



Don’t Be Overwhelmed by NLP
Last Updated on August 24, 2020 by Editorial Team
Author(s): Mukul Malik
Natural Language Processing
Don’t Be Overwhelmed by NLP Research
How to cope with the volume of ongoing research in NLP which is probably infeasible for you
What is going on?
NLP is the new Computer Vision
With enormous amount go textual datasets available; giants like Google, Microsoft, Facebook etc have diverted their focus towards NLP.
Models using thousands of super-costly TPUs/GPUs, making them infeasible for most.
This gave me anxiety! (we’ll come back to that)
Let’s these Tweets put things into perspective:
Tweet 1:

Tweet 2: (read the trailing tweet)
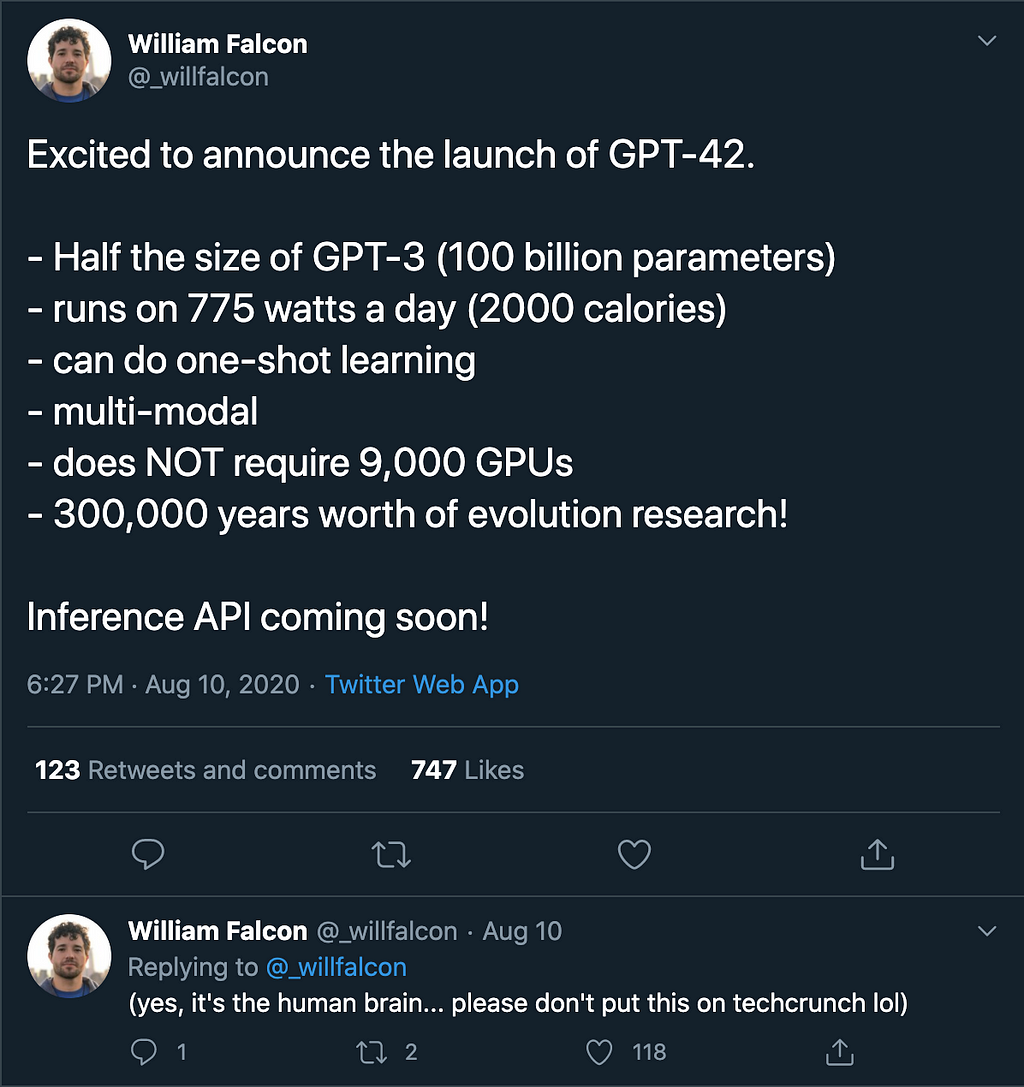
Consequences?
In about last one-year following knowledge became mainstream:
- Transformers was followed by Reformer, Longformer, GTrXL, Linformer, and others.
- BERT was followed by XLNet, RoBERTa, AlBERT, Electra, BART, T5, Big Bird, and others.
- Model Compression was extended by DistilBERT, TinyBERT, BERT-of-Theseus, Huffman Coding, Movement Pruning, PrunBERT, MobileBERT, and others.
- Even new tokenizations were introduced: Byte-Pair encoding (BPE), Word-Piece Encoding (WPE), Sentence-Piece Encoding (SPE), and others.
This is barely the tip of the iceberg.
So while you were trying to understand and implement a model, a bunch of new lighter and faster models were already available.
How to Cope with it?
The answer is short:
you don’t need to know it all, know only what is necessary
Reason
I read them all to realize most of the research is re-iteration of similar concepts.
At the end of the day (vaguely speaking):
- the reformer is hashed version of the transformers and longfomer is a convolution-based counterpart of the transformers
- all compression techniques are trying to consolidate information
- everything from BERT to GPT3 is just a language model
Priorities -> Pipeline over Modules
Learn to use what’s available, efficiently, before jumping on to what else can be used
In practice, these models are a small part of a much bigger pipeline.
Take an example of Q&A Systems. Given millions of documents, for this task, something like ElasticSearch is way more essential to the pipeline than a new Q&A model (comparatively).
In production success of you, the pipeline will not (only) be determined by how awesome is your Deep Learning model but also by:
- the latency of the inference time (read about Onnx, quantization)
- predictability of the results and boundary cases
- the ease of fine-tuning
- the ease of reproducing the model on a similar dataset
Personal Experience
I was working on an Event Extraction pipeline, which used:
- 4 different transformer-based models
- 1 RNN-based model
But. At the heart of the entire pipeline were:
- WordNet
- FrameNet
- Word2Vec
- Regular-Expressions
And. Most of my team’s focus was on:
- Extraction of text from PPTs, images & tables
- Cleaning & preprocessing text
- Visualization of results
- Optimization of ElasticSearch
- Format of info for Neo4J
It is more essential to have an average performing pipeline than to have a non-functional pipeline with a few brilliant modules.
Neither Christopher Manning nor Andrew NG knows it all. They just know what is required and when it is required; well enough.
So, have realistic expectations of yourself.
Thank you!
Don’t Be Overwhelmed by NLP was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts




")

