


 in AI development")
Technology Readiness Levels (TRL) in AI development
Last Updated on February 4, 2023 by Editorial Team
Author(s): Stavros Theocharis
Originally published on Towards AI.
A framework for the future development of AI
Artificial Intelligence (AI) is a subject that has been discussed almost everywhere. It continuously gets so popular that it permeates practically every field, from the business world to the entertainment industry. This technology, however, is more than simply a fad; it’s a serious means through which businesses may boost their productivity. As a result of the proliferation of use cases demonstrating how AI improved various operations, an increasing number of businesses have realized that AI and other forms of cutting-edge technology are the new arenas in which to compete. Perhaps you are among the company owners or project planners who have realized the value of AI and are looking for ways to improve their operations by using AI software.
But what is actually AI?
Artificial intelligence (AI) is a subfield of computer science and engineering that simulates intelligent behavior similar to that of humans. AI technology can be used in many different ways, such as to make fully autonomous systems that can think, learn, and act on their own. The powers of the human mind can be mimicked and even improved upon by computers thanks to AI’s ability to do so. AI is being more fully integrated into many aspects of modern life, including the creation of self-driving automobiles and the widespread use of virtual assistants. As a direct consequence of this, several tech businesses operating in a wide variety of sectors are increasing their investments in technologies that are powered by AI. This includes a wide range of things, like being able to understand spoken language, recognize faces and objects, make plans, and solve problems.
There is a substantial body of literature focused on the stages of an AI project’s lifecycle. The main possible steps are the following, as referenced in [1]:
- Exploratory data analysis
- Data preparation
- Data preprocessing
- Modeling
- Testing
These steps can certainly be supplemented with additional steps, but they define a basic structure. I would for sure add, on top of everything, “understand the business problem”. For many teams, this is obvious, but unfortunately, this isn’t always the case, and many teams realize it when it is already too late.
Personally, I am one of the primary advocates of AI-based problem-solving solutions. On the other hand, I stress the significance of introducing AI only when it is really required. An actual issue or goal should serve as the impetus for any AI project. This is crucial since AI may not be necessary for all situations. This is an important part to be considered in order to understand the following parts of this article.
So, let’s go deeper…
What is the Technology Readiness Level (TRL)?
Research and consulting in the field of information systems have relied on maturity models for many years. Therefore, there is an infinite amount of literature on them. A recent comprehensive review of the state of the art discovered 409 relevant papers and a multitude of classification techniques, many of which still need genuine validation [2].
At its core, a system’s, subsystem’s, or component’s Technology Readiness Level (TRL) is only a description of its performance history in relation to a scale developed at NASA headquarters in the 1980s. The TRL is a measure of the development and maturity of technology [3].
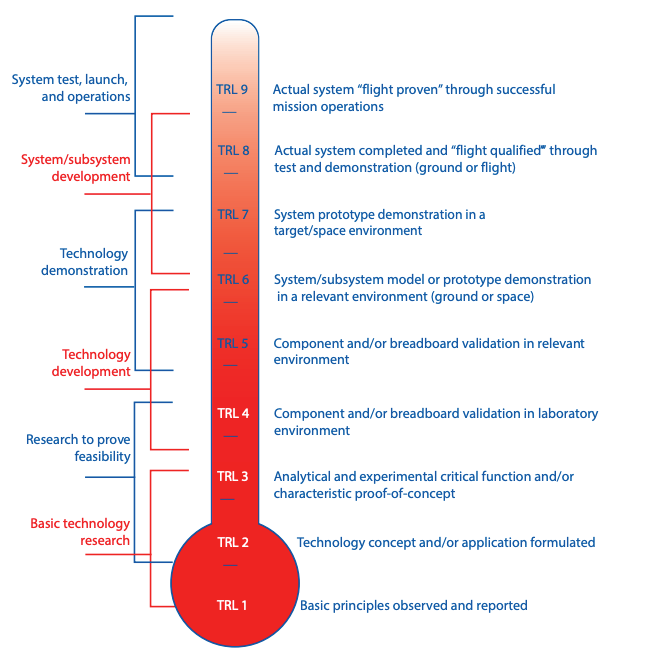
The 9 levels of the scale illustrate how far down the path of maturity a given technology must go before it may be used in its designated operational setting.
The TRL has been criticized for being utilized more as a decision-making aid in public funding for R&D&I than as an ontological explanation of the processes involved in bringing new technologies to market.
Since 2014, the TRL scale has been included in the European Union’s Horizon 2020 Work Programmes and has been extensively implemented in the context of research, development, and innovation investments funded by the European Regional Development Fund, or “ERDF” [4].
But, what about using TRL in AI applications?
Lavin A. et al. (2022) state that the default TRL process may come into sharp contrast with the rapid development and fast iteration that an AI project may need to follow. Because of this, they propose a simplified Machine Learning Technology Readiness Levels (MLTRL) framework to be put in place [5].
I would also agree that fast prototyping in many AI projects can lead to faster market entry and engagement than the competition. However, what happens when we are talking specifically about healthcare diagnostic tools or, more generally, about ethics and fairness? In such cases, rapid prototyping without specific steps may have the opposite effect on both business and society.
Models, algorithms, data pipelines, software modules, and their many combinations all have different levels of maturity, which are measured by the TRL.
The ethics part is one of the pain points of today’s AI systems. Organizational AI ethics procedures may differ, but discussions concerning ethical problems are needed to take place all the way through the TRL procedure, and in the majority of instances, these discussions are tied to a full ongoing ethics checklist from the beginning until the end. Discussions on ethics are needed with the involvement of more than one team (stakeholders, legal team, etc.) in order to get into serious consideration of the different ideas and suggestions.
Let’s focus on the different TRL levels from the MLTRL framework (process-desired outputs):
Level 0: First principles
This is the early phase of AI research for a new concept that needs to be implemented. Here, there won’t be any full data to work with yet, but some sample data instead; therefore, much of the work will consist of literature study, laying down mathematical foundations, etc.
Level 1: Goal-oriented research
Instead of running end-to-end to get a performance benchmark score, try doing low-level experiments to investigate certain model or algorithm aspects. In order to train and test the model, it is necessary to gather and analyze sample data. This data may be a subset of the whole, depending on how much of it is already accessible or how easy it is to gather. A certain review procedure has to be completed successfully before the outcomes of the experiments (the training of potential models) are considered. This entails putting in place a method that allows for a more in-depth examination of the outcomes in order to comprehend the reasons behind them. In this case, it is necessary to investigate how the data behaves when modeled by various algorithms.
This phase is not something that should be disregarded as unimportant, even if the findings are not very encouraging. The most important thing to do is to get an understanding of the nature of the data as well as the potential model solutions. All of this will be used to create the blueprints for the subsequent levels. Not everything should be in the right place (code, test, etc.), but the scope is to have something soon.
Level 2: Proof of Principle (PoP) development
Research and development efforts have begun. Model-specific technical objectives, rather than application- or product-specific ones, motivate the creation of realistically replicated settings and/or data in simulation. At this point, the formal research needs to be documented (with thorough specifications for verification and validation) and is actually a crucial deliverable. All the research requirements should be included in this deliverable. While requirements don’t mandate a certain approach, they do strive to detail what’s important to all parties involved. Do we have the correct approach to creating the product? Verification: Have we settled on the proper product to develop?
Level 3: System Development
Milestones ensure that the code is developed with consideration for interoperability, reliability, maintainability, extensibility, and scalability. A vast improvement over the sloppiness and fragility of research code is also needed. It should be well-thought-out in terms of design, architecture for dataflow and interfaces, coverage by unit and integration tests, conformance to team style guidelines, and documentation. At this level, everyone should keep in mind that parts of the code one day may be changed and refactored for possible scaling and production.
Level 4: Proof of Concept (PoC) development
This is where application-driven development gets its start, and for many companies, it’s also the first time product managers and other stakeholders outside of R&D become involved. This is meant to be a practical application of the technology being shown. For these purposes, it is crucial to make use of authentic and representative data. Evaluations of proof-of-concept work should include quantitative measures of the model, algorithm performance, and computing costs. Also, the whole process can be put on hold at this point if there are dependencies (on technology, packages, data, etc.) from other sources.
Level 5: Machine learning “capability”
Technology has progressed to the point where it is more than just a model or algorithm. At this level, an adjustment to the model or algorithm is made to transition from a standalone answer to an integral part of a broader program. Level 5 maturity should be hard to reach because it requires a big investment to turn this machine-learning technology into a product. Sometimes this can be seen as a transition from R&D to production. Other teams and members of the organization should now have access to the new technology that is being developed through demos, APIs, etc. This is a major level since moving further from it is a challenging task. Many efforts usually go wrong at this level since it is often difficult to move to production. A dedicated and well-decided allocation of resources is needed here.
Level 6: Application development
A lot of software engineering effort is required to get the code into a shippable state. Since this code will be made available to end users, it must be well-tested, have clearly defined APIs, and adhere to strict standards. There is often a chasm between ML explainability that serves ML engineers rather than external stakeholders. So, it is important to construct and validate the methods for providing model explanations at the same time as the ML model and then test their efficacy in accurately interpreting the model’s decisions in the context of downstream tasks and the end-users. What’s needed are ML modules that are strengthened for one or more specific applications. Just as it is important to test how well the model and pipeline can handle changes in how the data is distributed between development and deployment, the ML modules must also be built with these known data problems in mind.
Level 7: Integrations
Because this phase of development is susceptible to model assumptions and failure, it cannot be safely developed by software engineers alone. As a result, there is a need to balance infrastructure engineers with applied AI engineers. This will allow for the successful integration of the technology into existing production systems. The CI/CD tests are glaringly clear in this context. Concerning dependability, it’s important that quality assurance (QA) engineers play a key role here and up to Level 9.
Level 8: Mission-ready
At this level, it is proven that the technology is functional in its final form and under the circumstances that were anticipated. There have to be more tests put in place covering various elements of deployment, most notably A/B testing. At this point, the most crucial choice is whether or not to proceed with the deployment, as well as when to do so. In some conditions, it may be possible to run models in shadow mode for a considerable amount of time. This would be useful for doing a stress test on the system and determining how susceptible the machine learning model (or models) is to performance caused by variations in the data (data quality, data drift, and concept drift).
Level 9: Deployment
When it comes to the deployment of AI and ML technologies, there is a considerable need to keep a close eye on the most recent version while also giving deliberate thought to how the next version might be improved. For example, a performance decline might be imperceptible yet still have a significant impact, and enhancements to features often carry with them unanticipated repercussions and limits. Therefore, the primary emphasis at this level is on engineering for maintenance. For spotting anomalies in model behavior, especially those that are not immediately apparent in the model’s or product’s final performance, monitoring for data quality concerns and data drifts is essential. Different from other contexts, data logging in ML systems should record the statistical aspects of input features and model predictions, as well as any outliers. An AI cannot be implemented safely without first undergoing exhaustive testing for these.
It is strongly suggested that drift experiments be carried out at earlier stages than is usually the case before deployment really takes place. When it comes to AI systems, data-first architectures are preferable to the software industry norm of designing services. Enabling monitoring to detect training-serving skew and alert the team when it’s time to retrain is essential for retraining and upgrading models. Adding or changing features in an effort to enhance a model might have unforeseen implications, like increased latency or even bias. A critical component is hidden here: in order to reduce risk, any adjustment to the modules will have to go back to Level 7 at the very least. Human input may also be asked for and added to the system’s feedback loop (human-in-the-loop) to improve its overall performance.
All the aforementioned levels are graphically shown below:

All of the above can be followed as a series, but they can also be implemented in a cycle process. For example, if a stage needs to be accessed again, it is easy to do so and continue that way. Many times, some issues may be found in the integration parts, and the step of R&D can also be used in order to search for methods, etc.
Conclusion
To ensure that the AI software is ready for the jump to systems-level development, the R&D community should use TRLs as a crucial tool for planning, prioritizing, and allocating resources. Similarly, TRLs are useful because they enable more thorough evaluations of the technology behind their system acquisition and development initiatives, which in turn facilitates smarter judgments. Nevertheless, TRLs shouldn’t be seen as a silver bullet for getting rid of technical concerns in acquisitions or developments. Simply put, TRLs offer context to decision-makers in teams about projects, helping them make wiser, more methodical choices.
Ethical issues should be given the top priority at every stage of the framework, and the framework itself should adapt over time to keep up with the rapidly developing field of AI ethics.
In my opinion, this is the way to go in most cases where steps play an important role in the entire process. Of course, some of the steps can be tailored to the specific use case. This is fully connected with sustainable software systems, where both the ethics and failures have to be seriously considered and steps should not be skipped.
References
[1] K. Dubovikov, Managing Data Science: Effective strategies to manage data science projects and build a sustainable team (2019). Birmingham, UK: Packt
[2] J. B. Sarmento & A. P. Seixas Costa, Enterprise Maturity Models: A Systematic Literature Review (2019). Enterprise Information Systems
[3] NASA (2003). The NASA Systems Engineering Handbook
[4] M. Héder, From NASA to EU: the evolution of the TRL scale in Public Sector Innovation (2017). The Innovation Journal: The Public Sector Innovation Journal
[5] A. Lavin, C. Gilligan-Lee, A. Visnjic, S. Ganju, D. Newman, S. Ganguly, D. Lange, A. Baydin, A. Sharma, A. Gibson, S. Zheng, E. Xing, C. Mattman, J. Parr, Y. Gal, Technology readiness levels for machine learning systems (2022). Nature Communications
Other resources:
- The call for a Data Science Readiness Level
- AI Watch: Assessing Technology Readiness Levels for Artificial Intelligence
Technology Readiness Levels (TRL) in AI development was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")