



Using Claude 3 to Transform a Video Tutorial Into a Blog Post
Last Updated on April 1, 2024 by Editorial Team
Author(s): Yann-Aël Le Borgne
Originally published on Towards AI.
The starting point for the writing of this article is a post on X from Andrej Karpathy who, shortly after publishing a 2h13 video tutorial on LLM tokenization, challenged for a workflow that would automatically convert the video in a book chapter/blog post:

A seemingly key-in-hand solution was then posted by Emmanuel Ameisen and colleagues from Anthropic: basically prompting Anthropic’s latest model — Claude 3 — to do the job.

Despite some issues and inconsistencies, the approach seemed fairly efficient. The resulting blog post retained most elements covered in the original video, together with relevant screenshots and code examples.
I wondered how easy and costly that would be to reproduce this task. As it turned out, the process was more complex than I initially anticipated. While the prompt was shared (kudos for that), the code was not.
This article aims to share my implementation, detail its different steps, and discuss its main challenges. The code and data are available in this Github repository.
TLDR:
- Transforming a video in a blog post/book chapter is another compelling use case for large multimodal models (LMMs), making video content accessible in a text format that’s easy to read, skim, and search
- However, text conversions based on LMMs can contain various inaccuracies and inconsistencies, requiring thorough revision and proofreading. Other challenges relate to the irreproducibility of the results and difficulties in identifying effective prompts
- Utilizing an LMM like Claude 3 Opus to transform videos in text format isn’t cheap. The solution presented in this article incurred costs of around $4 (for converting this 2-hour video into this blog post).
Workflow overview and technical constraints
Claude 3 Opus is the latest and most performant large multimodal model (LMM) provided by Anthropic. It was released on the 4th of March, and can be accessed either through a Web interface at claude.ai, or through an API.
The model can take as input up to 200K tokens of text or images, and can output up to 4K tokens of text. Let us briefly quantify more concretely what this means:
- 4K tokens for the output: Given the rule of thumb that a token is about 3/4 of a word, we get that 4K tokens translate to about 3K words. Assuming around 500 words per page, Claude can output a maximum of around 6 pages of text.
- 200K tokens for the input: Following the same statistics, this gives 150K words (about 300 pages). Assuming a speech tempo of about two to three words per seconds, this allows to ingest about 20 hours of audio transcript, which is quite a lot. Regarding images, encoding an image with a resolution of 1280*720 pixels (video HD) on the other hand requires about 1.25K tokens. Slightly more than 150 images can therefore in theory be provided as input in one go. In practice, one should note that, regardless of token usage, Anthropic API currently limits the number of input images to 20.
The two main constraints therefore lie in the limited number of images that can be provided as input, and the limited number of pages that the model can generate. The workaround consists in splitting the video in chapters, which are processed separately by the LMM. The outputs are then combined to produce the final document.
The diagram below summarizes the main steps of the workflow:
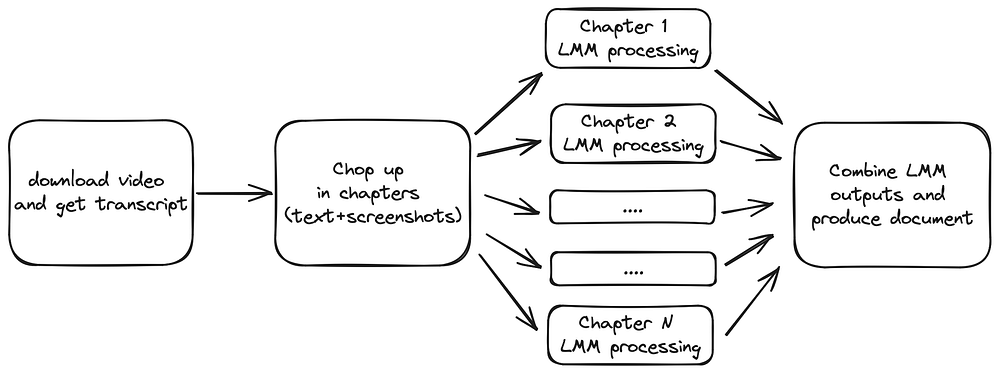
Ameisen & Co split the video according to the chapters outlined in the Youtube video description (24 in total). Other strategies could involve relying on topic segmentation tools such as LLMs to split the transcript in its main parts. A good rule of thumb is to aim at chapters of a few minutes, so that 10 to 20 screenshots may be included in the prompt together with the transcript.
Let us finally try to anticipate the processing costs. Token usage for Claude 3 Opus stands at 15$ per million input tokens, and 75$ per million output tokens.
Assuming chapters of 5 minutes, a two-hour video would give 24 chapters, each requiring on average:
- 13K input tokens (1K of text tokens and 10 images at 1.2K tokens/image)
- 1K output tokens (2 pages)
The gives a total of about 13*2≈300K input tokens, and 1K*24= 24K output tokens. Multiplying by the cost per million tokens, we get an input cost of 15*0.3=4.5$ and output cost of 75*0.024=1.8$.
The total cost to generate a post from a 2 hour video is therefore on the order of 5 to 10$. Note that optimization strategies can be used to more carefully select the screenshosts to include, and reduce input costs.
Implementation
Let us move to our implementation which follows the four main steps outlined in our workflow, namely:
- Download the video and get the transcript
- Chop up in chapters of aligned text and screenshots
- LMM processing of chapters
- Combine LMM outputs and produce blog post.
For the sake of clarity, we present for each step the most staightforward implementation. The companion notebook occasionally includes additional code with more advanced ways to process data.
Download the video and get the audio transcript
Assuming the video is on Youtube, let us first download the video using the pytube library. We download the whole video (and not only the audio stream) as we will later require the video frames to generate the blog post.
import pytube
# Andrej Karpathy : Let's build the GPT Tokenizer - https://www.youtube.com/watch?v=zduSFxRajkE
youtube_video_id = "zduSFxRajkE"
def download_youtube_video(video_id, output_path):
"""
Download a YouTube video given its ID, stores it in output_path, and returns the output path with the video ID as filename.
"""
# Create a YouTube object with the video ID
youtube = pytube.YouTube(f"https://www.youtube.com/watch?v={video_id}")
# Get the highest resolution video stream
stream = youtube.streams.get_highest_resolution()
# Download the video
video_path = stream.download(output_path=output_path, filename=video_id+".mp4")
return video_path
# About 20 seconds for 330MB video
video_path = download_youtube_video(youtube_video_id, DATA_DIR)
Note that for most Youtube videos, the transcript is readily available with the video. A library like youtube_transcript_api can be used to get the transcript by simply providing the Youtube video ID.
from youtube_transcript_api import YouTubeTranscriptApi
transcript = YouTubeTranscriptApi.get_transcript(youtube_video_id)
The whole 2h13 audio stream is transcripted in 3422 segments.
len(transcript)
3422
transcript[0:4]
[{'text': "hi everyone so in this video I'd like us", 'start': 0.04, 'duration': 4.04}, {'text': 'to cover the process of tokenization in', 'start': 2.04, 'duration': 4.4}, {'text': 'large language models now you see here', 'start': 4.08, 'duration': 4.2}, {'text': "that I have a set face and that's", 'start': 6.44, 'duration': 3.88}]
If a transcript is not available, the audio stream must be converted into text using a speech recognition model. The U+1F917 Open ASR Leaderboard is a good place to look for the best performing model. We provide in the companion notebook the code to get the transcript with a Whisper model, and its efficient faster-whisper implementation. The process take about 25 minutes using a T4 on Google Colab (or 12 minutes on an RTX 4090).
Chop up in chapters of aligned text and screenshots
Chapters may be identified manually, or using an automatic video chapter tool such as the one provided by YouTube. For our example video, we copied the 24 chapters outlined in its video description in a Python chapters_list object, as illustrated below.
chapters_list=[{'timestamp': 0,
'topic': 'Introduction and motivation for understanding tokenization'},
{'timestamp': 262,
'topic': 'Introducing the paper that introduced byte-level encoding for tokenization in GPT-2'},
{'timestamp': 933, 'topic': 'Unicode, UTF-8 encoding, and vocabulary sizes'},
...
]
The core of this stage then consists in extracting the text and screnshots according to the chapter’s start/end timestamps. This is achieved by the chop_up_in_chapters function which, for each chapter, identifies the start and end timestamps of the chapter, extract the corresponding text from the transcript, and extract screenshots from the video.
The strategy for extracting screenshots consists in uniformally sampling the video to extract a maximum of 10 screenshots for each given chapter, with no less than one minute between screenshots.
Extracted text and screenshots are stored in separate folders (having as name the chapter number).
def chop_up_in_chapters(chapters_list, video_path, transcript, timestamps_screenshots_list_seconds=None):
"""
Split the video in chapters based on the video chapters list.
"""
n_chapters=len(chapters_list)-1
print(f"Number of chunks: {n_chapters}")
# Iterate over the timestamps and topics
for current_chapter in range(n_chapters):
output_dir=CHAPTERS_DIR+"/"+str(current_chapter)
# Create the output directory if it does not exist
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Get the current and next timestamp
current_chunk_start_time=chapters_list[current_chapter]['timestamp']
current_chunk_end_time=chapters_list[current_chapter+1]['timestamp']-1
print(f"Chapter {current_chapter}; Start: {current_chunk_start_time}, End: {current_chunk_end_time}")
# Extract text and frames for the current chapter
get_text_chapter(transcript, current_chunk_start_time, current_chunk_end_time, output_dir)
if timestamps_screenshots_list_seconds is not None:
get_frames_chapter(video_path, current_chunk_start_time, current_chunk_end_time, output_dir,timestamps_screenshots_list_seconds[current_chapter])
else:
get_frames_chapter(video_path, current_chunk_start_time, current_chunk_end_time, output_dir)
Large Multimodal Model (LLM) processing
This is the core step. For each chapter, the audio transcript and selected screenshots are provided to the LMM, with the goal of transforming these input data into an output suitable for inclusion in a textbook.
The key element in this step is the LLM prompt, which we designed as follows:
prompt_instructions = """
<instructions>
You have been given images of a video at different timestamps, followed by the audio transcript in <transcript>
The transcript was generated by an AI speech recognition tool and may contain some errors/infelicities.
Your task is to transform the transcript into a markdown blog post.
This transcript is noisy. Please rewrite it into a markdown format for a blog chapter using the following guidelines:
- output valid markdown
- insert section headings and other formatting where appropriate
- you are given only part of a transcript, so do not include introductory or concluding paragraphs. Only include the main topics discussed in the transcript
- use styling to make images, text, code, callouts and the page layout and margins look like a typical blog post or textbook
- remove any verbal tics
- if there are redundant pieces of information, only present it once
- keep the conversational content in the style of the transcript. Including headings to make the narrative structure easier to follow along
- each transcript includes too many images, so you should only include the most important 1-2 images in your output
- choose images that provide illustrations that are relevant to the transcript
- prefer to include images which display complete code, rather than in progress
- when relevant transcribe important pieces of code and other valuable text
- if an image would help illustrate a part of a transcript, include it
- to include an image, insert a tag with <img src="xxxxx.jpg"/> where xxxxx is replaced by the exact image timestamp inserted above the image data
- do not add any extraneous information: only include what is either mentioned in the transcript or the imagesYour final output should be suitable for inclusion in a textbook.
</instructions>
"""
We mostly reused Ameisen’s prompt, with the following modifications:
- We changed the output format from HTML to markdown, to make it more straightforward to combine the LMM outputs (and the markdown format is visually well-suited for a blog post)
- We removed the visual and writing style images as we did not notice they added useful information once the output format was defined as markdown
- We changed some formatting in the prompt to better follow Anthropic’s guidelines. In particular, we moved the screenshots at the beginning and we wrapped instructions in XML tags.
The prompt is preceded by the chapter’s screenshots and the transcript. We defined a get_screenshots_as_messages helper function to transform the JPG screenshots in a format suitable for Anthropic’s vision API. The function iterates over all screenshots in order to describe each of them with two messages: a text message that specifies the timestamp for the screenshot, and an image message containing its base64-encoded representation. The text message with the timestamp will allow later to add a hyperlink from the final document to the original video.
def get_screenshots_as_messages(screenshots):
screenshots_as_messages = []
for i in range(len(screenshots)):
screenshots_as_messages.extend([
{
"type": "text",
"text": f"The timestamp for the following image is {Path(screenshots[i]).stem}."
},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": base64.b64encode(open(screenshots[i], "rb").read()).decode("utf-8"),
}
}])
return screenshots_as_messages
We defined another helper function get_prompt_as_messages to bring together the screenshots, transcript and instructions. The function additionally prefills Claude’s output to make it start its answer with a markdown title (“#”).
def get_prompt_as_messages(chapter_id):
folder_path=CHAPTERS_DIR+'/'+str(chapter_id)
with open(folder_path+'/transcript.txt', "r") as f:
transcript = f.read()
screenshots=sorted(glob.glob(folder_path+'/*.jpg'))
screenshots_as_messages=get_screenshots_as_messages(screenshots)
prompt_as_messages = [
{
"role": "user",
"content": screenshots_as_messages+
[
{
"type": "text",
"text": f"<transcript>\n{transcript}\n</transcript>"
},
{
"type": "text",
"text": prompt_instructions
}
],
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "#"
}
]
}
]
return prompt_as_messages
And that’s it!
All chapters can then be processed by iteratively calling Claude, and writing the result as a markdown file in the corresponding chapter folder.
# Iterate through the list of chapters
for chapter in range(len(chapters_list)-1):
# Generate the prompt for the current chapter (list of messages with screenshots, transcript and instructions).
prompt_generate_markdown = get_prompt_as_messages(chapter)
# Create a message by invoking Claude with the prompt.
message = client.messages.create(
model="claude-3-opus-20240229",
system="You are an expert at writing markdown blog post.",
temperature=0,
max_tokens=4000,
messages=prompt_generate_markdown
)
# Extract the generated markdown content from the response.
answer = message.content[0].text
markdown = "#"+answer # Prepend a header tag to the markdown content.
# Define the path for the markdown file corresponding to the current chapter.
markdown_file = CHAPTERS_DIR + '/' + str(chapter) + '/markdown.md'
# Write the generated markdown content to the file.
with open(markdown_file, "w") as f:
f.write(markdown)
We report below a subset of Anthropic’s usage logs for the processing of the last seven chapters, to give an idea of the processing times, and variations in numbrs of input and output tokens.
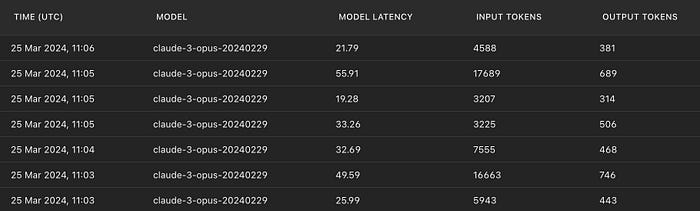
The longest chapter was the last but one (see chapters here), from 1h51 to 2h10, totalizing 17689 tokens for a processing time of almost one minute. Overall, it took about 10 minutes to process the video and its 24 chapters, using 180K input tokens and 15K output tokens, for a cost of about 4$.
Combine LMM outputs and produce final blog post
The final and last step of the workflow consists in two main tasks. First, it merges together the different markdown outputs. Second, it adds hyperlinks to chapter titles and images. This allows to connect the final markdown file to the original YouTube video at relevant timestamps.
merged_markdown=""
# Iterate over the chapter folders to merge the markdown files
for chapter in range(len(chapters_list)-1):
markdown_file=CHAPTERS_DIR+'/'+str(chapter)+'/markdown.md'
with open(markdown_file, "r") as f:
markdown = f.readlines()
# Let us add, for each chapter title, a hyperlink to the video at the right timestamp
url_chapter = f"https://www.youtube.com/watch?v={youtube_video_id}&t={chapters_list[chapter]['timestamp']}s"
markdown[0] = f"# [{chapter+1}) {markdown[0][2:].strip()}]({url_chapter})"
markdown = '\n'.join(markdown)
merged_markdown+="\n"+markdown
# Find all <img> tags with timestamps in the src attribute, so we can add a hyperlink to the video at the right timestamp
timestamps_screenshots = re.findall(r'<img src="(\d+)\.jpg"/>', merged_markdown)
timestamps_screenshots = [timestamp for timestamp in timestamps_screenshots]
# Add a hyperlink to the video at the right timestamp for each image
for timestamp in timestamps_screenshots:
video_link = f'<a href="https://www.youtube.com/watch?v={youtube_video_id}&t={int(timestamp)}s">Link to video</a>'
merged_markdown = merged_markdown.replace(f'<img src="{timestamp}.jpg"/>', f'<img src="{timestamp}.jpg"/>\n\n{video_link}')
# Get frames based on screenshots effectively selected in the merged markdown and save in merge folder
get_frames_chapter(video_path, None, None, MERGE_DIR, timestamps_screenshots=timestamps_screenshots)
# Save the merged markdown to a markdown blogpost.md file
markdown_file=MERGE_DIR+'/blogpost.md'
with open(markdown_file, "w") as f:
f.write(merged_markdown)
The merged markdown file is then saved as ‘markdown.md’, together with all the selected JPG screenshots in the MERGE_DIR folder (final output).
Discussion
The resulting post successfully preserved most of the original video’s content, achieving a quality similar to the one described by Ameisen and his colleagues. It also correctly identified relevant screenshots and code snippets that help enhance the understanding of the audio transcript. However, the process is not without flaws, particularly in the accuracy of the text converted.
Thorough editing and proofreading is still needed to address inaccuracies and inconsistencies. Examples of issues (mirroring those found in Ameisen’s work) include erroneous explanations of token counts for instance, mistakenly counting the “hello world” token as 300 instead of the correct 2, misnumbering the first token in “tokenization,” and inaccurately considering spaces as tokens (see blog post’s chapter 2). Aside from these inaccuracies, the methodology also raises other challenges, such as the complexity of crafting effective prompts, the irreproducibility of the results, and the costs associated with operating LMMs.
Despite these drawbacks, transforming a video into an accessible and easy-to-navigate text blog post remains a valuable application of large multimodal models. A comparison with the video/image understanding capabilities of competing LMMs, in particular GPT4-V, Gemini Pro Vision and the open-source Large World Model will be the subject of an upcoming blog post.
Useful links
- Companion Github repository
- Karpathy’s challenge and Ameisen and colleague’s repository
- Video tutorial on tokenization : https://www.youtube.com/watch?v=zduSFxRajkE and hand-written tutorial summary: https://github.com/karpathy/minbpe/blob/master/lecture.md
- Claude 3 — Vision documentation
- Another approach by Misbah Syed
Notes: Unless otherwise noted, all images are by the author.
Enjoyed this post? Share your thoughts, give it claps, or connect with me on LinkedIn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

