



Multimodal AI → Combining Text With Images
Last Updated on July 10, 2022 by Editorial Team
Author(s): Shubham Saboo
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
OpenAI GPT-3 combined with DALL.E-Flow to generate creative artwork!
Overview
In this article, we will look at how you can combine the text generation capabilities of GPT-3 with the creative image generation part of DALL.E to produce a piece of art that would have required days if not months, with the conventional setup 😱
Without further ado, let’s write a poem on unstructured data in the style of Shakespear using GPT3TextGeneration Executor and generate the illustrations for the same using DALL.E-Flow.
We will use the following colab notebook to access the GPT-3 Executor as it will keep all the computing on the cloud, so you don’t have to worry about the dependencies 👇
We will take the poem generated by GPT-3 and send it as input to DALL.E Flow to generate the artistic illustrations for our poem. We will use the following notebook to do that 👇
Graphical Art Book
Poem Generated by GPT-3 🖌
Unstructured data is like a wildflower in a field
It’s pretty and free,
But it can be hard to control
And it can be tough to find
When you’re looking for something specific!
Graphical Illustrations 🎨
Following is a line-by-line graphical illustration of the above-generated poem using DALL.E Flow 👀
Line 1 → “Unstructured data is like a wildflower in a field”

Line 2 → “It’s pretty and free”

Line 3 → “But it can be hard to control”

Line 4 → “And it can be tough to find when you’re looking for something specific!”

What is GPT-3?
GPT-3 is the first-ever generalized language model in the history of natural language processing that can perform equally well on an array of NLP tasks. GPT-3 stands for “Generative Pre-trained Transformer,” and it’s OpenAI’s third iteration of the model. Let us break down these three terms:
- Generative: Generative models are a type of statistical model that are used to generate new data points. These models learn the underlying relationships between variables in a dataset in order to generate new data points similar to those in the dataset.
- Pre-trained: Pre-trained models are models that have already been trained on a large dataset. This allows them to be used for tasks where it would be difficult to train a model from scratch. A pre-trained model may not be 100% accurate, but it saves you from reinventing the wheel, saving time, and improving performance.
- Transformer: A transformer model is a famous artificial neural network invented in 2017. It is a deep learning model that is designed to handle sequential data, such as text. Transformer models are often used for tasks such as machine translation and text classification.
GPT-3 is considered the first step by some in the quest for Artificial General Intelligence. To understand how it is revolutionizing the field of AI, check out the most updated Primer on GPT-3!
What is DALL.E Flow?
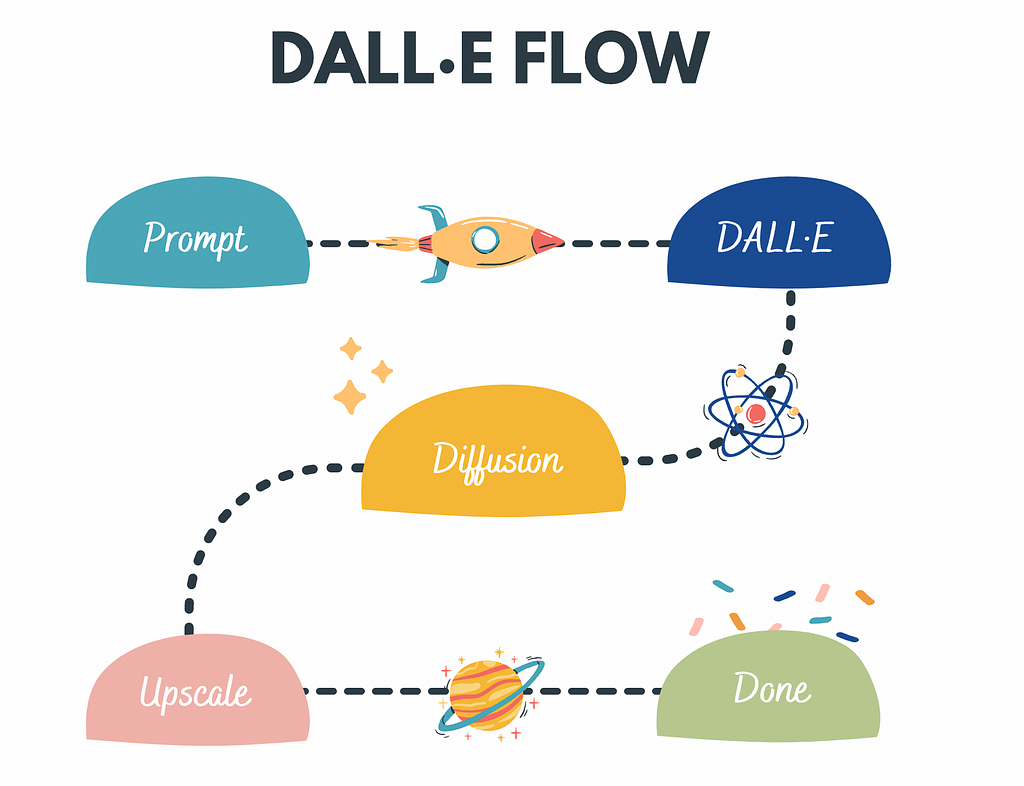
DALL·E Flow is an interactive workflow for generating high-definition images from a text prompt. First, it leverages DALL·E-Mega to generate image candidates and then calls CLIP-as-service to rank the candidates w.r.t. the prompt.
Why Human-in-the-loop?
Generative art is a creative process. While recent advances of DALL·E unleash people’s creativity, having a single-prompt-single-output UX/UI locks the imagination to a single possibility, which is bad no matter how satisfactory this single result is. DALL·E Flow is an alternative to the one-liner by formalizing the generative art as an iterative procedure.
To know more about how DALL.E Flow works, check out the following GitHub Repository.
Prompt Engineering: The Secret Sauce
If you have made this far reading the article, you might be thinking about some of these questions 🤔
How to use GPT-3 and DALL.E Flow to get the best results?
How to figure out the input for these AI models that produces the desired result?
How does a slight change in the input text significantly affects the output?
The answer to all your questions lies in a simple term → Prompt Engineering
“Prompt Engineering is the art and science of giving clear input text (instructions) to a generative AI model such that it generates the desired output.”
The Secret to writing good prompts is understanding what these AI models know about the world and how to get the models to use that information for generating useful results.
To learn about Prompt Engineering in detail, check out the following resources 👇
- Chapter 2 of O’Reilly Book on GPT-3
- An article on Prompt Engineering by Cohere
- Prompt Engineering: The Career of Future
More about Prompt Engineering here 👉
Conclusion
The future of creative AI is looking very bright. By combining text with images, we can create some truly amazing and unique creations. This is just the beginning of what you can do with this technology, and you can only imagine what the future holds for us!
If you would like to learn more or want to me write more on this subject, feel free to reach out.

If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post's visibility for other medium users.
Multimodal AI → Combining Text With Images was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



