



NLP- Natural Language Processing
Last Updated on January 6, 2023 by Editorial Team
Last Updated on February 6, 2021 by Editorial Team
Author(s): Buse Yaren Tekin
Natural Language Processing
Hello everyone, in this article, I’ll talk about a concept that has taken place in our lives with the development of linguistics and artificial neural networks. NLP is that machines make sense by understanding and deriving human language. Machines are known as NP-Hard problems that are common in optimization problems as they do not know how to translate specifically during translation. Just like the work of many translation programs, it understands the word and makes an estimation in a way by analyzing elements such as subject, adjective, and predicate in terms of grammar.
🧷 There are a few features I should mention, of course. In the early days of NLP in our lives, the working logic was based on rule-based methods. However, in natural language processing, it is not always enough to work with rules. For example, there is a difference in meaning between the word come and the word I am coming. Unfortunately, in some additive languages, rule-based work is not enough. In order to eliminate this problem, the sentence must be broken down to the smallest building block and analyzed. And by making probability estimation between words, the meaning integrity between the words is provided.

🧷 In Computational Linguistics, it contains all the grammar rules in the language, and the language is formalized and expressed with mathematical models. The NLTK library that I am using below includes many models and rules. To give you a few small examples to better understand NLP, smart assistants (Google Assistant, Siri, Cortana, etc.) are the best examples of these. For example, the “Did you mean?” Section, which returns you as feedback in your missing searches on search engines, is one of the good examples of natural language processing. In this area, the search engine looks at the meaning relation of the words by using the n-gram method by separating the whole sentence in the search you are doing. Accordingly, it successfully returns the misspelled word to the user.
🔺 Let’s examine the layers together if you wish to better analyze NLP. As you know, language is fed from two sources, voice and text. Software that examines text data usually works in the field of OCR / Tokenization. However, in some cases, the text perception is insufficient (need for emphasis, etc.). The science that studies sound is called phonetics (sound science).
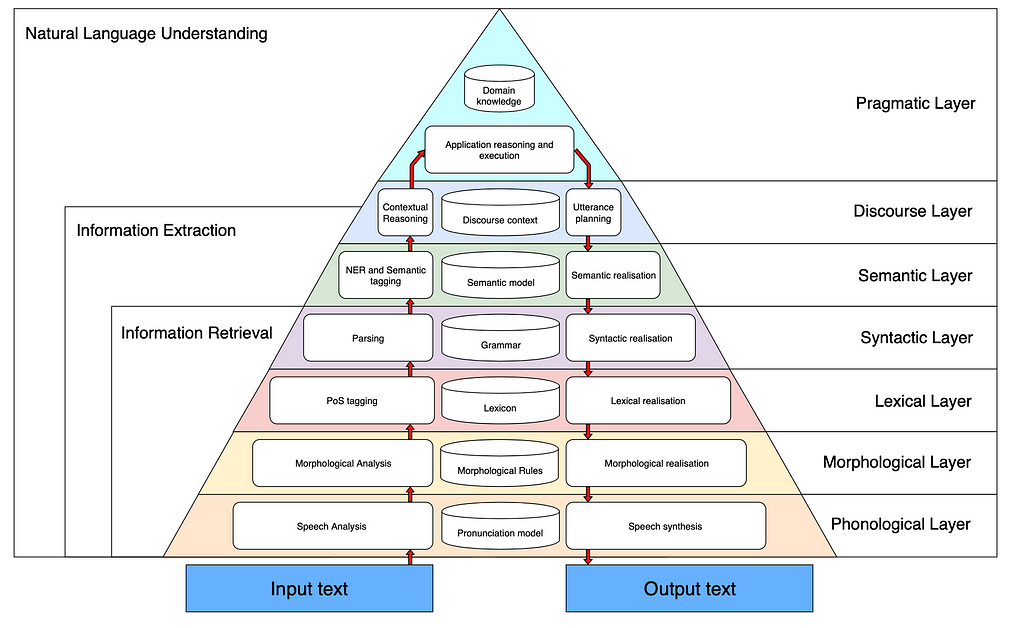
🔺 Looking at the layers, Morphology, which is called the 2nd layer, is a layer that NLP works on very often. In the layer called morphology, the meaning is inferred by making the separation of suffix and root on words. Regular Expressions (Regular Expressions), which are frequently encountered in Automata Theory, are widely used in Morphology.
🔺 In the third layer, the Syntax (Word Segmentation) layer, where the words occur in the sentence is determined, and the word meanings can change according to this analysis. In other words, the sentence structure is made meaningful with the analysis. At this stage, we can think of Syntax errors of any programming language. Each language has a unique Syntax structure. For example, in the C programming language; Syntax error occurs even when not used. Here, too, each language’s own working rules on natural language processing come to the fore. In some high-level languages, this situation can even give the error during coding without waiting for an operation.

🔺 There is a word-based meaning inference in the Semantic layer, which is 4 layers. As it is known from Semantic UI, Semantic word meaning is expressed as Semantic Analysis. It analyzes morphologically by separating the extracted elements one by one. The relations of these concepts with each other are examined. Pragmatic and Discourse concepts in other layers are completely dependent on language usage. For example, the concept of Discourse expresses the context in which the word is used. Let’s consider a ball. When the sentence is read, we can deduce whether this ball is a basketball or a volleyball. This is called discourse.
I’ll work on Python, a programming language cut out for data science and artificial intelligence. Those who wish can view the natural language library NLTK.
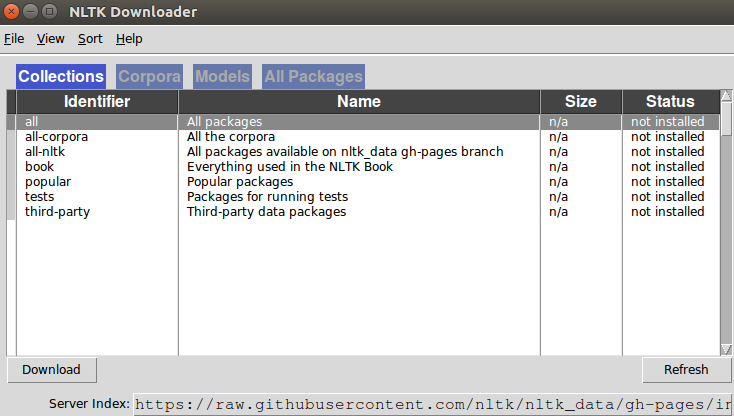
🧷 As you can see in the figure above, we have installed the NLTK library, which is the Natural Language Toolkit, and enabled the NLTK Graphic Interface to be printed on the screen. You can have all the libraries we will use through this interface.
Word and Sentence Tokenizer🕵🏻♀️
Among the downloaded libraries are functions that we can separate words and sentences one by one. In the Python console, we separate the words as follows.

I showed you a little NLTK analysis to make sure that what’s being said is better in mind. There are many packages that you can download with the NLTK Graphical Interface, and you can download it on demand and work on natural language processing. I wish everyone good coding. ✨
References
2. Yudhanjaya Wijeratne, Nisansa de Silva, Yashothara Shanmugarajah, Natural Language Processing for Government: Problems and Potential, April 2009.
4. https://www.blumeglobal.com/learning/natural-language-processing/
5. From Wikipedia, Free Encyclopedia, https://en.wikipedia.org/wiki/Natural_language_processing
NLP- Natural Language Processing was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


