


All about MLOps: why, what, when & how
Last Updated on March 31, 2024 by Editorial Team
Author(s): Akhil Anurag
Originally published on Towards AI.
Machine learning(ML) applications have mushroomed everywhere, with it the desire to move beyond the pilots and proof of concepts to deliver significant value to consumers while overcoming the unique complexities of building ML-driven applications.
While building and deploying an ML system may look easy but managing & maintaining them for every change over time with scale is difficult and leads to the accumulation of large technical debt over time. The change in ML code is a small part of all the changes that need to happen in the overall complex system.
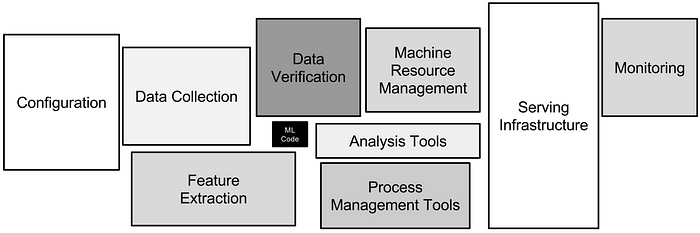
Anyone working in the trenches to make an ML product live will vouch for the needs of practices, processes, and capabilities that may standardize the entire workflow while making the systems more reliable and scalable. This promised land goes by the name of MLOps in the ML/AI landscape.
Machine learning operations(MLOps) are the set of practices and capabilities that are built to effectively develop, test, deploy, release, and maintain ML applications in a standardized, efficient, rapid, and reliable manner.
Before we deep dive into these practices & capabilities and the benefits they bring, let’s spend some time on why we need them in the first place.
The “why” part is the one product & technology leaders struggle with the most today as the slow adoption of MLOps in the ML product space can be attributed to not clearly articulating the value drivers of MLOps adoption and hence inability to establish its business/investment case.

Other widely adopted practices on data engineering and software development fall under the remit of DataOps and DevOps respectively
Step 1: Start with “Why”?
Organizations today, across domains, involved with building ML products are at different maturity levels in terms of how they go about building and operationalizing ML solutions through different products.
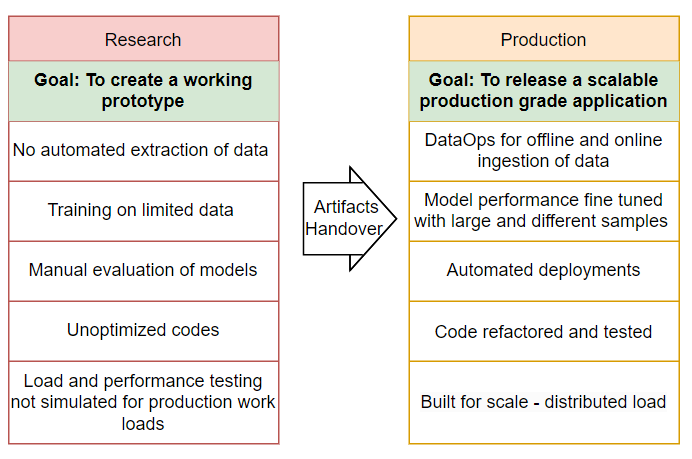
At the most fundamental level, there is a large gap in what an ML solution looks like in research to how it should work in production. The ML development which happens mostly as part of the research stage, creates artifacts like code and configs which are then thrown over to production teams who are accountable for building and maintaining these solutions at scale.
#Problem 1: How to avoid this messy handshake and how to build production-grade systems from the very start are potentially the biggest obstacles to solve for if the organization wants to reduce the overall cycle time and deliver its products faster to end users.
If any of the MLOps practices or technical capability can solve this, then that answers why you need it.
Organizations are also different in terms of the maturity of how they build ML products. Some are ahead and some still lagging. As MLOps brings a framework to establish mature practices for building and operationalizing ML systems, organizations need to do an honest assessment first of their existing practices to identify if MLOps will bring any incremental value or not.
Organizations based on their ML delivery maturity can be bucketed into the categories of No, Low, and High MLOps, as shown in the diagram below.

No MLOps — Organizations that are working without any MLOps practices and trying to deploy the same solutions that are built in the research phase with data scientists. You can identify them easily by:
- Large failure rates — These organizations are not able to deploy most of their solutions in production.
- Poor consumer experience — Even if they deploy, they would need manual intervention and constant customizations because something would break now and then.
Low MLOps — Organizations that are working with some MLOps practices and have identified a way to deliver their product at some scale. You can identify them easily by:
- Long productization cycle — Here, ML engineers alone or in pairs with Data scientists will be responsible for making the solution production-ready. This is where the heavy lifting happens and hence a long window is required to make the solution production-ready.
- Semi-scale — These ML solutions are not fully scalable. example — you can deploy these to 3 customers but not to 30 without the constraints of additional people and resources.
High MLOps — Organizations that have identified and adopted MLOps capabilities suitable to their needs can serve customers in a faster, reliable, and scalable way with the right quality. You can identify them easily by:
- Shorter cycle time — Able to deliver value to end users in a reduced time
- Better collaboration between teams — Easy for Data Scientists, Data and ML Engineers, and Software Engineers to work together as one team
- Automated deployments — Single-click deployments with no manual intervention. Minimal or no productization effort, as what is built from the start is production-ready.
- Scalable and reliable — Systems are scalable and maintainable with more data, more models(use cases), or more users leading to happy customers
#Problem 2: Once you identify where your organization sits with maturity and expectations from MLOps, how do you know what MLOps capabilities you need to solve for?
If you are on the lower maturity side and have a need or desire to move to the other end, that is another reason why you need MLOps.
Lastly, MLOps practices and capabilities should be tied very closely to the business objectives you want to achieve and the domain in which you operate. Some indicative examples:
- For a B2B organization responsible for developing and deploying ML applications, successful adoption of MLOps should result in a shorter cycle time to deploy to a new business and the ability to scale
- For a D2C organization, MLOps should not only scale but also maintain the desired quality and performance of the models for its customers
- For a B2C organization, MLOps should help you curate and create different features ready for consumption that can be experimented with diverse ML use cases to drive and deliver the best value for customers
#Problem 3: For your business objectives, which MLOps practices and capabilities are most sought after and to what degree do you need to adopt them?
If you are struggling to achieve your business objectives and MLOps adoption can help, then that is why you adopt it.
Step 2: If clear with “Why”, start with “What”?
MLOps provides a structured and iterative set of stages to develop, operationalize, and manage an ML project. These stages are better known as MLOps lifecycle and can be used to map any ML process end to end. To answer what MLOps component you need, one first needs to understand this lifecycle, as your missing MLOps practice can be across one or more of these stages.
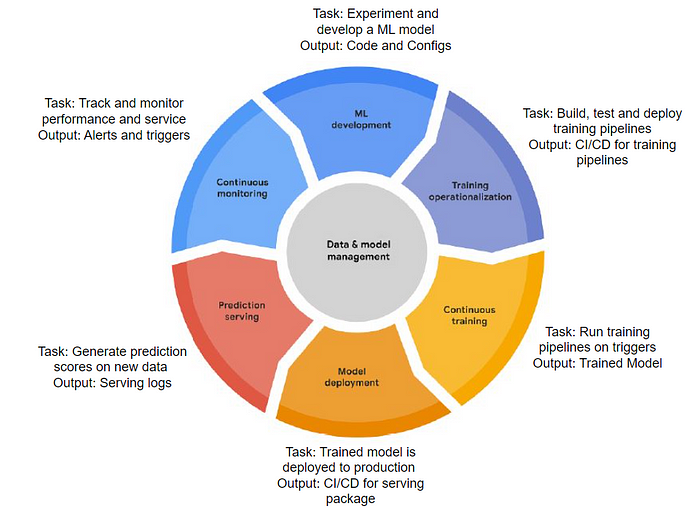
To implement MLOps across different stages of the lifecycle, MLOps offers a set of technical practices and capabilities. Some of these capabilities are core capabilities abstracted as functional components while some are cross-cutting interacting with multiple stages of the lifecycle. These technical capabilities are outlined in the form of the process diagram below.

Here is a description of these MLOps capabilities and their utility:
- Feature store — Feature store facilitates the creation, reusability, and availability of features for training and serving pipelines, thus enabling these features to be shared by multiple teams for different use cases. Feature storing in MLOps deals with creating, storing, and managing these features that can be directly consumed in the ML models.
- Experiment Tracking — In the ML development stage, data scientists are typically involved in discovering the best model. This discovery needs experimentation with features, algorithms, hyperparameters, configurations, etc. The key success of this process lies in tracking these experiments and making them reproducible for comparison. This is where experiment tracking with MLOps comes in, providing the capability to log, store, organize, and compare all the ML experiments in one place.
- Meta Data Store — In the MLOps lifecycle, different ML artifacts are produced across different stages, and the information about these artifacts is captured in the metadata store. Tracking the metadata on data, models & systems helps in traceability and lineage tracking. The metadata stored in MLOps, once integrated with other capabilities, helps to store, access, and reproduce ML artifacts for different experiments and tasks.
- Version Control — Version Control in ML, like in software development, is used to track and manage changes over time. In ML, changes can happen either with code, data or model. All these changes need to be controlled using version control for better collaboration, reproducibility, dependency tracking and managing version updates.
- CICD Routines — A CI/CD pipeline is an automated workflow to rapidly implement changes and automatically build, test and deploy these changes to production. CI/CD in MLOps is required to enable automated and thus faster deployments as well as eliminate errors caused by manual intervention.
- Model Registry — This MLOps capability is used to govern the quality of production models by registering, versioning, and tracking trained and deployed ML models along with their metadata and dependencies.
- Orchestrator — Pipelines to schedule, trigger, and monitor workflows in an automated fashion for scheduled(offline) or real-time(online) scoring.
- Telemetry — This MLOps capability monitors the quality of the model, data and system deployed in productions for any deterioration or change in behavior. Telemetry allows you to do corrective actions like retain the models when a trigger or alert is observed based on model, data or system drift.
- Auto ML — MLOps system to automate end-to-end model development and serving process.
Step 3: Let’s discuss “When” and “How”?
On the question of when to adopt MLOps, a few factors need consideration:
- Can you justify the investment case for MLOps? — if you don’t have the investment to build these capabilities, unfortunately, you can’t do much. This is where “why” becomes an anchor to drive “when”.
- To tap ML to achieve full business value — If your ML build and operations are constrained by the scale, MLOps adoption is something you need to start to scale machine learning in the enterprise.
- Have a strong ML pipeline for deployment— One of the core capabilities MLOps brings is automating key steps of the ML lifecycle and thus reducing the overall cycle time. You should prioritize adopting MLOps if you have customers waiting at the other end for the ML solution to be deployed. No one likes an unhappy customer.
- MLOps can sometimes also be overkill if the organization has not figured out multiple ML use cases and the existing scale is still not a problem in delivering them. In this case, build more ML use cases and streamline internal processes to get them deployed before doing a big-bang MLOps adoption.
Assuming you have figured out a business case for MLOps adoption by now and would like to get the ball rolling.
How do you proceed? The key questions you need to ask are:
All MLOps capabilities or some of them to start with?
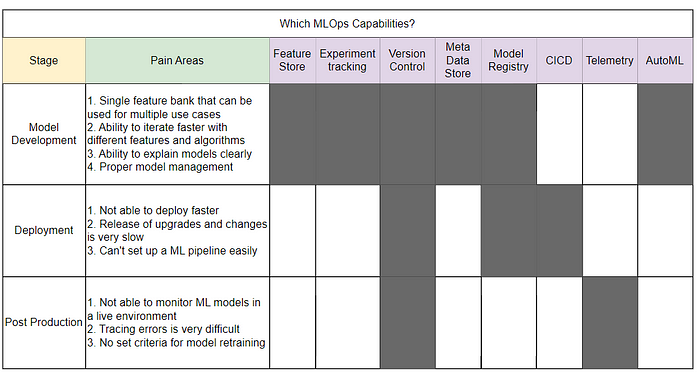
To identify whether you need most of MLOps capability for your business or some of it, you need to assess where the majority of problems lie in the ML lifecycle. Here is a simple but effective way to do this exercise, break down your pain areas across different ML stages and map them to the different MLOps capabilities we discussed in the “what” section.
Buy or Build?
Another key consideration in building MLOps is whether to build it internally or get it from outside. This is more of a strategic discussion, dependent on the skills, exposure, and experience available internally to build these different MLOps capabilities.
On the buy route, you might have to decide if you want to get these from vendors providing the MLOps platform or service providers who will build it for you.
Open Source vs. Closed Source?
Another consideration is if you want to go the open-source route or the closed-source route. Again, this might be more of a strategic decision when choosing your MLOps partner.
Open Source MLOps Platform — Vertex AI, Amazon Sagemaker, DataRobot, Modelbit etc.
Closed Source MLOps Platform — Mlflow, Airflow, Kubeflow, ZenML, DVC, etc.
Summary
- Take a good stock of your current ML process to establish the need for MLOps. You might not need it or be ready for it yet. If you need one, you should be able to clearly articulate the value proposition.
- Understand what are the different MLOps capabilities and where they fit in the overall ML lifecycle.
- Identify what you need and start small with MLOps; big-bang MLOps adoption might prove counterproductive.
- Think of long-term strategy while deciding how you will build these MLOps capabilities.
Like this article? Please follow me on Medium or Linkedin, where I share more from my experience.
Here is another one you might like. Thank you!
5 Ways to Fail at Building Machine Learning Applications
and your guide to avoid them while you are at it!
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

