


Examples of Information Retrieval Application on Image and Text
Last Updated on July 26, 2023 by Editorial Team
Author(s): Haryo Akbarianto Wibowo
Originally published on Towards AI.
Information Retrieval in Image and Text use-case
Hello, welcome to my second blog post. In this post, I want to write what I shared when I got invited as a guest lecturer at the University of Indonesia for the Advanced Information Retrieval course. I shared several Information Retrieval implementation ideas that can be used in the real world.
I will write about high-level technical details here. So, I think this post is newbie-friendly, as long as you know the basics of information retrieval. Even though I mention NLP or Image above, I will describe them with intuition.
So, have fun reading my post :).
Introduction
Information Retrieval (IR) is a process of retrieving relevant resources from the collection of the resources itself. One of the popular and widely used Information Retrieval implementations is a search engine like Google, Bing, and DuckDuckGo. They receive a query from the user and return relevant documents according to the query itself.
IR’s algorithm mainly compares the query to the collection of sources with the scoring algorithm. The scoring algorithm is used to compute the relevance between the query and the document itself. The sorted retrieved document is returned to the user.
I will share some basic tools and the algorithm for information retrieval implementation with NLP and Image. They are “Automatic Order Extraction” and “Image Retrieval for Image Website.” I will also provide the background of the usefulness of each example.
Automatic Order Extraction
Automatic Order Extraction is a service to extract and parse incoming order messages automatically. For example, a clothes seller deploys this service to a messaging app (we can call it chatbot) and extract the information that the seller needs automatically. Then the extracted information is used to process the transaction. Look below for the example:
[BUYER]:
Hi, here is my order:
Name: **Si Meong** <NAME>
Address: **Meow Meow Street** <ADDRESS>
Order:
**1** <Product Quantity> **T-Shirt Meow** <Product Name>
Thank you!
Regards,
Customer
**is the extracted information and< >is the tag of the extracted information
Why is this implementation important?
Imagine you have a big store that allows ordering a product by using messaging apps. In a day, you have 2000 orders from the customers. We need to see the data, and the product order, process them and validate them. Yeah, it will be a hassle to do all of them manually, with large requests. So that’s why we need a way to automate it.
How and What to do to implement it?
One of the usual easy and common practices to automate it is by using a template. For example:
Name: <NAME>
Address: <ADDRESS>
Order:<Product Quantity> <Product Name>
It can be easily implemented by using a Regular Expression (Regex) technique. Sadly, there are some weaknesses in using it:
- Rigid, the user should put its message according to the template. Typo or any additional information will make the service cannot extract the information.
- Typo on the product name will make the product undetected and cannot be extracted.
This is where Natural Language Processing (NLP), especially by using a Named Entity Extraction (NER) system can solve the first problem. The second problem can be solved by using an Information Retrieval system. First, we extract the entities that we want to extract plus the product name and quantity. To solve the typo problem, we use Information Retrieval techniques to recommend similar products if the user do a typo.
End Implementation
Usually, the service is deployed behind the Back-end service like below:

Here, we will focus only on the AI service and return the extracted information.
For the AI services, it looks like this:

Below is the example of the input of the service.
[BUYER]:
Hi, here is my order:
Name: **Si Meong** <NAME>
Address: **Meow Meow Street** <ADDRESS>
Order:
**1** <Product Quantity> **T-Shirt Meow** <Product Name>
**4** <Product Quantity> **Shoet Moew** <Product Name>
Thank you!
Regards,
Customer
We assume Shoet Moew is not in the product list and similar products are Shirt Moew and Short Moew.
Passed information (in JSON)
{
"name": "Si Meong",
"address": "Meow Meow Street",
"order": [
{
"qty": 1,
"product_name": "t_shirt_meow"
}
],
"suggest": [
{
"query": "Shoet Moew",
"qty": 4,
"suggest": ["shirt_moew", "short_moew"]
}
]
}
First, we will go into the NER detail.
Named Entity Recognition (NER)
The description of NER can be seen below.
“Named entity recognition (NER) is the task of tagging entities in text with their corresponding type.” — paperswithcode.com
The output of the NER has extracted entity that we want. for example:
- Name
- Address
- Bank
- Note
- Product Name
- Product Quantities
- Phone Number
In the above example, we only extract name, address, product quantity, and name.
Training NER: Data
To make a NER system, we either use an off-the-shelf service (often not suitable for your needs) or develop your NER system. The current popular technique to create a NER system is using Machine Learning. To create it, we need train a NER model with a labeled NER dataset. You need a bunch of data that has pairs of text with its entity tag.
The problem when you train your model is preparing the data. We need data that is similar to the distribution of the real-case scenario. If you have the data, you can annotate it manually. But, if you have little data or at worst, no data at all,
You can code to generate data synthesis, use a data synthesis library, or utilize Context-Free Grammar (CFG) to generate them. If you use CFG, you can use the nltk package in Python. It has a CFG tool.
Training NER: Model
We need a model that can generalize entity extraction based on the data provided. The current popular approach in Machine Learning is using a Deep Learning model. In NLP, a pre-trained model like BERT or ROBERTA is popular to be used. What we need to do is train the pre-trained model again to the data (we call it fine-tune)..
For Indonesian data, you can use IndoBERT or IndoNLU model and train them to your data. It will produce a great quality model. You can search them on Huggingface and fine-tune the model to your data.
Information Retrieval: elasticsearch
One of the popular Information Retrieval in the text is elasticsearch. It is an Information Retrieval tool that is built on top of Apache Lucene, where it is optimized to do retrieval jobs.
It is fast because it uses the inverted index to do its search system. It matches the query’s term with the document term. It will not search a document that does not have the query’s term (or word). After the documents are selected, they will be sorted by a scoring function.

In this problem, we have a typo problem. Thus, an exact match is not suitable. Fortunately, elastic search has fuzzy query that can solve the typo problem. It will use levenshtein distance algorithm to expand the term in the query. You can read more details on this wikipedia page.
Elastic search has its own scoring function to rank the retrieved document. It follows Apache Lucene’s implementation. For more details, you can visit this page.
Summary of Automatic Order Extraction
We use a NER model to extract entities from the message. Then use the IR tool (elasticsearch) to match the product with the seller’s product list.
Here is an example of the chatbot response based on the above input:
[RESPONSE]:
Here is your biodata:
Name: Si Meong
Address: Meow Meow Street
Order:
1 x T shirt Meow = IDR 2.000.000
"Shoet Moew" is not found, did you mean "Shirt Moew", "Short Moew"?
Image Retrieval
As the title stated, it is an information retrieval by using images instead of text. Given a query image, return images that are similar to the query.
Why is this implementation important?
Sometimes, users forgot the name of something that they want to search for. Suppose that the user has the image, the option to search that is by using image similarity. Also, there are some cases where users want to search for something by image rather than the name.
How and What to do to implement it?
We need to implement an IR system that can retrieve images by using an image as the query. To do that, we can use Computer Vision knowledge with it. We need to represent the image into something that can be used as the input of similarity scoring. In an IR system, there is a term called Vector Space Model, where you represent documents (in this case, images) as vectors of weights. So, we need something to represent the image in a vector.
You can extract the vector that can represent the image by using a Deep Learning model in computer vision. You can leverage a computer vision pre-trained model. It means you can use a model to output a vector to be used to compute the relevance for both query and the documents (images). By using a distance or similarity algorithm, we can compute the distance between each of the images.
Here is the pipeline of the AI service:
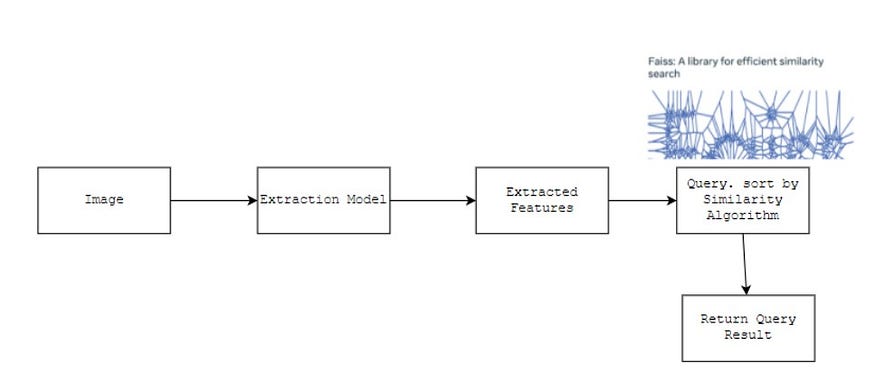
We will dive into details for each of them
Extraction Model
As I said above, we use a model to represent the image as a vector. There are many computer vision pre-trained models that can be used such as VGG-net, Resnet, Eff-net, and VIT. We can use one of them without fine-tuning it again and output the vector. Here is an example:

Sometimes, the pre-trained model needs more refinement suitable to your need. To do so, you can train it again by finetuning it using ArcFace. You need labeled image data to train it where each class tells you that they should have near-like vector output. Fine-tuning will make each image in a class become closer to each other. It attains Higher intra-class similarity and inter-class discrepancy. This technique is often used in the face-recognition model.
Image Extraction in Action
Suppose we have an image store (e.g.: NFT) and employ image retrieval, you choose to use VGGNet as the computer vision pre-trained model. Suppose you have 4 images in your database collection:

You extract the vector from your image’s query. You also do that to your images in the database.

Finally, rank the similarity between the images with each of the images in your database.

To rank the similarity, there is a neat open-source that we can use. It is called faiss.
Similarity Search: faiss
Faiss is a library that can do similarity search of dense vectors. It is popularly used for image retrieval. It hosts several similarity distance algorithms such as Euclidean and cosine similarity. It can be fast because it has a neat trick to do fast indexing ( similarity computation ).
Faiss efficiency: Partition into Voronoi Cells and Quantization
These two features are available on the Faiss to do efficiently. The first one is the ability to partition or cluster your vectors in your indexed database into Voronoi cells. It clusters your data into k clusters. When you do a query, you compare the vectors to all of the centroid (center) points of the clusters. Then you take n clusters and do a full search of the data on the n clusters. The user chooses n and k. See below for the illustration of the Voronoi cells.


Another awesome trick is by using the quantization that the Faiss has. It shrinks the original vectors and quantizes the value in the vector. First, it slices the vectors into the sub-vector. Then, it clusters its vector based on all of the vectors in the database, then changes the value of each subvector to the cluster-ID. You can see the illustration below:

The above pictures and explanations are taken from this blog (thanks for the awesome illustration). Feel free to visit it for more details.
Conclusion
I wrote 2 implementations using Information Retrieval on text and images. There are popular tools you can use here such as elasticsearch and faiss. There are neat tricks that those tools have to make an efficient search. We can use them to deploy an IR system in production.
There is the surface on how to deploy an IR system. there is also additional step you can use such as fine-tuning to make the model better and re-ranking. You can study them to make a more powerful IR system.
Feel free to comment or ask me about this post below.
Note
This post is re-posted from my blog: https://haryoa.github.io/posts/example-ir-systems/ . Feel free to visit it!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

