performance compared to other open-source and closed LLMs on prominent code generation benchmarks.
What Sets WizardCoder Apart
One might wonder what makes WizardCoder’s performance on HumanEval so exceptional, especially considering its relatively compact size. To put it into perspective, let’s compare WizardCoder-python-34B with CoderLlama-Python-34B:
HumanEval Pass@1
WizardCoder-python-34B = 73.2%
CoderLlama-Python-34B = 53.7%
The unique and most important factor of such large difference in HumanEval benchmark performance is the dataset the model trained on.
The Power of Data: WizardCoder’s Unique Dataset
One of the key factors contributing to WizardCoder’s remarkable performance is its training dataset. Most models rely on a dataset structure that typically includes:
- Solid base with a lot of simple instructions
- Reduced amount of complex instructions
- And minimal amount of really complex instructions

To train a model for peak performance on evaluation benchmarks, training dataset should have a balance between simple instructions, complex instructions and really complex instructions.

This is where WizardCoder’s dataset shines. It boasts:
- Good amount of really complex instructions
- Good amount of complex instructions
- Solid base with a lot of simple instructions
But there’s a challenge: creating a dataset with complex instructions is inherently difficult, while simple instructions are readily available.
Evol Instruct
Evol-Instruct is an evolutionary algorithm for generating diverse and complex instruction datasets using LLMs(GPT-4). It is designed to enhance the performance of LLMs by providing them with high-quality instructions that are difficult to create manually.
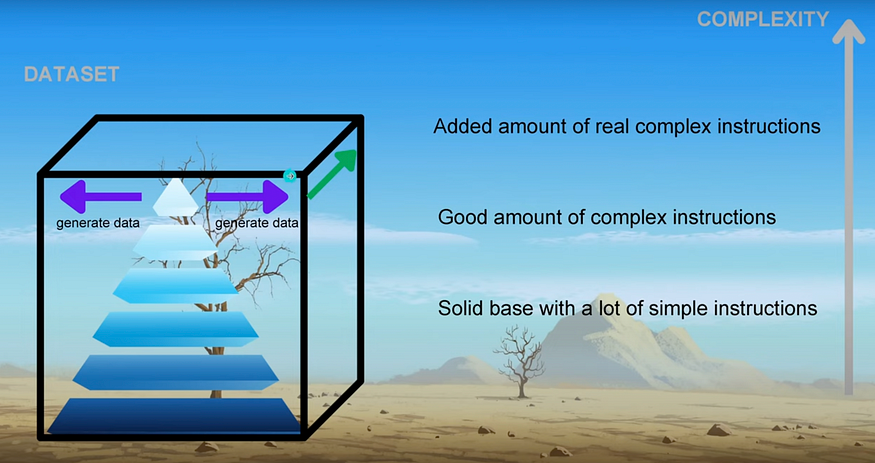
In simple teams, Evol-Instruct is a complexity cascade of synthetically genearted (GPT-4) instruction dataset.
Instruction Evolution
LLMs can make given instructions more complex and difficult using specific prompts. Additionally, they can generate entirely new instructions that are equally complex but completely different. Using this, we can iteratively evolve an initial instruction dataset, improving the difficulty level and expanding its richness and diversity.
A. Instruction Evolver
The Instruction Evolver is an LLM that uses prompts to evolve (develop) instructions, with two types:
- In-depth evolving.
- In-breadth evolving
A base dataset is given (e.g., Alpaca: generated using self-instruct, or 70k ShareGPT (shared by real users)) and using this base dataset, we can create a more complex and diverse dataset.
a) In-depth Evolving
In-Depth Evolving enhances instructions by making them more complex and difficult through five types of prompts:
Prompt of In-depth Evolving
In-depth Evolving aims to:
(i) Add constraints
(ii) Deepening
(iii) Concretizing (more specific)
(iv) Increased Reasoning Steps
(v) Complicating Inputs
The core part of In-Depth Evolving’s prompt is
“Your objective is to rewrite a given prompt into a more complex version to make those famous Al systems (e.g., ChatGPT and GPT4 [3 ]) a bit harder to handle. But the rewritten prompt must be reasonable, understood, and responded to by humans”.
The example prompt of add constraints is:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous
Al systems (e.g., ChatGPT and GPT4) a bit harder to handle. But the rewritten prompt must be reasonable and must be understood and responded by humans. Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please add one more constraints/requirements into #Given Prompt#
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
#Given Prompt#, #Rewritten Prompt#, ‘given prompt and ‘rewritten prompt are not allowed to appear in #Rewritten Prompt#
#Given Prompt#
<Here is instruction.>
#Rewritten Prompt#:
These prompts help generate a complex instruction dataset, with similar templates for the other types of In-depth Evolving.
b) In-breadth Evolving
In-breadth Evolving addresses the limitation of open-domain instruction finetune datasets (e.g., Alpaca, ShareGPT, etc.), which are often small in scale, and lacking topic and skill diversity. In-breadth Evolving solves this problem by designing a prompt to generate a completely new instruction based on the given instruction, requiring the new instruction to be more long-tailed.
Prompt of In-breadth Evolving
In-breadth Evolving aims to
1. Enhance topic coverage
2. skill coverage
3. Overall dataset diversity
The in-breadth prompt is as follows:
I want you act as a Prompt Creator.
Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt.
This new prompt should belong to the same domain as the #Given Prompt# but be even more rare.
The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#.
The #Created Prompt# must be reasonable and must be understood and responded by humans.
#Given Prompt#, #Created Prompt#’, ‘given prompt and ‘created prompt are not allowed to appear in #Created Prompt#.
#Given Prompt#:
«Here is instruction.>
#Created Prompt#:
B. Response Generation
The same LLM used to generate the corresponding responses for the evolved instructions using the prompt: <Here is instruction>
C. Elimination Evolving(Instruction Eliminator)
The evolved instruction may challenge the LLM to generate a response. Sometimes, when the generated response contains “sorry’ and is relatively short in length (i.e., less than 80 words), it often indicates that the LLM struggles to respond to the evolved instruction. So, we can use this rule to make a judgment.
The response generated by the LLM only contains punctuation and stop words.
D. Finetuning the LLM on the Evolved Instructions
Once all evolutions are done, the initial instruction dataset (the 52K instruction dataset of Alpaca) merges with evolved instruction data from all epochs and randomly shuffled the samples to create the final fine-tuning dataset. This processing ensures an even distribution of instructions of varying difficulty levels in the dataset, maximizing model fine-tuning smoothness.
Wizardlm validates Evol-Instruct by fine-tuning open-source LLaMA 7B with evolved instructions and evaluating its performance and name the model WizardLM.
Evol-Instruct works by generating a pool of initial instructions(52k instruction dataset of Alpaca), which are then evolved through a series of steps to create more complex and diverse instructions. Once the instruction pool is generated, it is used to fine-tune an LLM, resulting in a new model called WizardCoder. The fine-tuning process involves training the LLM on the instruction data to improve its ability to generate coherent and fluent text in response to various inputs.
Prompt Format
For WizardCoder, the Prompt should be as follows:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
Best Use Cases
WizardCoder can be used for a variety of code-related tasks, including code generation, code completion, and code summarization. Here are some examples of input prompts that can be used with the model:
- Code generation: Given a description of a programming task, generate the corresponding code. Example input: “Write a Python function that takes a list of integers as input and returns the sum of all even numbers in the list.”
- Code completion: Given an incomplete code snippet, complete the code. Example input: “def multiply(a, b): \n return a * b _”
- Code summarization: Given a long code snippet, generate a summary of the code. Example input: “Write a Python program that reads a CSV file and calculates the average of a specific column.”
The 34B model is not just a coding assistant; it’s a powerhouse capable of:
- Automating DevOps Scripts: Generate shell scripts or Python scripts for automating tasks.
- Data Analysis: Generate Python code for data preprocessing, analysis, and visualization.
- Machine Learning Pipelines: Generate end-to-end ML pipelines, from data collection to model deployment.
- Web Scraping: Generate code for web scraping tasks.
- API Development: Generate boilerplate code for RESTful APIs.
- Blockchain: Generate smart contracts for Ethereum or other blockchain platforms
Evaluation
WizardCoder beats all other open-source Code LLMs, attaining state-of-the-art (SOTA) performance, according to experimental findings from four code-generating benchmarks, including HumanEval, HumanEval+, MBPP, and DS-100.
WizardCoder-Python-34B has demonstrated exceptional performance on code-related tasks. The model has outperformed other open-source and closed LLMs on prominent code generation benchmarks, including HumanEval (73.2%), HumanEval+, and MBPP(61.2%).
WizardCoder-Python-34B-V1.0 attains the second position in HumanEval Benchmarks, surpassing GPT4 (2023/03/15, 73.2 vs. 67.0), ChatGPT-3.5 (73.2 vs. 72.5) and Claude2 (73.2 vs. 71.2).
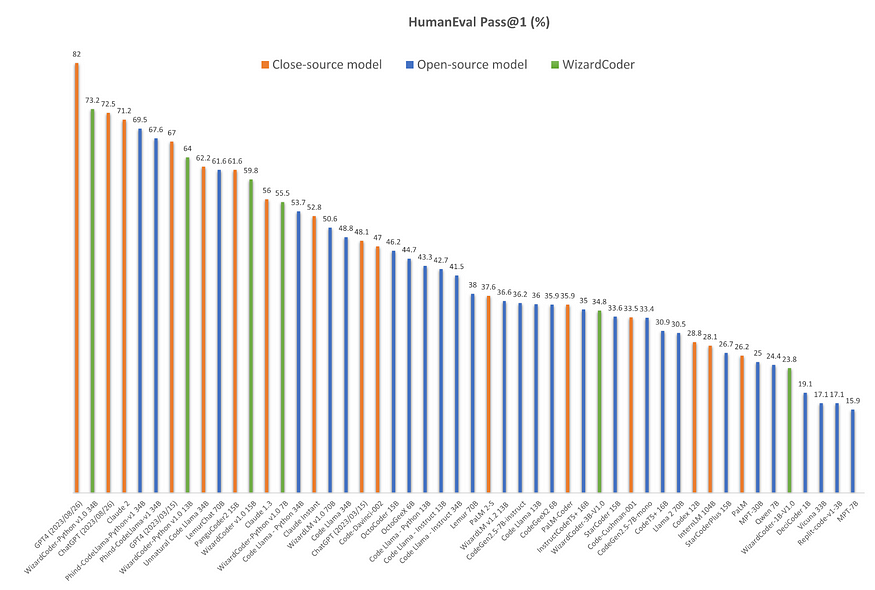
WizardCoder-15B-v1.0 model achieves the 57.3 pass@1 on the HumanEval Benchmarks, which is 22.3 points higher than the SOTA open-source Code LLMs, including StarCoder, CodeGen, CodeGee, and CodeT5+. Additionally, WizardCoder significantly outperforms all the open-source Code LLMs with instructions fine-tuning, including InstructCodeT5+, StarCoder-GPTeacher, and Instruct-Codegen-16B.
In conclusion, WizardCoder’s success is attributed to its unique dataset and the innovative use of Evol-Instruct to enhance instruction complexity, leading to its outstanding performance across various code-related tasks and benchmarks.
References
YouTube: WizardCoder 34B: Complex Fine-Tuning Explained
Paper: WizardLM- Empowering Large Language Models to Follow Complex Instructions
Paper: WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")