



Dealing with Class Imbalance — Dummy Classifiers
Last Updated on January 6, 2023 by Editorial Team
Last Updated on August 1, 2020 by Editorial Team
Author(s): Abhijeet Sahoo
Data Science
Dealing with Class Imbalance — Dummy Classifiers
Let me paint a picture for you, you are a beginner to the field of Data Science and have started making your first ML model for predictions and found the accuracy using model.score() as 95%. You are jumping around thinking that you nailed it and maybe it was your destiny to become a Data Scientist. Well, I don’t want to burst the bubble but you can be horribly wrong. Do you know why? — Because accuracy is a very poor metric to measure the classifier performance especially in the case of Unbalanced Dataset. And unbalanced datasets are prevalent in a multitude of fields and sectors. From fraudulent transactions, identifying rare diseases, electrical pilferage to classifying search-relevant items in an e-commerce site, data scientists come across them in many contexts. The challenge appears when we have to make a machine learning model that can classify the very rare cases in the training dataset. Due to the disproportionality of classes in the variables, the conventional ML algorithm which doesn’t take into account the class disproportion or balances tends to classify into the class with more instances, the major class, while at the same time gives us a false notion of an extremely accurate model. Both the inability to predict rare events and the misleading accuracy can ruin the whole motive we are making the predictive models for.

Let me give you an example, suppose you develop a classifier for predicting fraudulent transactions. And after you’ve finished the development, you measure its accuracy on the test set to be 97%. At first, it might seem to be too good to be true, right?
Now let’s compare it to a dummy classifier that always just predicts the most likely class which would be the non-fraudulent transactions. That is regardless of what the actual instance is, the dummy classifier will always predict that a transaction is non-fraudulent. So let's assume we have testing data which contains 1,000 transaction details, and on average, about 999 of them will be non-fraudulent transactions. So our dummy classifier will correctly predict the non-fraudulent label for all of those 999 transactions. And so the accuracy of the dummy classifier will be 99.9%. So our own classifier’s performance isn’t great at all, as we thought and celebrated. It’s no better than just always guessing the majority class without even looking at the data.
Still not convinced huh! Then lets elaborate it by making a classifier with a real dataset. We shall be using the digits dataset, which contains the images of handwritten digits labeled from 0–9 (i.e. Ten classes).
First and foremost we shall import the necessary libraries and then the load_digits dataset. Now to check whether our dataset is balanced or not, we use the numpy’s bin count method to count the number of instances in each class.

As we can see, the number of instances in each class is more or less similar, hence it is a balanced dataset right !! But here to show you the application of a dummy classifier, we shall be converting this dataset into an imbalanced one. To do so we will be labeling all digits that are not the digit 1 as the negative class with label 0, and digits that are 1 as the positive class, label 1.

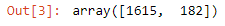
Now that we have assigned all 1’s as positive class and all the others as a negative class, when we use bincount, we can see that there are 1,615 negative examples, but only 182 positive examples. So indeed, we were successful to make an unbalanced dataset. Now as usual we first create a train test split on our imbalanced dataset. And then we have trained a support vector machine classifier with these binary labels with the radial basis function as a kernel.
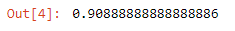
We got the accuracy using the .score() method, and we can see this is around 90%. Damn!!! 90% percent, This is more than enough. Let me give you a comparison, Google AI assistance that we use has an accuracy of 88% as per reports in 2019. So are we successful in making the best model for classification? For that, there should be some standard to measure it against, right! Especially when you have spent so many resources on a classifier…. Imagine you took all this pain to collect data, clean it, understand it, and then making a model, but at last, a friend of yours comes up and starts just guessing every label of a new data point as the majority class and has an accuracy similar to your model. Don’t you think it would very disappointing and embarrassing? Hence to save you from embarrassment, sci-kit learn has something called Dummy Classifiers which would simulate a system that would do this guessing on the basis of either max frequency or distribution, etc. I will come to that in a second. Lets first implement it for our digit classifier to see whether the 90% accuracy is actually impressive or not.
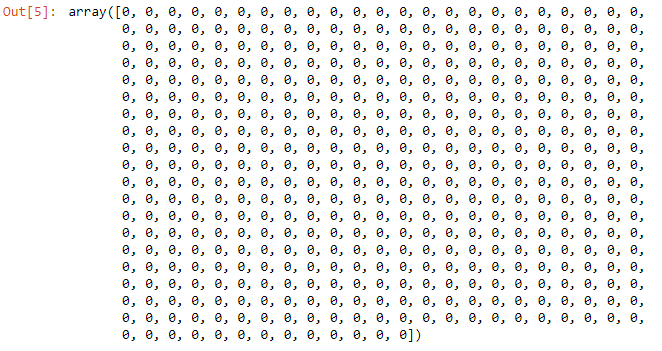
And as we have used the strategy of max frequency, you can see it’s always predicting 0 or the negative class (which has the max frequency) for every instance in the test set.
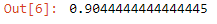
So we got an accuracy which is very slightly less than the SVC model. So we found out that our classifier has an accuracy very close to the dummy classifier, What does it represent though? It could be due to one of two reasons — One, the features we have used for the classifiers are quite random and ineffective or two — we have adopted a very poor choice of kernel or hyperparameters like C and sigma in SVM or k parameter in KNN model. For example, if I change the support vector classifier’s kernel parameter to linear from RBF. And then again compute the accuracy of the retrained model, we can see that this leads to a much better performance of almost 97.8% compared to the most frequently strategic DummyClassifier baseline of 90%.
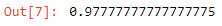
Here I just showed the “most frequent” strategy type of Dummy Classifier. Let me elaborate more on Dummy Classifier and its types.
Dummy Classifier
A dummy classifier is basically a classifier which doesn’t even look at the training data while classification, but follows just a rule of thumb or strategy that we instruct it to use while classifying. It is done by including the strategy we want in the strategy parameter of the DummyClassifier. In the above case, we used “most frequent”. At the end of the day, we use it as a baseline and expect our models to classify better than this baseline. It is based on an obvious notion that we want our classifier which is based on an analytic approach to do better than random guessing approach.
Types of Strategies that can be used
most_frequent: It always predicts the most frequent label. Example: As the example shown before, the Dummy classifier only predicts the negative class which was most frequent.
stratified: It predicts on the basis of the class distribution of the training dataset. For example, if the negative class occurs about 80% of the time in the training set, then the dummy classifier will output negative class with 80% probability.
uniform: It predicts classes uniformly at random. That is all the classes have the same chance to be output by the classifier rather than depending on the frequency of its occurrence in the training dataset.
constant: It predicts always the same class that is instructed by the user. It is useful for metrics to evaluate non-majority classes.
And hey! I know there are other metrics as well like AUC, F1-score, etc., which I shall discuss in another medium article, Stay Tuned. But I wanted to dedicate this article to DummyClassifier, as it is something that many of us may not know. I hope I was able to do justice to the topic.
References:
- https://scikitlearn.org/stable/modules/generated/sklearn.dummy.DummyClassifier.html
- https://www.coursera.org/learn/python-machine learning/home/welcome
— From someone who as a beginner did the same mistake of celebrating too early on getting an accuracy of 90+ 😅
Dealing with Class Imbalance — Dummy Classifiers was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

")
Recent Posts
")



")


