



Data-Centric AI with Snorkel AI: The Enterprise AI Platform
Last Updated on October 16, 2021 by Editorial Team
Data-centric AI enterprise platform showcase: Snorkel Flow by Snorkel AI
Author(s): Towards AI Team
However, recent progress in AI has confirmed this belief to be false — instead, building a “good enough” starting point for a model has allowed practitioners to make a significant amount of further training, validation, and accuracy improvement while also enabling deeper insights into the essence of the data being used.
AI organizations and enterprises are beginning to transform and focus their efforts toward a more data-centric AI approach, in contrast to a model-centric approach as they start to realize that a data-centric approach (also referred to as Software 2.0) to ML pipelines is crucial for increasing accuracy and rapid AI application development.
The AI landscape is switching from being model-centric toward data-centric AI, and while there are some cool ways to approach it, the folks at Snorkel AI are going all-hands with Snorkel Flow, the first truly data-centric AI platform, with roots in state-of-the-art data programming and weak supervision approaches that aim to tackle the vast challenge of diverting current AI practices toward more robust data-centric approaches and end the time-wasting modelitis.
In this short read, we will talk about Snorkel AI. The inventors behind the data-centric AI approach:

About Snorkel AI
Snorkel AI started as a research project in the Stanford AI Lab in 2015. Initially set out to explore a higher-level interface to machine learning through training data. Snorkel AI has over 50 peer-reviewed publications, published at ICML, Nature, ICLR, IEEE, NeurIPS, and many more, powering the core technology behind Snorkel Flow. In addition, Snorkel’s technology has been developed and deployed at Google, Intel, Apple, two of the three top US banks, the US Department of Justice, and other leading organizations.

Snorkel Flow, the First Data-Centric AI Platform
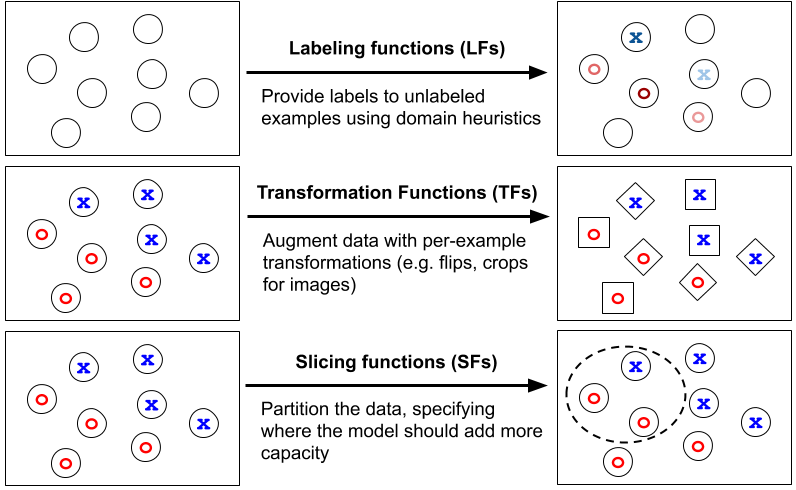
Snorkel Flow is an AI development platform powered by weak supervision [2], and programmatic data labeling [3] approaches. Using Snorkel Flow, data science teams can collaborate with subject matter experts to rapidly build highly accurate AI applications. In addition, it allows users to create and manage massive amounts of training data, train models, analyze, improve performance by iterating on not just models but also training data and deploy — all in one platform.

Where Does Snorkel Flow Excel At?
- Label and build training data programmatically in hours instead of months or even years of hand-labeling.
- Integrate and manage programmatic training data from all sources, including data cleansing and data slicing.
- Train and deploy state-of-the-art machine learning models in-platform or via a Python SDK.
- Analyze and monitor model performance to rapidly identify and correct error modes in the data fast.
Learn more about the Snorkel Flow platform.

SuperGLUE Case Study
Using standard models (i.e., pre-trained BERT) and minimal tuning, the Snorkel AI team was able to leverage critical abstractions for programmatically build and manage training data to achieve a state-of-the-art result on SuperGLUE — a newly curated benchmark; with six tasks for evaluating “general-purpose language understanding technologies.
A new SOTA was achieved using programming abstractions on the SuperGLUE Benchmark and four of its components tasks. SuperGLUE is similar to GLUE but contains “more difficult tasks, which are chosen to maximize difficulty and diversity. These tasks are selected to show a substantial headroom gap between a strong BERT-based baseline and human performance.”
After reproducing the BERT++ baselines, we minimally tune these models (baseline models, default learning rate, and so on.) and find that with applications of the above programming abstractions, we notice improvements of +4.0 points on the SuperGLUE benchmark (indicating a 21% reduction of the gap to human performance).
The paper [5] also gives updates on Snorkel’s industry use cases with even more applications at scale, for example, Google in Snorkel Drybell to scientific work in MRI classification and automated Genome-wide association study (GWAS) curation, both accepted in Nature Comms.
Industrial Case Studies
- Google has used Snorkel to replace 100k+ hand-annotated labels in critical machine learning pipelines.
- A top US bank uses Snorkel Flow to quickly build AI applications that classify and extract information from their documents.
- Apple built applications with an internal Snorkel-based system that answered billions of queries in multiple languages and processed trillions of records with up to 2.9x fewer errors.
- A Fortune 500 Biotech pioneer leveraged Snorkel Flow to extract critical chronic disease data from clinical trials, accurately processing 300K documents in minutes.
References
[1] “Snorkel: Rapid Training Data Creation with Weak Supervision.” Alex Ratner, Stephen H. Bach, Henry Ehrenberg, Jason Fries, Sen Wu, Chris Re, Stanford University, https://arxiv.org/pdf/1711.10160.pdf
[2] “Weak Supervision: A New Programming Paradigm For Machine Learning.” Alex Ratner, Paroma Varma, Braden Hancock, Chris Ré, et al., SAIL Blog, 2019, https://ai.stanford.edu/blog/weak-supervision/
[3] “Interactive Programmatic Labeling for Weak Supervision.” Benjamin Cohen-Wang, Stephen Mussmann, Alex Ratner, Chris Ré, KDD, 2019, https://bencw99.github.io/files/kdd2019_dcclworkshop.pdf
[4] “Snorkel DryBell: A Case Study in Deploying Weak Supervision at Industrial Scale.” Stephen H. Bach, Daniel Rodriguez, Yintao Liu, Chong Luo, Haidong Shao, Cassandra Xia, Souvik Sen, Alexander Ratner, Braden Hancock, Houman Alborzi, Rahul Kuchhal, Christopher Ré, Rob Malkin, SIGMOD, 2019, https://arxiv.org/abs/1812.00417
[5] Wang, Alex, et al. “SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems.” 2019. SuperGLUE consists of 6 datasets: the Commitment Bank (CB, De Marneffe, et al., 2019), Choice Of Plausible Alternatives (COPA, Roemmele, et al., 2011), the Multi-Sentence Reading Comprehension dataset (MultiRC, Khashabi, et al., 2018), Recognizing Textual Entailment (merged from RTE1, Dagan et al. 2006, RTE2, Bar Haim, et al., 2006, RTE3, Giampiccolo, et al., 2007, and RTE5, Bentivogli, et al., 2009), Word in Context (WiC, Pilehvar, and Camacho-Collados, 2019), and the Winograd Schema Challenge (WSC, Levesque, et al., 2012).
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



