Logo:
Logo:  Areas Served:
Areas Served: 
Overcoming LLMs’ Analytic Limitations Through Suitable Integrations
Last Updated on April 22, 2024 by Editorial Team
Author(s): Meghdad Farahmand Ph.D.
Originally published on Towards AI.
Introduction
Despite their significant power and remarkable potential to become our only go-to solution for many of our AI and data-related problems in the near future, LLMs struggle with data analysis, particularly for big data, due to their limited context window and the precision of statistical counts and metrics, which doesn’t align with LLMs’ generative and stochastic style.
As we illustrate in this article, integrating them into the right system can eradicate this problem, making LLMs capable of handling precise statistics and analyses.
The Use of LLMs: An Attractive Solution for Data Analysis
Not only can LLMs deliver data analysis in a user-friendly and conversational format “via the most universal interface: Natural Language,” as Satya Nadella, the CEO of Microsoft, puts it, but also they can adapt and tailor their responses to immediate context and user needs. Moreover, their pre-training and world knowledge allow them to provide supplementary information when necessary. Nevertheless, we will run into several problems as soon as we try to have an LLM carry out our data analysis tasks.
The Problems
For the purpose of this short study, let’s consider the IMDB Movies Review dataset as an example. This 66 MB corpus contains 50K documents or ~13.9M tokens, so it’s not particularly large.
Our study is built around several fundamental standard text analysis tasks essential for downstream NLP applications. We aim to explore document length and word frequency distributions. Additionally, we’re keen on discovering the number of unique words, all words, and the most frequent verbs and adjectives in the corpus.
Problem 1: Limited Context Window
As of the writing day, the latest models on OpenAI API are the gpt-4 series, with a context window of 128,000 tokens. That means we can pass a maximum of 128,000 tokens to this model.
We will have significant difficulties if we try to solve the mentioned text analysis problems with the gpt-4 series.
The first issue that we encounter is the limited context window. It’s too small to accommodate all the data in the IMDB dataset. We can only fit 612 documents which is only ~0.92% of the original dataset. In other words, more than 99% of the dataset does not fit into the context window.
Problem 2: Hallucination
Assume, through tedious efforts, we break our data into batches, run each batch independently, and somehow add up the results. The results are likely inexact and based on hallucination; since LLMs are generative models designed to generate the most probable responses in a stochastic fashion, they cannot accurately calculate statistics (See numerous related experiments online, for instance, this article and the issues here and here).
Problem 3: Multifaceted Problems
Suppose our problem becomes more complex. We wish to identify the top 10 Multiword Expressions (MWEs) — phrases kangaroo court and red tape whose meaning cannot be interpreted from the meaning of their components and are treated as a single semantic unit — and most common gender biases in our corpus of text. In that case, we will have an even harder time than before with an LLM. These are multifaceted problems in which, by definition, certain entities should first be identified. An entire statistical analysis of those entities in the dataset should be carried out. Finally, specific algorithms should run on top of that analysis.
LLMs are broadly incapable of solving such multifaceted tasks, contrary to most text analysis tools, which can seamlessly solve all of the mentioned tasks.
Solving Problems 1–3 Through Integration With the Right Tool
Let’s consider Wordview as an example of such tools. It’s an open-source Python package for Exploratory Data Analysis of text. It has functions for the analysis of explicit text elements such as words, n-grams, POS tags, and multi-word expressions, as well as implicit elements such as clusters, anomalies, and biases.
Wordview can seamlessly process the entire IMDB dataset, produce all the required statistics, and solve the above tasks within seconds. However, like all statistical analyses, the results are static and bland. They come in the form of tables, plots, and distributions, which are, in all honesty, not so tempting to look at for most of us.

That’s where LLMs can enter the picture and deliver significant value. They would allow the user to interact with the analysis results in natural language, circle back, include new context, ask for interpretations, and inquire about topics that are related to their analysis but go beyond their data. But we first need to address the discussed problems.
One common approach to addressing LLM hallucination is Retrieval Augmented Generation (RAG), which aims to ground LLMs on the most relevant and up-to-date information. RAG, however, mainly applies to Question Answering tasks where the answer to a prompt exists in a document passage or a database entry within the organization. It’s not readily applicable to data analysis tasks where a holistic view and processing of the entire dataset are central to yielding reliable results.
That’s why we should pay attention to the task at hand before we ground the LLM via RAG. In the data analysis case, retrieval of the related documents is irrelevant. Processing the data, counting statistics, and identifying correlations are.
Wordview recently integrated gpt-3.5-turbo, which allows it to engage in a conversation with the user about the statistics and analysis of their text corpus.
This approach not only makes the statistical analysis results accessible through the most familiar and user-friendly interface, i.e., natural language, but also allows the user to benefit from the vast pre-trained LLM knowledge for discussing and understanding those results. At the same time, it almost entirely eliminates LLM’s hallucination and empowers it to produce factually correct and precise results.
Below is a screenshot of such a conversation with a user about some of the statistics of the IMDB corpus. We opted for the default Wordview setting, where Stop Words and punctuations are ignored in the calculation of the statistics.

Note firstly, how this integration with Wordview allows an LLM to produce accurate answers about a large dataset that it is otherwise incapable of handling, and secondly, how the LLM is capable of producing accurate and non-hallucinating answers (the numbers are verified) as a result of this integration.
As another example, the following screenshot illustrates a short conversation with Wordview about the MWEs identified in the dataset.
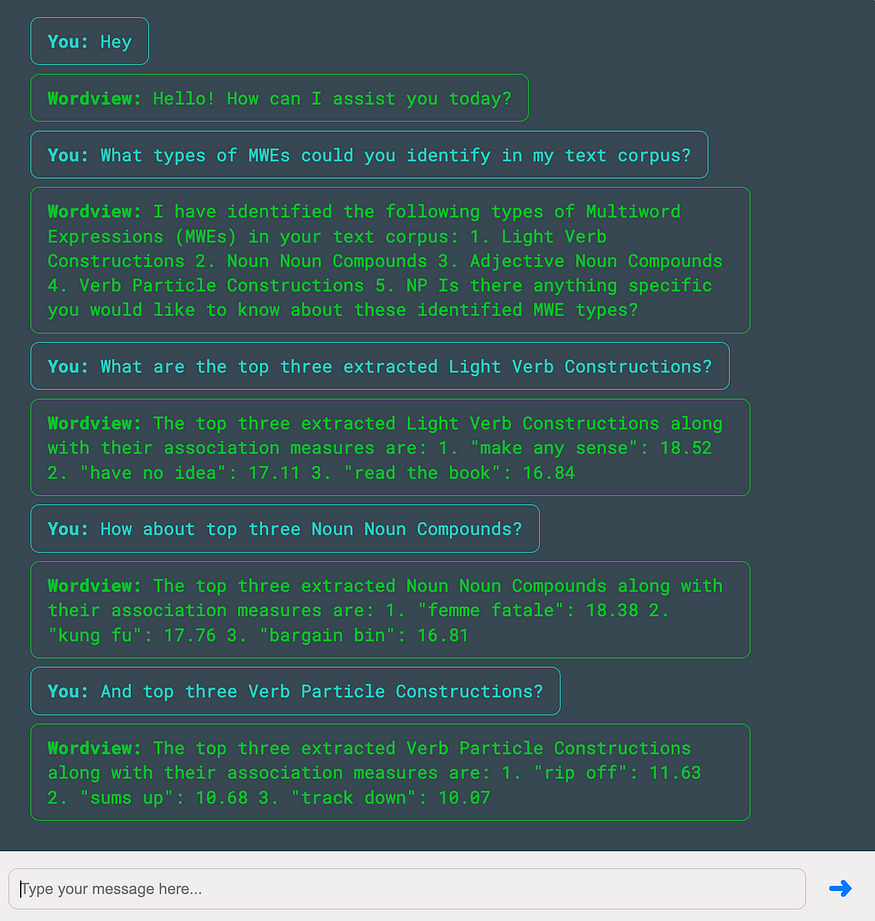
Such integrations can be highly valuable for production-level and enterprise use cases where LLM benefits are highly desired, but their hallucination is unacceptable.
See the following conversation, for instance, where we try to push the LLM to doubt its responses. It apologizes for the confusion but nevertheless produces the correct results to the decimal points due to the constraint that was imposed on the LLM by Wordview’s precise analysis:

Conclusions
Large Language Models have transformed AI and Machine Learning. They have demonstrated tremendous potential and opened doors to developing previously impossible applications. However, they have limitations. They cannot reason as effectively as we might believe when solving multifaceted problems. They struggle with data analysis, statistics, and math. On the other hand, their context window for handling big data scales is small.
AI researchers and engineers relentlessly innovate, pursue improvements, and propose approaches to address the LLM limitations. This blog delves into one such approach: the integration of LLMs into an Exploratory Data Analysis tool, a strategy that can effectively overcome many of LLMs’ limitations in statistical analysis.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts