


")
Digital Artist: Creative Adversarial Networks(CAN)
Last Updated on March 8, 2021 by Editorial Team
Author(s): Daksh Trehan
Computer Vision, Deep Learning
An interesting approach to make AI better at the art of “faking”!
Artificial Intelligence has surely stormed mankind in past years, the machines are extremely good at imitating what we tell them to do. But AI and creativity are counterparts, creativity is the abstract concept that is still missing from the core AI field.
For the past few years, researchers have been trying to decode the machine’s ability to mimic human-level intelligence to generate creative products such as jokes, poetry, problems, paintings, music, etc. The integral aim is to show that AI algorithms are in-fact intelligent enough to produce art without involving human artists but taking into account the human creative products in the learning process.
Several interesting algorithms like GANs(Generative Adversarial Networks) have been introduced to explore the creative space. GANs took the AI field by storm last year by generating human-like fake faces. It implements implicit techniques, that is, it learns with no data being passed to the network.
GANs constitute two networks i.e. Discriminator and Generator. The goal of the generator is to generate “fake” images and the discriminator tries to bust “fake” images developed by the Generator with the help of provided training data. The generator generates random images and asks for the feedback of the discriminator i.e. whether the discriminator finds it real or fake. At composure, the discriminator won’t be able to differentiate between randomly generated images and actual images in the training, and the goal of the generator is accomplished. Both Generator and Discriminator are independent of each other yet the iterative process helps both Discriminator and Generator to constantly learn from each other’s shortcomings to generate even better images.
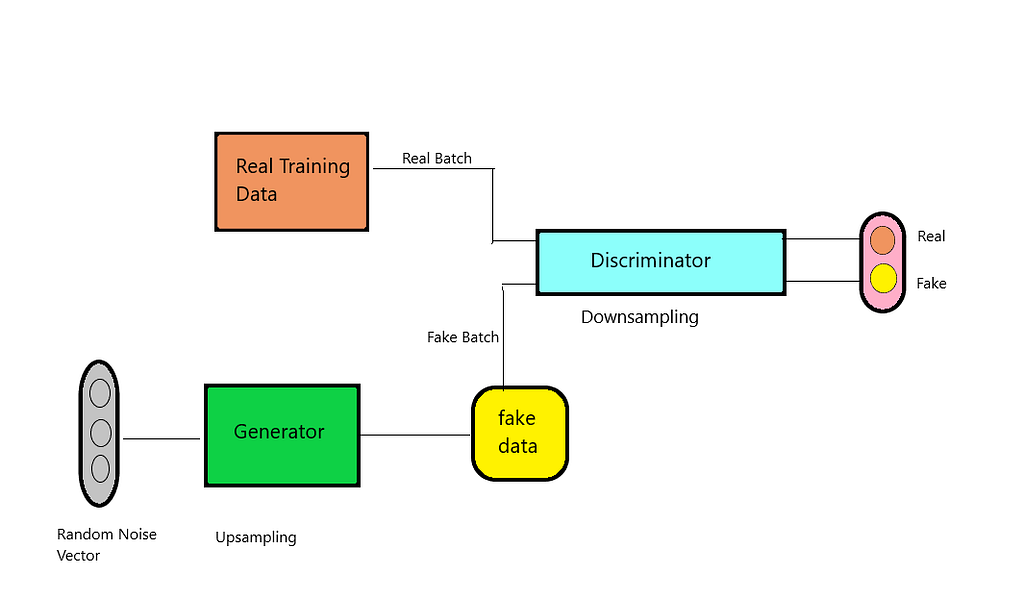
Let us infer that we are training our GAN on images of the painting. The motive of the generator is to generate images from training distribution so the discriminator can label them as “real”. Ultimately, the generator will start simulating existing art and the discriminator will be fooled right away, the model is generating the new images but the images are far from being called novel or creative. Thus, it can be concluded that GANs ability to generate creative ideas in their original design is limited.
The secret ingredient to developing an algorithm that can think creatively is to link their creative process to human art development throughout time. In simple words, we are trying to mimic exactly how humans develop art. Humans, throughout their lives, are exposed to the various art form and that’s where they get an impression for their new art, that’s the exact workflow we want our model to follow.
Experience and Create.
Principle of “Least Efforts”
CANs are derived from GANs and are based on Martindale’s principle, where he argued that the arts are made attractive by increasing their arousing potential that pushes it against its habituation. In simpler words, the art is perceived by viewers when they are presented with something exclusive yet associated with the historical pieces. But, the level of arousal must be controlled and not grow exponentially to gain a negative reaction.
The goal of the model is to satisfy “arousing potential” which refers to the levels of excitement in human beings. The level of arousal is least when a person is slept or relaxed and is highest when a person faces fury/danger/violence. Thus, too little arousing potential can be boring, and too much of it can activate the hostile situations. The situation can be best explained by the Wundt curve.
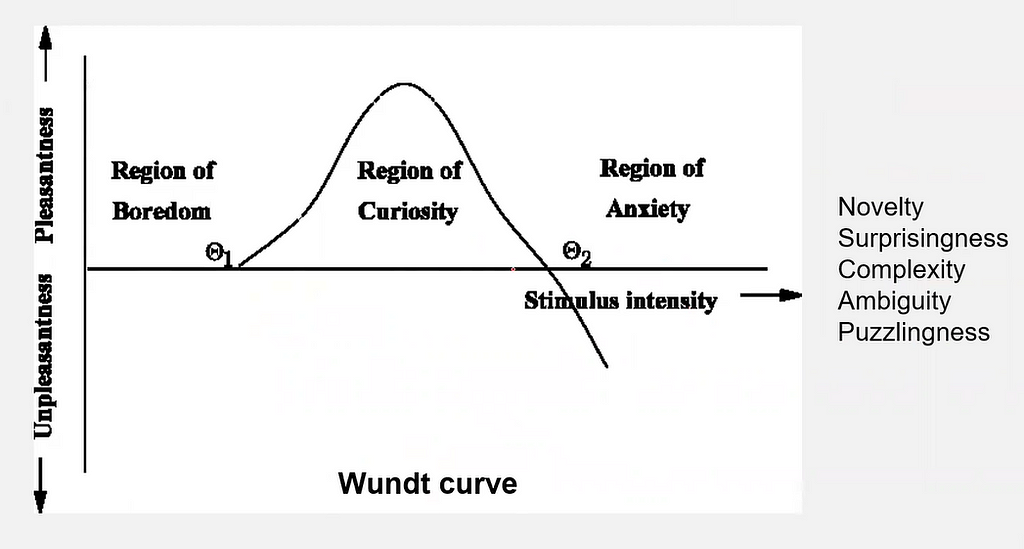
Besides, if an artist keeps on producing a similar sort of work then it automatically decreases the arousing potential and leads to the viewer’s distaste. This can be concluded that habituation builds a constant pressure to generate a higher level of arousing potential.
The model tries to boost the arousing potential by increasing the “stylistic ambiguity” and still avoiding moving too far away from what we accept as art. The architecture of CANs is inherited from GANs with a slightly averted workflow. The discriminator is provided with a large set of art that have been experienced over mankind with their associated style labels as Renaissance, Baroque, Impressionism, Expressionism, etc. The generator is provided with no training example similar to GANs but is designed to accept two signals from the discriminator.
The first signal depicts whether the discriminator classifies the generated image as “art or not art”. In the traditional GANs, this signal will make the generator change the weights and try again to fool the discriminator by making it believe that the art is coming from the same custom distribution. But in CANs, the discriminator is trained over a large dataset of art, it can accurately distinguish the generated image as “art or not art” and will only ask the generator to converge into images that are already been accept as “art”.
The second signal tells the level of accuracy of the discriminator to classify generated art into already defined classes. If the generator, can generate a piece of art that can be regarded as “art” and can also be easily distinguished by the discriminator into an already defined class then it has successfully fooled the discriminator by generating some art that can be included in so-called humans accepted art. The generator tries to fool the discriminator by making it think of the generate piece as an “art” and also confuses it about the styles of work that has been generated.
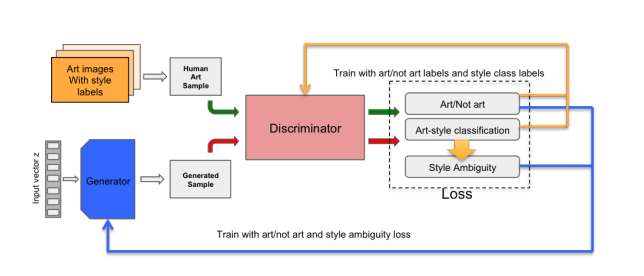
The two signals work opposite to each other, the first one pushes the generator to generate art that can be accepted as an “art” and if it succeeds it allows the discriminator to classify the images easily. However, the second signal will substantially penalize the generator for doing so, as the motive was to generate style-ambiguous art i.e. something that can’t be easily classified by discriminator but can still be regarded as “art”. Both signals work independently yet plays an essential role in perfecting each other just like in GAN.

Quantitative Validation

In the above table, the human viewers tried to rate four sets of artwork. The DCGAN is a standard GAN that mimics the established artwork closely but lacks creativity. The Abstract Expresionist dataset is a collection of art that was created between 1945 and 2007, whereas Art Basel 2016 constitutes images displayed in Art Basel 2016, a leading-edge art show.
Unsurprisingly, the images generated from CANs rank highest in arousal potential techniques i.e. Novelty, Surprising, Ambiguity, and Complexity. Also, they fooled the human viewers better into making them believe that the art was generated by humans.
References:
- CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms
- Creative Adversarial Network
- What are Creative Adversarial Networks (CANs)?
- CAN (Creative Adversarial Network) — Explained
- PR-122: CAN: Creative Adversarial Networks
- Creative Adversarial Networks for Art Generation with Ahmed Elgammal — TWiML Talk #265
- Creative Adversarial Networks (CAN) and artificial intelligence as artist
Feel free to connect:
Portfolio ~ https://www.dakshtrehan.com
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Are You Ready to Worship AI Gods?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3: AI overruling started?
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
Reinforcing the Science Behind Reinforcement Learning
Decoding science behind Generative Adversarial Networks
Understanding LSTM’s and GRU’s
Recurrent Neural Network for Dummies
Convolution Neural Network for Dummies
Cheers
Digital Artist: Creative Adversarial Networks(CAN) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


