



Inside LlaVA: The First Open Source GPT-4V Alternative
Last Updated on November 5, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
A few weeks ago, OpenAI unveiled new image and audio processing capabilities in GPT-4. Fundamentally, the AI lab announced a new model known as GPT-4 Vision(GPT-4V), which allows users to instruct GPT-4 on image and audio inputs. GPT-4V is an interesting development in the multimodal foundation model space. A few days after the GPT-4V announcements, we already had the first open-source alternative. Researchers from the University of Wisconsin-Madison and Microsoft Research introduced Large Language and Vision Assistant (LLaVA), a LLaMA-based multimodal LLM that can process image and audio data as input.
LLaVA is an end-to-end trained marvel that seamlessly bridges the gap between a vision encoder and LLM (Large Language Model) to provide comprehensive visual and language understanding. The early experiments with LLaVA have unveiled its remarkable prowess in multimodal chat interactions, occasionally exhibiting behaviors akin to those of the highly anticipated Multimodal GPT-4, even when presented with previously unseen images and instructions.
One groundbreaking stride taken in this endeavor is the exploration of visual instruction-tuning. This marks the pioneering effort to extend the concept of instruction-tuning into the realm of multimodal AI, thereby laying the foundation for the development of a versatile, general-purpose visual assistant. The paper accompanying LLaVA’s unveiling contributes significantly to this domain in the following ways:
· Multimodal Instruction-Following Data: A pivotal challenge faced in this journey is the scarcity of vision-language instruction-following data. To address this, a novel data reformation approach and pipeline have been devised. This technique effectively transforms image-text pairs into the requisite instruction-following format, leveraging the power of ChatGPT/GPT-4.
· Large Multimodal Models: LLaVA has been brought to life through the creation of a Large Multimodal Model (LMM). This feat was accomplished by uniting the open-set visual encoder from CLIP with the language decoder known as LLaMA. These components were then fine-tuned in unison using the instructional vision-language data generated during the project. Extensive empirical research has validated the efficacy of employing generated data for LMM instruction-tuning, offering practical insights into the development of a versatile, instruction-following visual agent. Notably, with GPT-4, LLaVA has achieved state-of-the-art performance on the Science QA multimodal reasoning dataset.
· Open-Source Initiative: In the spirit of collaboration and knowledge sharing, the team behind LLaVA is proud to release several valuable assets to the public.
Arguably, the biggest contribution of LLaVA is the way is leverages GPT-4 to generate an instruction-tuned dataset.
Generating Visual Instruction Data Using GPT-4
In the realm of multimodal data, the community has witnessed a significant influx of publicly available resources, encompassing a wide spectrum of image-text pairs from CC to LAION. However, when it comes to the realm of multimodal instruction-following data, the available pool remains limited. This scarcity is, in part, due to the laborious and somewhat nebulous process involved, particularly when relying on human crowd-sourcing. Drawing inspiration from the remarkable success of recent GPT models in text-annotation tasks, the proposal emerges: Let’s harness the power of ChatGPT/GPT-4 for the collection of multimodal instruction-following data, building upon the wealth of existing image-pair data.
Consider an image, Xv, and its corresponding caption, Xc. It naturally lends itself to the creation of a set of questions, Xq, aimed at instructing an AI assistant to describe the image’s content. Initiating GPT-4, we curate a list of such questions, as showcased in Table 8 within the Appendix. Thus, a straightforward approach to expand an image-text pair into its instruction-following counterpart takes shape: Human poses Xq Xv<STOP>nn, while Assistant responds with Xc<STOP>nn. Though cost-effective, this straightforward expansion method is somewhat limited in diversity and depth, both in the instructions and the resulting responses.
To address this limitation, the approach shifts to leverage language-focused GPT-4 or ChatGPT as formidable teachers. These models, accepting text as input, step in to craft instruction-following data that incorporates visual content. The methodology is clear: in order to translate an image into its visual features for prompting a text-only GPT, symbolic representations come into play. These representations fall into two categories:
· Captions: These serve as textual descriptions that offer diverse perspectives on the visual scene.
· Bounding Boxes: These handy boxes serve to pinpoint and delineate objects within the scene. Each box encodes not only the object concept but also its spatial location.
· With this innovative approach, the endeavor to expand multimodal instruction-following data is poised to unlock new dimensions of diversity and depth, bridging the gap between visual content and textual instructions. Stay tuned as GPT-4 continues to revolutionize the landscape of multimodal AI.

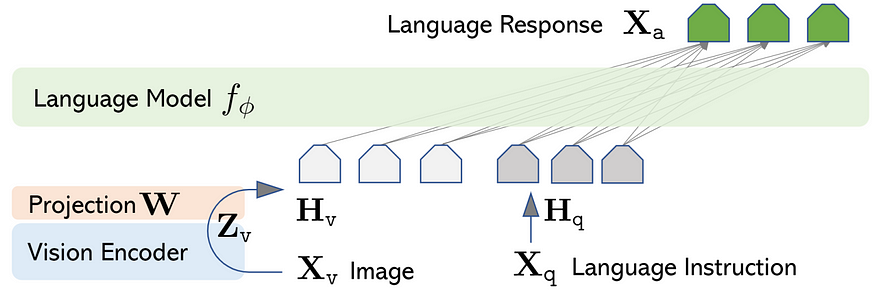
LLaVA Architecture
LLaVA seamlessly connects the pre-trained CLIP ViT-L/14 visual encoder with the powerful large language model, Vicuna, through a straightforward projection matrix. The journey towards its remarkable capabilities unfolds in a two-stage instruction-tuning process:
Stage 1: Pre-training for Feature Alignment
In this initial stage, the focus lies on updating only the projection matrix. This update is grounded in a subset of CC3M data, setting the stage for further advancements.
Stage 2: Fine-tuning End-to-End
Here, the momentum builds as both the projection matrix and LLM undergo updates, catering to two distinct usage scenarios:
· Visual Chat: LLaVa undergoes fine-tuning using our meticulously crafted multimodal instruction-following data, designed to cater to the everyday needs of users.
· Science QA: LLaVa embarks on a journey of fine-tuning using a multimodal reasoning dataset tailored for the intricate domain of science.
The concept of instruction-tuning large language models (LLMs) using machine-generated instruction-following data has undoubtedly elevated zero-shot capabilities in the language domain. However, its application in the realm of multimodal AI remains relatively uncharted territory.
Initial Results
Initial evaluations of LLaVA show incredible results when compared to GPT-4.

The early chapters of LLaVa’s story are nothing short of remarkable. These experiments reveal LLaVa’s impressive chat abilities, at times mirroring the behaviors of multimodal GPT-4 when faced with unseen images and instructions. It boasts an impressive 85.1% relative score compared to GPT-4 on a synthetic multimodal instruction-following dataset. Moreover, when LLaVa and GPT-4 join forces after fine-tuning on Science QA, they achieve an unprecedented state-of-the-art accuracy, reaching an astounding 92.53%.

LLaVA represents one of the most exciting developments in the world of multimodal LLMs and is an important step for the open-source foundation model movement.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

