



When Serverless is Not Enough
Last Updated on July 25, 2023 by Editorial Team
Author(s): Sai Teja Gangapuram
Originally published on Towards AI.
a Hybrid Approach to Handle Heavy Workloads in Google Cloud: Leveraging the Scalability of Serverless Services and the Power of Compute Engine to Ensure Optimal Resource Utilization and Cost Efficiency
When working with serverless services like Cloud Run or Cloud Functions in Google Cloud, you might sometimes run into resource limitations. These services are great for handling variable workloads because they automatically scale up and down based on demand. However, they do have limits on CPU and memory, which can cause some API requests to fail.
In this blog post, we’ll discuss a solution for handling these heavy workloads by rerouting them to Compute Engine instances.
The Problem
Let’s say you have an API that’s hosted on Cloud Run. Most of the time, it works great. But occasionally, you get a request with a large payload that causes the service to hit its memory limit. The request fails, and you’re left wondering how to handle these heavy workloads.
The Solutions
- Optimize Your Code: This is often the most cost-effective solution, as it doesn’t require any additional resources. However, it can be time-consuming, and there’s a limit to how much you can optimize. If your workload is inherently resource-intensive, code optimization might not be enough.
- Increase Memory Allocation: This can be a quick fix for occasional spikes in memory usage. However, it increases the cost of each instance of your service, and it might not be a viable solution if your service rarely processes large payloads.
- Use Compute Engine: Compute Engine instances can be customized to fit your specific needs, so you can allocate exactly as much CPU and memory as you need. However, unlike Cloud Run or Cloud Functions, Compute Engine instances do not automatically scale down to zero when not in use, which can lead to higher costs if not managed properly, especially if the usage is sporadic
- Use Kubernetes Engine: Kubernetes Engine provides more granular control over your resources compared to Cloud Run or Cloud Functions. You can specify the exact amount of CPU and memory for each pod using resource requests and limits, allowing Kubernetes to manage the resources more effectively. If a pod requires more memory, you can set higher resource requests and limits, ensuring that your pod gets the necessary resources from the node it’s running on. However, Kubernetes Engine is more complex and requires more management compared to serverless services. It also comes with its own costs, so it’s important to consider these factors when deciding whether to use Kubernetes Engine.
- Use a Different Cloud Provider: Different cloud providers offer different services and pricing models, so you might be able to find a service that better fits your needs. However, migrating to a different cloud provider can be a complex and time-consuming process.
The Hybrid Solution
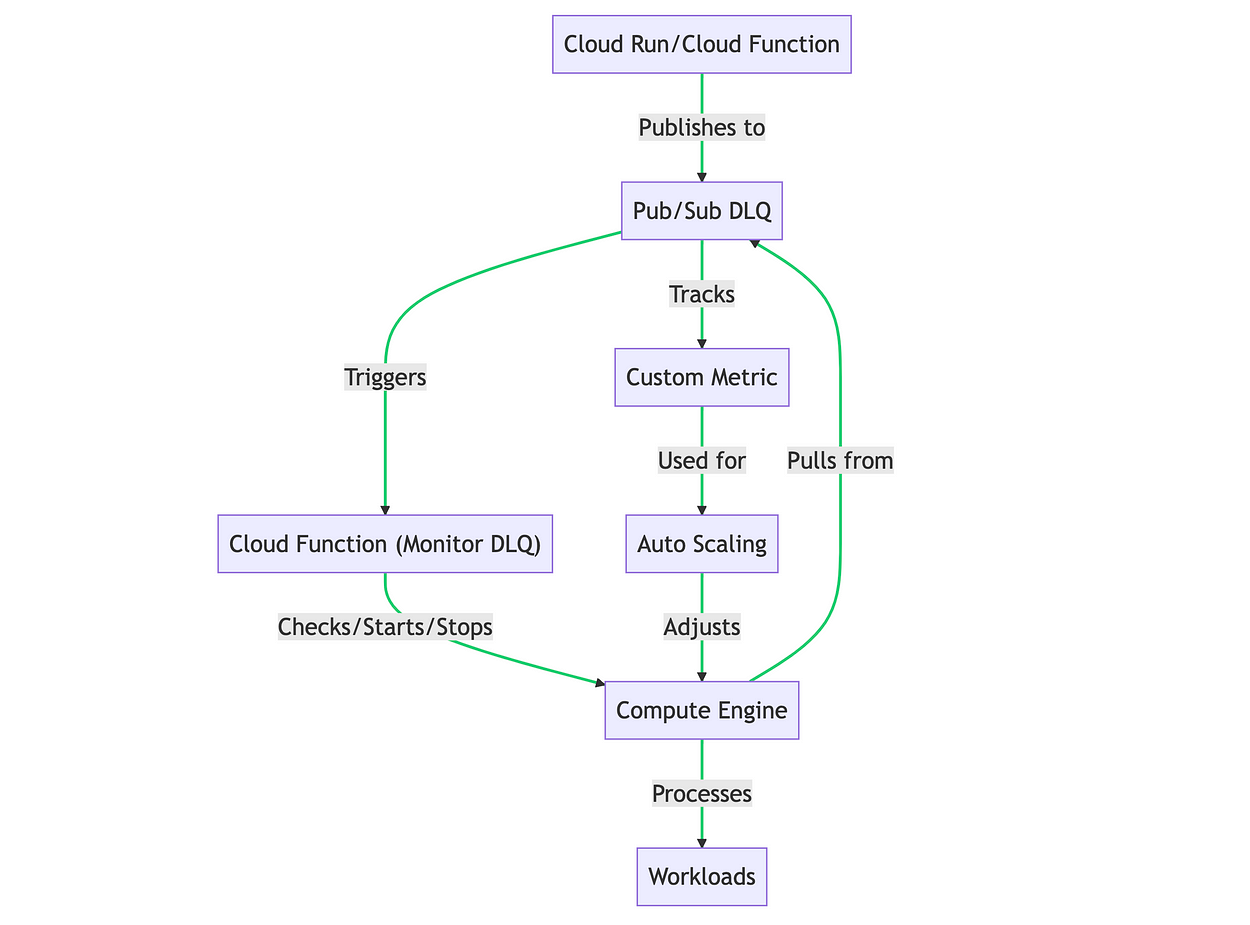
- Cloud Run or Cloud Function: This is where your API requests are initially processed. If a request fails due to resource limitations (like CPU or memory overload), an error message is published to a Pub/Sub Dead Letter Queue (DLQ). if you are using cloud tasks to process these APIs, check the below article on how to implement DLQ.
https://medium.com/the-maverick-tech/cloud-tasks-you-may-be-losing-messages-without-dlq-out-of-the-box-7aa10251a3a7 - Pub/Sub DLQ: This is a Pub/Sub topic that serves as your DLQ. Any messages that can’t be processed by your Cloud Run service due to resource limitations are published on this topic.
- Cloud Function (Monitor DLQ): This is a Cloud Function that gets triggered whenever a message is published to the DLQ. When triggered, this function performs the following actions:
- Checks if there are any existing Compute Engine instances that are currently running. If there are, it reuses these instances instead of starting a new one.
- If no instances are running, it starts a new Compute Engine instance using the Compute Engine API.
- If the DLQ is empty and there are Compute Engine instances running, it stops these instances to save costs.
4. Compute Engine: This is where the heavy workloads are processed. When a Compute Engine instance is started, it pulls messages from the DLQ and processes them. Once all the messages in the DLQ have been processed, the instance can be stopped to save costs.
How to Scale Compute Engine?
Auto-scaling in Compute Engine works by adjusting the number of instances in an instance group based on the load. However, it’s important to note that auto-scaling in Compute Engine typically works based on CPU utilization, HTTP(S) load balancing capacity, or Stackdriver Monitoring metrics. It doesn’t directly support auto-scaling based on the number of messages in a Pub/Sub queue.
That said, you can create a custom metric that tracks the number of messages in your DLQ, and then use that custom metric for auto-scaling. Here’s a high-level overview of how you might set this up:
- Create a Custom Metric: Use the Stackdriver Monitoring API to create a custom metric that tracks the number of messages in your DLQ.
- Update the Custom Metric: Create a Cloud Function that gets triggered whenever a message is published to or pulled from the DLQ. This function should update the custom metric with the current number of messages in the DLQ. check out the documentation https://cloud.google.com/monitoring/custom-metrics/creating-metrics
- Create an Instance Group: Create an instance group with your Compute Engine instances. This is necessary because auto-scaling works on instance groups, not individual instances.
- Configure Auto-Scaling: Configure auto-scaling for your instance group. Set the target metric to your custom metric, and specify the target value that should trigger scaling. For example, you might set the target value to 100, meaning that a new instance should be added whenever there are 100 messages in the DLQ.
- Test and Monitor: Test your auto-scaling setup to make sure it’s working correctly, and use Google Cloud’s monitoring tools to keep track of your instances and your DLQ.
Balancing resources and costs is key when working with Google Cloud. By using a combination of serverless services and Compute Engine, you can ensure that you have enough resources to handle your workloads, without paying for resources that you’re not using.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

