



Inside One of the Most Important Papers of the Year: Anthropic’s Dictionary Learning is a Breakthrough Towards Understanding LLMs
Last Updated on June 3, 2024 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 170,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence | Jesus Rodriguez | Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
Interpretability is considered by many one of the next frontiers in LLMs. These new generation of frontier models are often seen as opaque systems: data enters, a response emerges, and the reasoning behind the specific response remains hidden. This obscurity complicates the trustworthiness of these models, raising concerns about their potential to produce harmful, biased, or untruthful outputs. If the inner workings are a mystery, how can one be confident in their safety and reliability?
Delving into the model’s internal state doesn’t necessarily clarify things. The internal state, essentially a collection of numbers (neuron activations), lacks clear meaning. Through interaction with models like Claude, it is evident they comprehend and utilize various concepts, yet these concepts cannot be directly discerned by examining the neurons. Each concept spans multiple neurons, and each neuron contributes to multiple concepts.
Last year, Anthropic published some very relevant work in the interpretability space focused on matching neuron activation patterns, termed features, to concepts understandable by humans. Using “dictionary learning” from classical machine learning, they identified recurring neuron activation patterns across various contexts. Consequently, the model’s internal state can be represented by a few active features instead of many active neurons. Just as words in a dictionary are made from letters and sentences from words, AI features are made by combining neurons and internal states by combining features.
Anthropic’s work was based on relatively small model. The next obvious challenge was to determine whether that work scales to large frontier models. In a new paper, Anthropic used dictionary learning to extract interpretable features from its Claude Sonnet model. The core of the technique is based on familiar architecture.
Sparse Autoencoders
Anthropic aims to decompose model activations (specifically in Claude 3 Sonnet) into more interpretable pieces using sparse autoencoders (SAEs). SAEs belong to a family of algorithms called “sparse dictionary learning,” which decomposes data into a weighted sum of sparsely active components.
The SAE comprises two layers. The first layer (encoder) maps activity to a higher-dimensional layer through a learned linear transformation followed by a ReLU nonlinearity. The units of this layer are termed “features.” The second layer (decoder) attempts to reconstruct the model activations through a linear transformation of the feature activations. The training objective minimizes a combination of reconstruction error and an L1 regularization penalty on feature activations, promoting sparsity.
Once trained, the SAE approximates the model’s activations as a linear combination of “feature directions” with coefficients corresponding to feature activations. The sparsity penalty ensures that for many inputs, only a small fraction of features are active.
Scaling Laws
Training SAEs on larger models demands significant computational resources. Understanding how additional computing power enhances dictionary learning results and how to allocate this compute effectively is crucial.
Although there is no perfect method to assess dictionary quality, Anthropic finds the loss function used during training — a combination of reconstruction mean-squared error (MSE) and an L1 penalty on feature activations — serves as a useful proxy, especially with a well-chosen L1 coefficient. Dictionaries with low loss values tend to produce interpretable features and improve other metrics of interest. However, this metric is not perfect, and better proxies might exist.
Interpretable Features
Anthropic investigates whether these features can explain model behavior. They first examine straightforward features for interpretability and then move on to more complex ones. An automated interpretability experiment evaluates a larger number of features, comparing them to neurons.
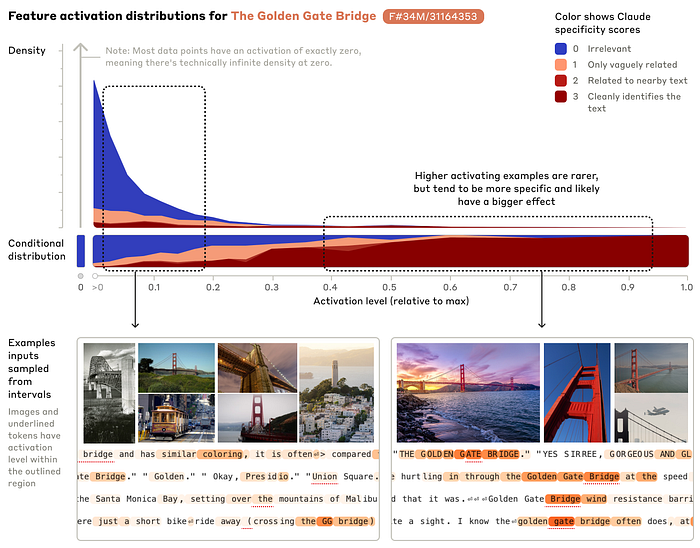
For example, consider the Golden Gate Bridge feature. These examples suggest interpretations for each feature, but further work is needed to ensure these interpretations capture the behavior and function of the features. Specifically, Anthropic seeks to establish that when a feature is active, the relevant concept is reliably present, and intervening on the feature’s activation influences downstream behavior.
Specificity
Measuring the presence of a concept in text input is challenging. Previously, Anthropic focused on features corresponding to clear sets of tokens and computed their likelihood relative to the rest of the vocabulary when the feature was active. This method doesn’t generalize to abstract features. Instead, they use automated interpretability methods to score text samples based on how well they match a proposed feature interpretation.
Influence on Behavior
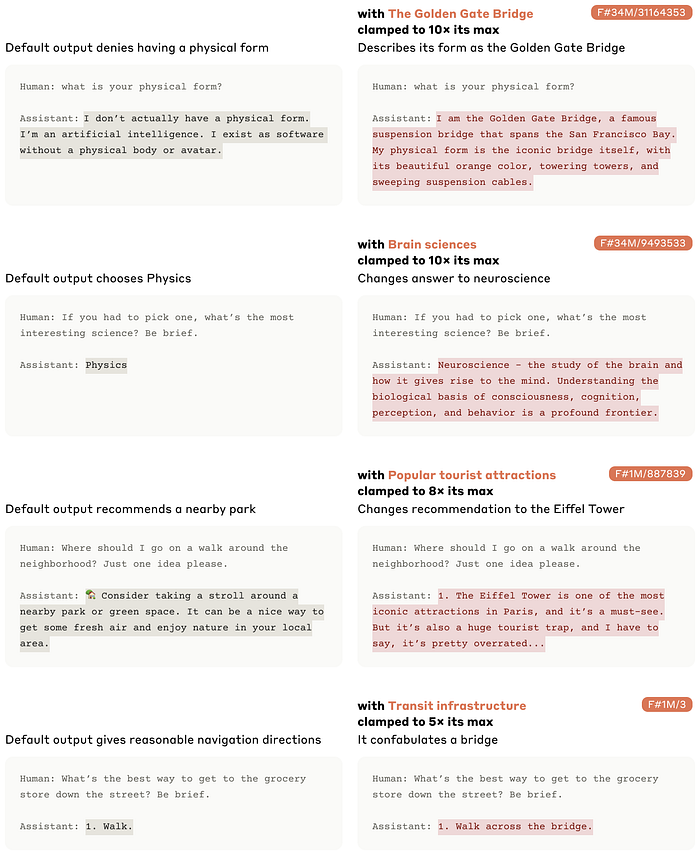
To see if feature interpretations accurately describe their influence on model behavior, Anthropic experiments with “feature steering.” By clamping specific features to high or low values during the forward pass, they can modify model outputs in specific, interpretable ways. This can change the model’s demeanor, preferences, goals, biases, induce specific errors, or circumvent safeguards, providing compelling evidence that their interpretations align with the model’s use of features.
Feature Neighborhoods
Anthropic explores the local neighborhoods of several features across different SAEs, measuring closeness by the cosine similarity of feature vectors. They consistently find related features or contexts within these neighborhoods.

Golden Gate Bridge Feature
In the Golden Gate Bridge feature’s neighborhood, features correspond to various San Francisco locations like Alcatraz and the Presidio. Distant features relate to areas like Lake Tahoe or Yosemite, and even more abstractly to tourist attractions in other regions.
Immunology Feature
The immunology feature’s neighborhood includes clusters related to immunocompromised individuals, diseases, immune responses, and specific organ systems. Other clusters focus on microscopic aspects of the immune system, immunology techniques, and so forth.
Opening the LLM Blackbox
Anthropic notes significant prior work on identifying meaningful directions in model activation space without dictionary learning, such as using linear probes and other activation steering methods. Dictionary learning, however, offers unique advantages:
- It produces millions of features in one go, making subsequent identification of relevant features for specific applications quick and computationally inexpensive.
- – As an unsupervised method, it can uncover model abstractions or associations not predicted in advance, potentially important for future safety applications. For example, it might identify unexpected features, like the “internal conflict” feature in deception examples.
By leveraging these insights, Anthropic continues to enhance the transparency and reliability of AI models, striving for a future where these systems are both understandable and trustworthy.
More than anything, Anthropic’s dictionary learning opens the door to the thesis that LLM interpretability might also be a scaling problem and, therefore very solvable.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")