



Trends in AI—March 2022
Last Updated on March 24, 2022 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A monthly selection of ML papers by Zeta Alpha: Audio generation, Gradients without Backprop, Mixture of Experts, Multimodality, Information Retrieval, and more.
March has arrived packed with developments in the world of AI: publications and conferences keep coming, such as the WSDM conference just behind us and AAAI also having just wrapped up. But let’s start by highlighting some recent news:
- DeepMind announced they’ve successfully used Deep Learning to control plasma in fusion science (see also paper in Nature). Fusion energy has long been the about-to-be-accomplished dream of energy production by humans: little stars to generate cheap and clean energy. This development will hopefully empower scientists to better understand how plasma behaves in fusion reactors.
- arXiv now officially supports viewing papers as responsive web pages, to try it out, replace the arxiv with ar5iv in any paper URL. This is the result of a collaboration with the KWARC research group with support from the LaTeXML project (a LaTeX to XML translator). We’re skeptical that this will challenge the deeply-established PDF as the standard for digital scientific dissemination, but the option is a very welcome addition!
- PyTorch’s release of TorchRec (GitHub repo): a “domain library built to provide common sparsity & parallelism primitives needed for large-scale recommender systems”.
Miscellaneous: evojax (library for hardware-accelerated neuroevolution), Uber now uses Deep Learning for ETA, and MuZero is used for video compression.
🔬 Research
Zeta Alpha monitors trending AI research to help you determine what’s worth reading. With its help, we’ve selected 10 papers that exemplify key developments in a diverse set of AI subfields: Information Retrieval, Multiplexing, Neural Rendering, Vision-Language multimodality, alternatives to Backpropagation, and more. Enjoy!
1. Transformer Memory as a Differentiable Search Index
By Yi Tay et al.
❓ Why → Information Retrieval has made tremendous progress in the past 4 years since the neural revolution finally caught up. Differentiable Search Index (DSI) is a really out-there idea that could be… either irrelevant in the long run or paradigm-shifting?
💡 Key insights → Identifying entities is relevant when one entity can have different names or a given name can be ambiguous without context (e.g. does Manchester refer to the city or its football club?). Previously, some sort of Information Retrieval method was often used to retrieve the identity of entities appearing in text from an index of known entities. Autoregressive Entity Linking⁶ (AEL) challenged this procedure by proposing to identify entities in text by autoregressively generating their canonical identifier (e.g. their full name string).
Now, the Differentiable Search Index (DSI) draws inspiration from AEL, applying it to document retrieval. Instead of retrieving a document by doing some lexical matching, embedding nearest neighbor search, or reranking via cross-encoding; the model simply learns to generate autoregressively a list of document ids that are relevant to the given query. This is a priori mind-blowing cause document ids contain no semantically relevant information: if a new document appears and is given a new id, you can’t infer anything about its content.
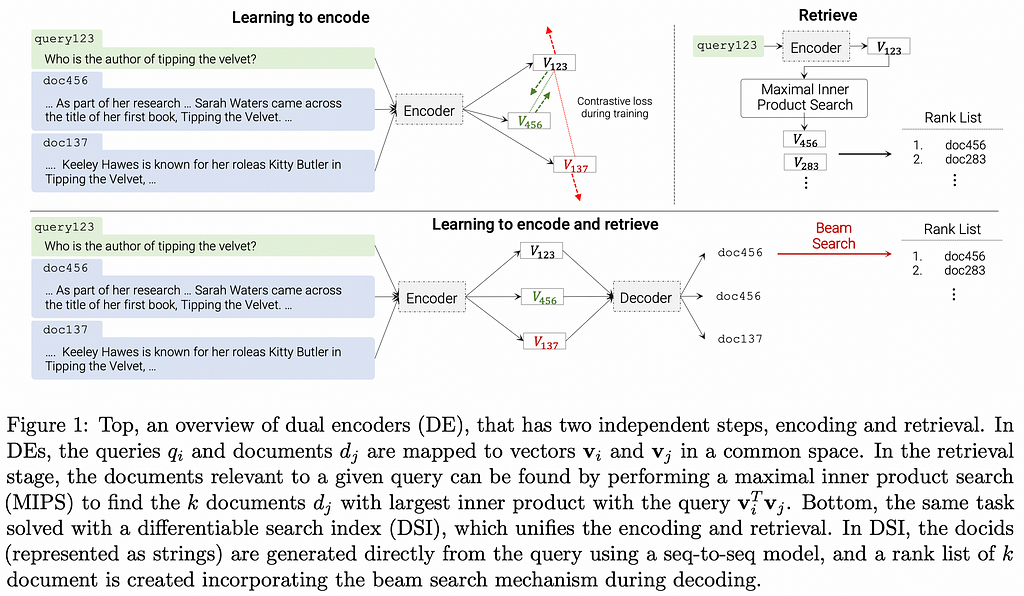
Intuitively, you can think of this as the document semantics from the whole corpus being encoded into the parameters of a model such that the model acts as a map between queries and document ids. In consequence, at inference, the model performs retrieval without even looking at the corpus it’s retrieving from.
The experimental results include different design choices for document ids: for instance comparing unique token per document vs. structured semantic doc ids which rely on hierarchical navigation to identify a document. All in all, results on the Natural Questions dataset⁷ are very promising, improving solid baselines such as T5 and BM25. Interestingly, results improve dramatically with model size; which goes in line with what one would expect intuitively: after all, the whole corpus needs to be “memorized” into the model parameters!
Still, many questions remain: how well can this translate to very large indexes? What about the sparsity of annotations? Can this work somehow with changing indexes and novel documents? Future research will tell, and it’s exciting.
2. DataMUX: Data Multiplexing for Neural Networks
By Vishvak Murahari, Carlos E. Jimenez, Runzhe Yang, Karthik Narasimhan.
❓ Why → Speed up inference with little* performance cost…? *Well, to be honest only a little is an optimistic reading of the results, but this is still a compelling practical idea!
💡 Key insights → Data multiplexing is a widely used method in signal processing where multiple signals are combined into one with the goal of being transmitted through a channel more efficiently. The authors of this paper propose an analog process for discrete representations used in ML. This process is simple conceptually:
- Downsample a very large batch into a workable size (e.g. 640 → 64) just with linear transformations and pooling
- Run the batch through your model.
- Upsample the predictions for each sample to the original size (e.g. 640).
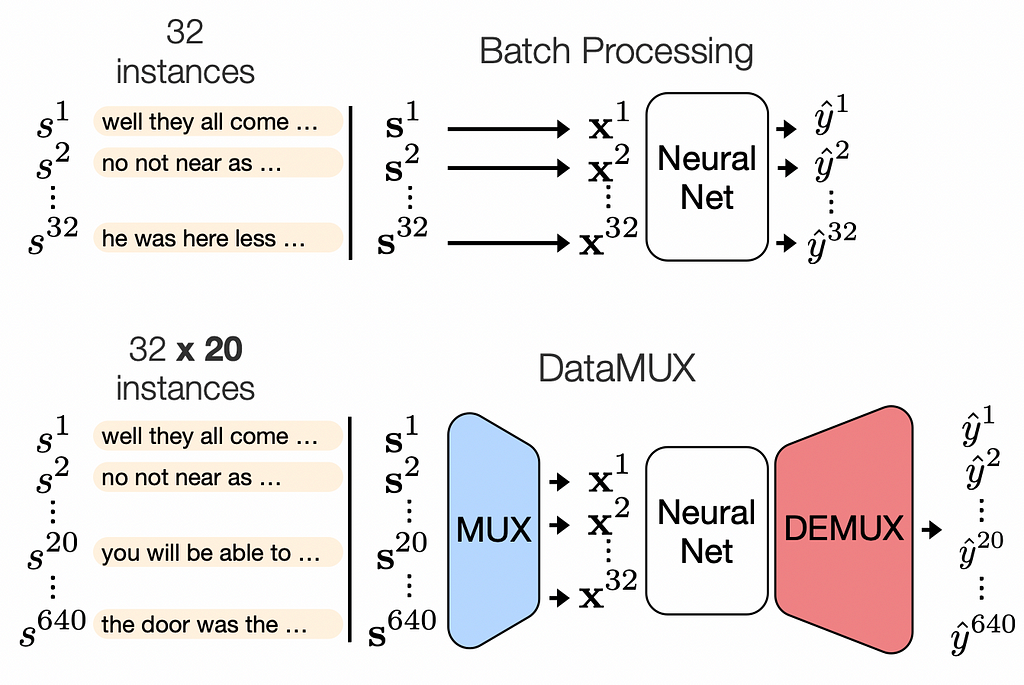
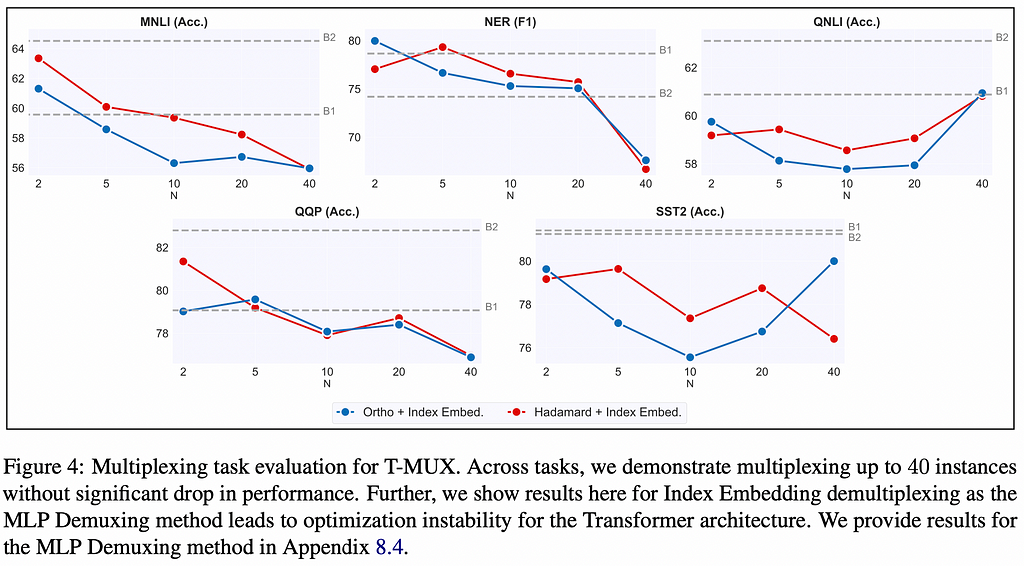
The main advantage of this method is quite self-evident: if you’re running batch inference where performance is key, you can achieve massive speedups with this kind of processing. The paper also includes some theoretical analysis on how the attention mechanism can work to model inputs that have been fused into single embeddings, although this procedure is architecture agnostic.
The performance drop in the NLP tasks they test on (sentiment analysis, natural language inference, named entity recognition) are in the order of a few percentual points when doing a 10–20x downsampling. While not a steep drop, it’s unclear how well this would translate to other tasks and modalities, given that these NLP tasks are “not particularly challenging” for modern large models.
In addition, experiments in this paper rely on full end-to-end training of the model with multiplexed data; an interesting question to explore in my opinion would be: how well can this be done given a frozen model that was trained on regular inference (not multiplexed). This could be relevant in the context of applying multiplexing to existing very large models which are very costly to retrain.
3. It’s Raw! Audio Generation with State-Space Models
By Karan Goel, Albert Gu, Chris Donahue, and Christopher Ré
❓ Why → (Very) long-range — several thousand steps — dependencies in sequence modeling remain a challenge in Machine Learning. In raw audio generation, this is a problem because digital waveforms are sampled at around 40kHz, making very long-range dependencies the norm.
💡 Key insights → State-space representation is a mathematical model of a physical system — commonly used in control theory — that describes it in terms of the state of a system, its time derivative, inputs, and outputs. This type of representation (relying on matrices and vectors) lends itself very well with the linear algebra toolset which makes it ideal for analytically proving and reasoning about dynamics, stability, and modes of a system.
The problem with applying this kind of representation to Deep Learning models is its computational tractability. Recently, Efficiently Modeling Long Sequences with Structured State Spaces¹ proposed a new parametrization of the SSM into a NN — named S4 — which includes several numerical tricks to make the computation tractable.
This paper applies this model to raw unconditional audio generation calling it SASHIMI, aiming to solve the 3 big challenges of raw audio generation: global coherence, computational efficiency, and sample efficiency. Moreover, an added benefit of using an SSM to model waveforms is that it can be computed both as a CNN (fast for non-autoregressive, parallelizable generation) and as an RNN (fast for pure autoregressive generation).
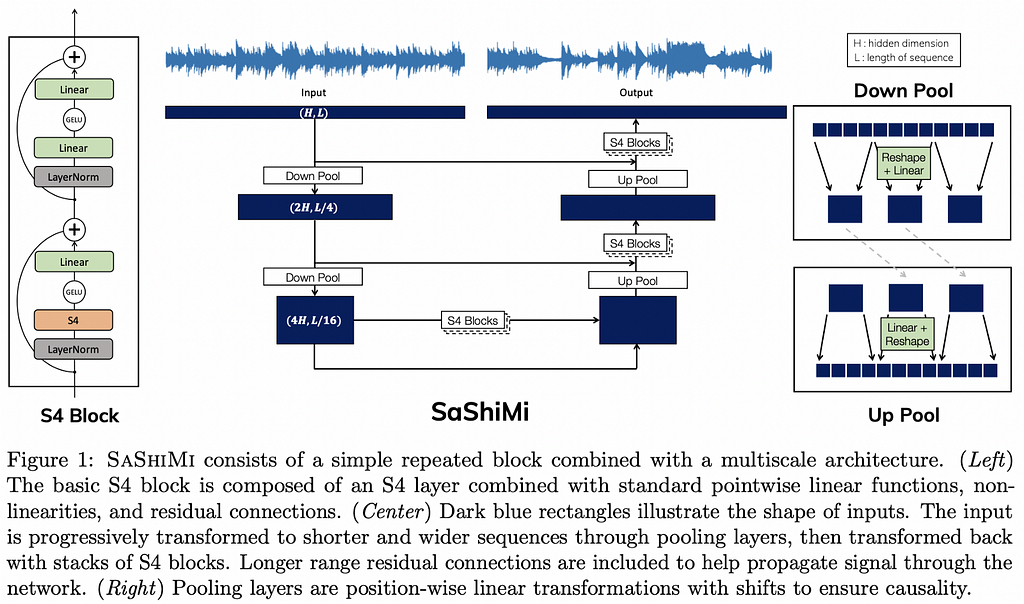
When it comes to the empirical results, SASHIMI seems stable to train and reaches better Negative Log Likelihoods than architectures like WaveNet and SampleRNN. Interestingly, the authors also show how simply swapping the architecture from DiffNet² into SASHIMI (parameter-matched) improves performance without any tuning.
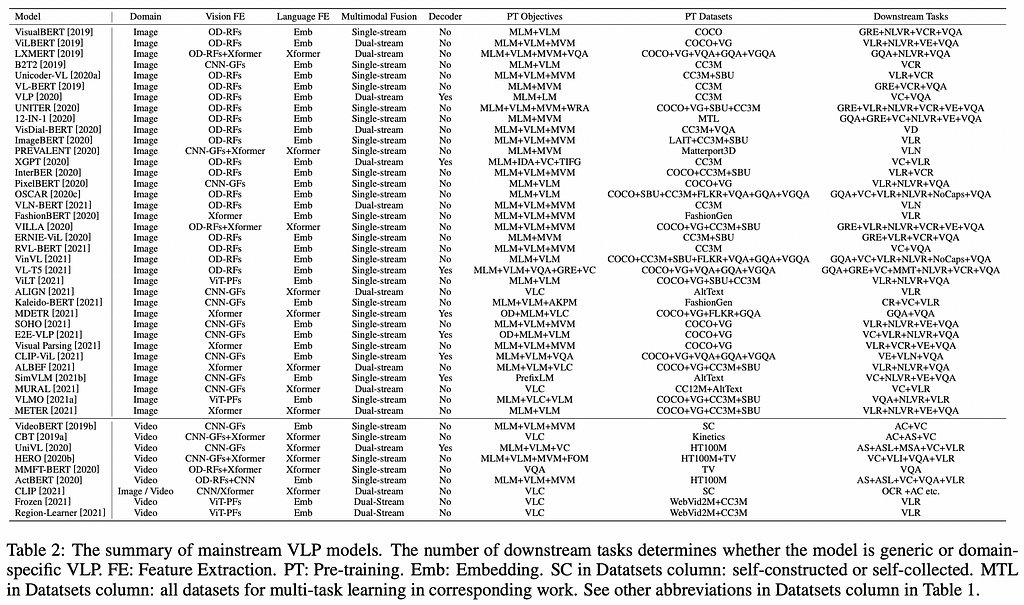
4. VLP: A Survey on Vision-Language Pre-training
By Feilong Che et al.
❓ Why → We’ve been highlighting multimodal ML vision-language works for many months now. The space has become so large it’s challenging to navigate, so here’s some help.
💡 Key insights → This short survey is a snapshot of the subfield that includes a taxonomy with the relevant defining features of existing approaches, along with their introduction and
- Training objectives
- Vision features and language features
- Types of modality fusion
- Downstream tasks application
- Labeled datasets used
- Encoder-decoder vs. encoder only models
If there’s an extension I’d like to see made this survey, is a more in-depth inclusion of recent multimodal works like relying on prompting such as Multimodal Few-Shot Learning with Frozen Language Models³, which we’ve highlighted in a previous blog post.
5. Designing Effective Sparse Expert Models
By Barret Zoph, Irwan Bello, et al.
❓ Why → Mixture of Experts (MoEs) are another one of our recurrent topics: scale to even more parameters, reduce computational cost of inference. If you’re thinking about building a massive MoE, look no further, you’ve found your guide.
💡 Key insights → The key concept of MoEs is simple: route an input only through sub-paths within the model during inference, such that only a fraction of the model parameters are used at each step. As usual though, the devil’s in the details, and several design choices are key to successfully building and training a largeMoE. This design guide dives deep into such key aspects:
- Stabilizing training: there’s often a tradeoff between stability and quality tradeoff — using optimization techniques that ensure stability such as regularizations or gradient clipping often hurts the performance of the resulting model. How to avoid this problem? They introduce a novel router z-loss.
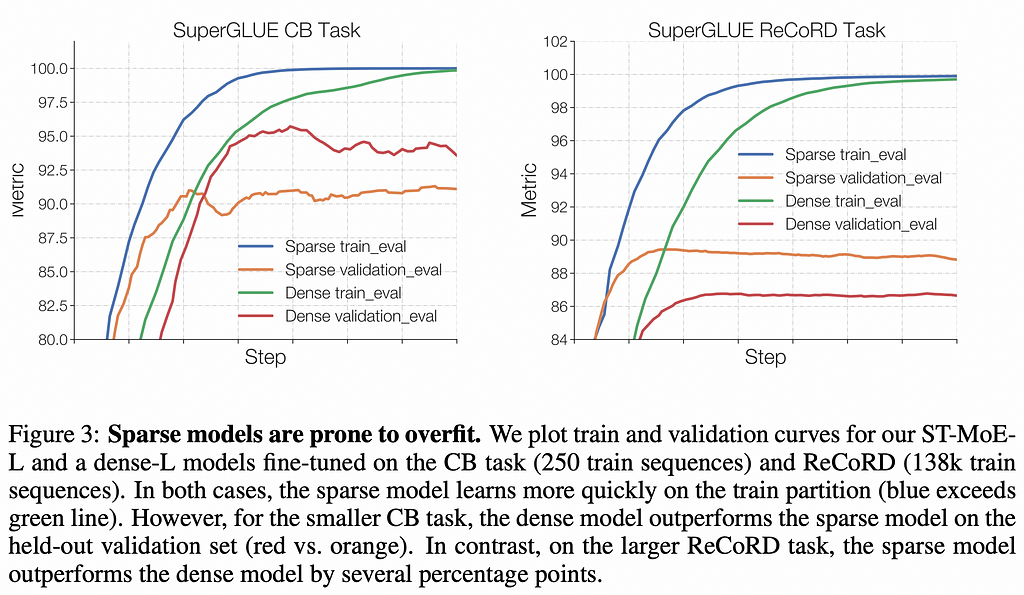
- Finetuning performance in downstream tasks: while MoEs excel at the regime of large datasets, they sometimes perform worse than their dense counterparts when finetuning. Why is this and how can it be avoided?
- Designing MoE architecture: choosing the number of experts and the capacity factor of the routing mechanism.
- A qualitative exploration of model behavior on how tokens are routed through MoEs.
This guide culminates in a 269B MoE sparse model (the Stable Transferable Mixture-of-Experts or ST-MoE-32B) which achieves state-of-the-art performance across a diverse set of natural language benchmarks.
6. Gradients without Backpropagation
By Atılım Güneş Baydin et al.
❓ Why → What? Gradients without backprop? How’s that? Why does one even want that? 👇
💡 Key insights → Finite differences is a numerical method for approximating the derivative of functions: evaluate it a bit to the right, a bit to the left, and estimate its rate of change at that point. In multiple dimensions though, the derivative becomes a gradient (a vector) and things get a bit more tricky. In very broad strokes, this paper proposes a method for estimating gradients that relies on finite differences: sample random vectors (perturbation vectors) in the dimensionality of your parameters, estimate the gradient with finite differences for each of them and average them to get an unbiased estimation of the gradient.
Intuitively, instead of having an analytical derivation of the chain rule throughout the neural network; when the forward pass is done, the gradient of each parameter with respect to its neighboring parameters — evaluated at the parameter value — can be estimated with this numerical procedure.
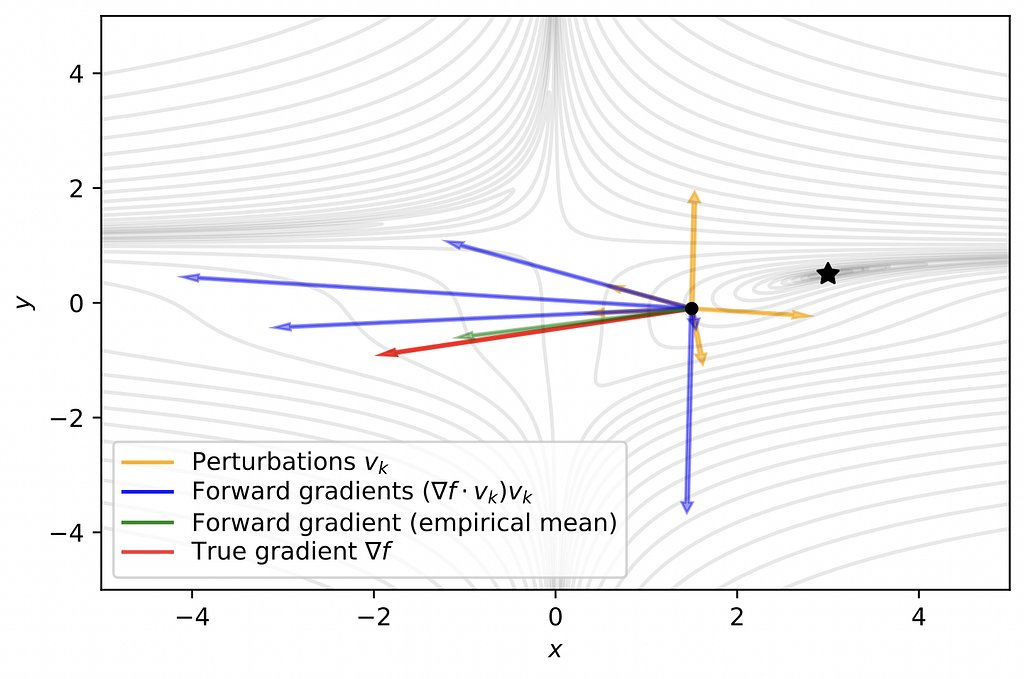
The authors call this forward gradient and prove some nice properties theoretically such as its unbiasedness and showcase some toy examples of how gradient descent can be applied with this technique successfully.
Now you might be asking: why would we even want that? Isn’t backprop just fine? For starters, this method achieves a slightly better runtime computational cost with similar memory requirements compared to backprop. But perhaps more importantly: backprop has often been criticized from the neuroscience camp as not being biologically plausible, cause neurons just don’t have the capacity to “communicate in reverse mode”⁵ (aka don’t have backward connectivity). Could this be a step towards a learning mechanism that’s biologically plausible? The authors hint this might be the case, although this will certainly require further inquiry.
If you want to dive deeper into this method but are not very familiar with the techniques used, I found this explainer blog post on TDS by Robert Kübler extremely useful. There’s also a coetaneous ICLR 2022 paper proposing a similar approach: Learning by Directional Gradient Descent.
7. Hierarchical Perceiver
By João Carreira et al.
❓ Why → The one architecture to rule them all get an upgrade.
💡 Key insights → This is a new version of the Perceiver⁹, which was a Transformer-based approach that could be applied to arbitrary modalities as long sequences (up to 100k!) of tokens: vision, language, audio-visual tasks.
This is a conceptually simple next step that shows how the sequence input to a Perceiver can be chunked in a modality agnostic way, processed separately, and later merged successfully, which the authors refer to as “introducing locality” processing. Below you can see an overview diagram of this process.

The main advantage of this approach when compared to its predecessor is that higher resolution input can be fed to the model. Interestingly, this paper explains that to encode positional embeddings, hand-crafter Fourier positional embeddings work better than learned position embeddings, unlike for unimodal text or vision applications.
The results show competitive performance (but not necessarily state-of-the-art) on image classification, audio-visual classification, and semantic segmentation; but these results still rely on some domain-specific data augmentations. The dream of full-on modality agnostic ML is far, this seems like a step in the right direction.
8. Block-NeRF: Scalable Large Scene Neural View Synthesis
By Matthew Tancik et al.
❓ Why → Neural Radiance Fields (NeRFs) have raised dramatically in popularity since their introduction in ECCV 2020⁸. This is the next important step that shows how the technique can be applied also to large scenes.
💡 Key insights → NeRFs are a technique that parametrizes with a Neural Network the generation of novel views of a scene given a few examples (i.e. images). This technique had shown very promising photorealistic results in a wide range of scenes.
However, until now these successes were constrained to small scenes where a single model could generate all views. Block-NeRF — the approach proposed by this work — is a variant of the NeRF that allows for splitting scenes into smaller blocks that can be trained independently and later merged to generate scene views from arbitrarily large environments such as a city.
In this case, a few videos will be worth more than a thousand words, so knock yourself out with their impressive demo!

9. Compute Trends Across Three Eras of Machine Learning
By Jaime Sevilla et al.
❓ Why → Is MLprogress too fast for Moore’s law to handle? Lately, yes.
💡 Key insights → This paper provides a historical overview of ML progress through the lens of training compute, identifying 3 separate eras: pre-Deep Learning, Deep Learning, and large-scale era (see figure below). This analysis is based on identifying 123 milestone ML systems annotated with how much compute was required to train them.
The TL;DR of each era is just how steep the exponential increase in compute requirement is:
- Pre Deep Learning: training compute doubles roughly every 21 months.
- Deep Learning: training compute doubles roughly every 6 months.
- Large Scale era: training compute doubles roughly every 10 months, though starting from a substantially higher compute requirements in comparison to preceding models with AlphaGo in 2016.
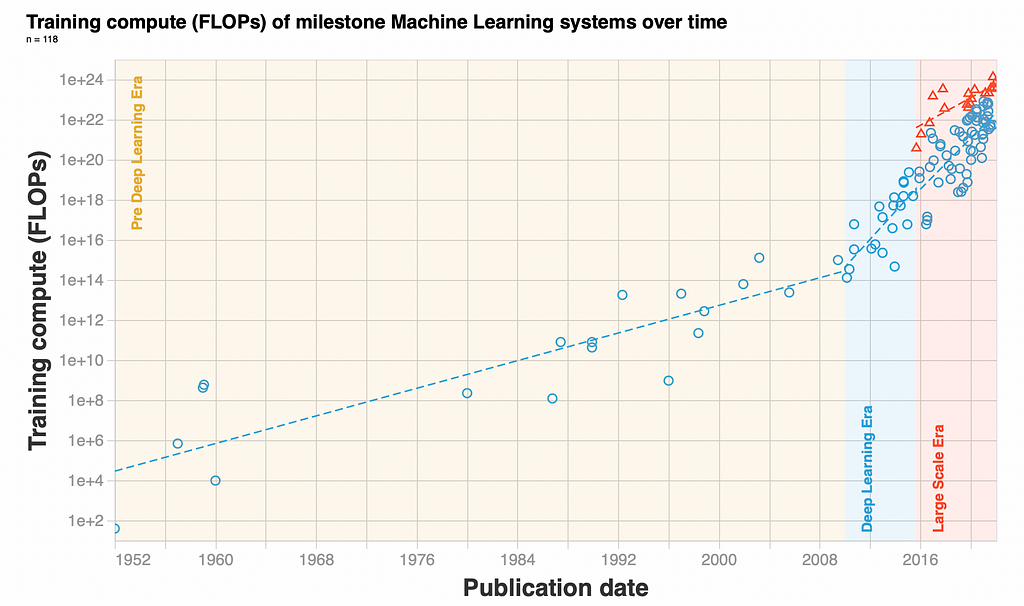
While these categories are arbitrary to a certain degree, they are still interesting to project how compute availability will shape ML advances in the upcoming years: now that AI is scaling faster than the silicon running it, plain GPUs don’t cut it as they used to 10 years ago and large scale distributed processing, supercomputers, and more specialized AI accelerators are becoming the key drivers — and limiters !— of progress.
10. Learning Discrete Representations via Constrained Clustering for Effective and Efficient Dense Retrieval
By Jingtao Zhan, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang Shaoping Ma.
❓ Why → Best paper award at WSDM (Information Retrieval) conference.
💡 Key insights → One of the key limitations of Dense Retrieval is that in order to perform embeddings fast nearest neighbor search, one needs to keep these embeddings in RAM. This can get costly quickly: for instance, only 1 million embeddings of a thousand dimensions of 32-bit floats will require around 4GB, so going one or two orders of magnitude beyond this — which is not unimaginable — might require either massive memory on servers or sharding indexes which can also introduce unnecessary complexity and costs.
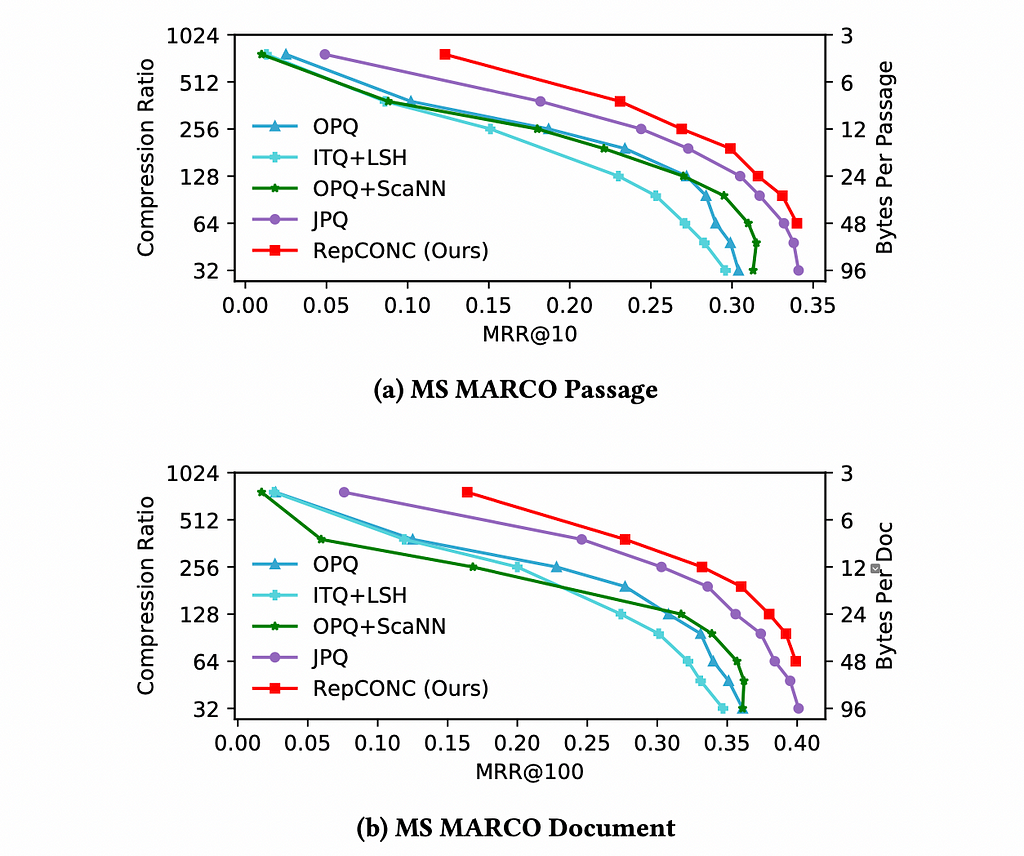
This paper proposes a novel quantization mechanism for document embeddings based on differentiable constrained clustering that enables a high compression ratio without sacrificing performance. As seen in the figure below, their quantization method (RepCONC) is Pareto-dominant to existing methods across all compression ratios.
Our monthly selection ends here; if you want to keep up to date with the latest research join our upcoming webinar on Friday March 4th, 2022, watch the previous editions on our YouTube channel and follow us on Twitter @zetavector and stay tuned for the next one!
References:
[1] “Efficiently Modeling Long Sequences with Structured State Spaces” by Albert Gu, Karan Goel and Christopher Ré, 2020.
[2] “DiffWave: A Versatile Diffusion Model for Audio Synthesis” by Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao and Bryan Catanzaro, 2020.
[3] “Multimodal Few-Shot Learning with Frozen Language Models” by Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals and Felix Hill, 2021.
[5] “Backpropagation and the brain” by Timothy P. Lillicrap, Adam Santoro, Luke Marris, Colin J. Akerman and Geoffrey Hinton, 2020.
[6] “Autoregressive Entity Retrieval” by Nicola De Cao, Gautier Izacard, Sebastian Riedel and Fabio Petroni, 2021.
[7] “Natural Questions: a Benchmark for Question Answering Research” by Tom Kwiatkowski et al. 2019.
[8] “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis” by Ben Mildenhall et al. 2020
Trends in AI—March 2022 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

