
 Logo:
Logo:  Areas Served:
Areas Served: 
Hands-on Distributed Training with Determined AI, a Breakthrough Algorithm, Coded Bias… and More!
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
AI news, research, and updates, an exciting meetup on hands-on distributed training, and our monthly editorial picks!
If you have trouble reading this email, see it on a web browser.
Welcome back, Towards AI family! It has been a little while since we sent our last newsletter. In this edition, we are bringing you some exciting goodies we think you will enjoy. To get started, check out this excellent and free-to-access meetup on hands-on distributed training organized by our friends at Determined AI (free lunch included 😊):
Determined AI is hosting a lunch-and-learn session on how to speed up model training and save money on GPU resources in the process. Join us on April 13 for a hands-on, interactive tutorial on practical distributed training and get lunch on us!
Carnegie Mellon’s Delphi Research Group, in partnership with Facebook, released its latest COVID-19 survey findings. The survey analysis shows that vaccine hesitancy is persistent, data science and statistics Professor Alex Reinhart discusses potential strategies to tackle it.
Computer vision has several potential applications. However, is facial recognition ethical and accurate? MIT researcher Joy Buolamwini tackles this paradigm, as she discovers how facial recognition does not see dark-skinned faces accurately in the documentary Coded Bias, just launched on Netflix.
Are you looking forward to submitting your paper to NeurIPS 2021? Check out this neat guide by the NeurIPS Program Chairs, highlighting a checklist to ensure that your paper is up to its standards, from transparency, increasing integration, potential social impact, ethical review, and so on.
If you are interested in reinforcement learning, check out this project by Google AI, showcasing how a novel algorithm teaches agents to solve tasks by providing only examples of success. Its novelty lies due to the fact that it does not need hand-crafted reward functions as with usual reinforcement learning algorithms, outperforming prior learning approaches.
The Conference on Fairness, Accountability, and Transparency (ACM FAccT 2021) is becoming very popular due to its efforts to increase diversity, equity, and inclusion in multidisciplinary research, specifically in computer science, social sciences, and humanities. This post by Nil-Jana Akpinar from machine learning at CMU showcases some relevant research papers and tutorials accepted to FAccT 2021 to give you an idea of what the conference is looking for.

Machine learning datasets are filled with labeling errors. Researchers from MIT and Amazon dive into this problem in their research paper, highlighting how 10-widely cited datasets, including ImageNet contain an error rate of 3.4%. If you would like to read a more friendly version, check out Label Errors in ML Tests Sets.
If you have not checked it out yet, we recently launched our book on descriptive statistics with Python. This article or this PDF provides a sample of the first 36 pages of the book. Please don’t forget that you can access this work, many more books, and other goodies by becoming a member.
Now into the monthly picks! We pick these articles based on readers, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top-performing articles, and our editors will choose a couple of essays that didn’t have outstanding performance, but due to their quality — they made the cut for the month.
Sharing is caring. Please feel free to share our newsletter or subscription link with your friends, colleagues, and acquaintances. One email per month; unsubscribe anytime! If you have any feedback on how we can improve, please feel free to let us know.
📚 Editor’s choice featured articles of the month ↓ 📚

We Don’t Need To Worry About Overfitting Anymore by Sean Benhur J
In Deep Learning, we use optimization algorithms such as SGD/Adam to achieve convergence in our model, which leads to finding the global minima, i.e., a point where the loss of the training dataset is low. But several kinds of research, such as Zhang et al., have shown that many networks can easily memorize the training data and have the capacity to overfit. To prevent this problem and add more generalization, Researchers at Google have published a new paper called Sharpness Awareness Minimization, which provides State of the Art results on CIFAR10 and other datasets.
[ Read More ]

State-of-the-Art Data Labeling With a True AI-Powered Data Management Platform by Towards AI Team
Data labeling is an essential part of the machine learning workflow, particularly data preprocessing, where both input and output data are labeled for classification to present a learning base for planned data processing. We use data labeling to identify raw data, such as objects in images, videos, text, and so on. It works by affixing one or more significant and informative labels to produce context so that a model can learn from it.
[ Read More ]
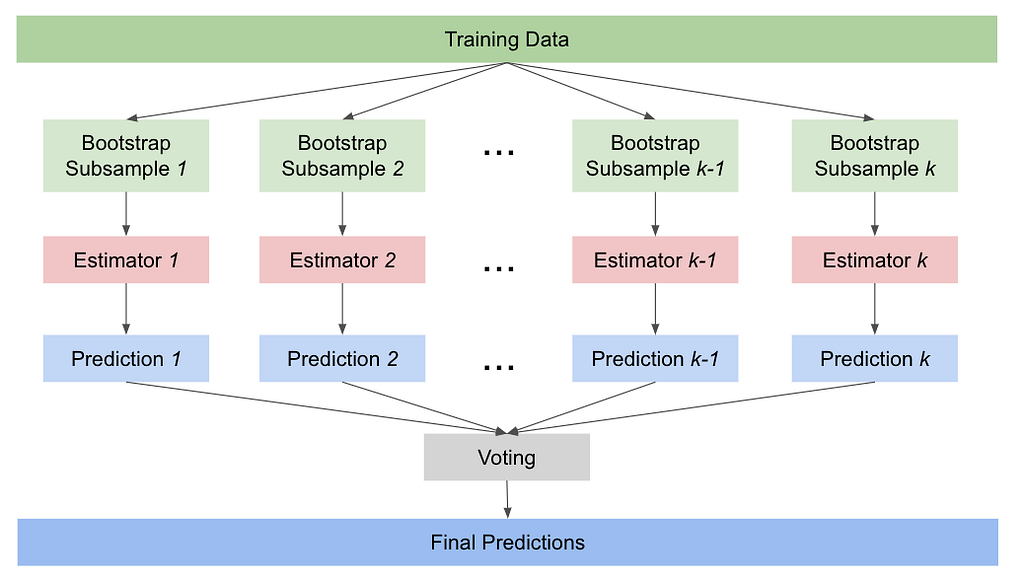
Ensemble Methods Explained in Plain English: Bagging by Claudia Ng
In this article, I will go over a popular homogenous model ensemble method — bagging. Homogenous ensembles combine a large number of base estimators or weak learners of the same algorithm. The principle behind homogenous ensembles is the idea of “wisdom of the crowd” — the collective predictions of many diverse models are better than any set of predictions made by a single model. There are three requirements to achieve this…
[ Read More ]
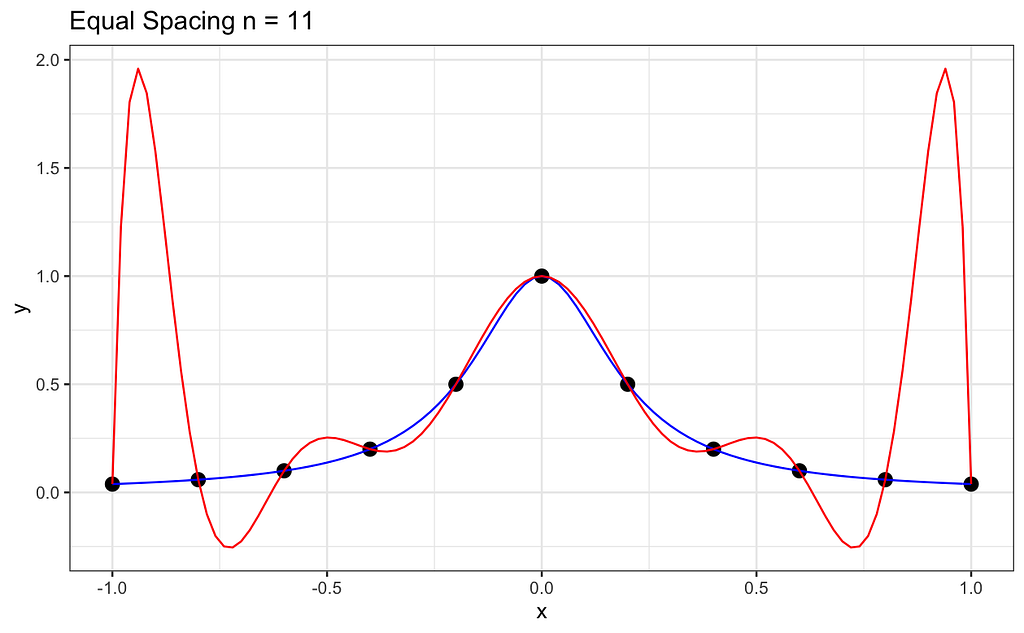
GAMs and Smoothing Splines(Part-1) by Sai Pradeep Peri
In today’s world, where Deep Learning is used for most Machine Learning applications, Interpretability has become paramount in real-world applications. Model’s Interpretability is crucial to understand how different variables interact to generate model decisions. In this context, I want to summarize a powerful family of interpretable models — Generalized Additive Models (GAM) along with their building blocks — Smoothing Splines.
[ Read More ]
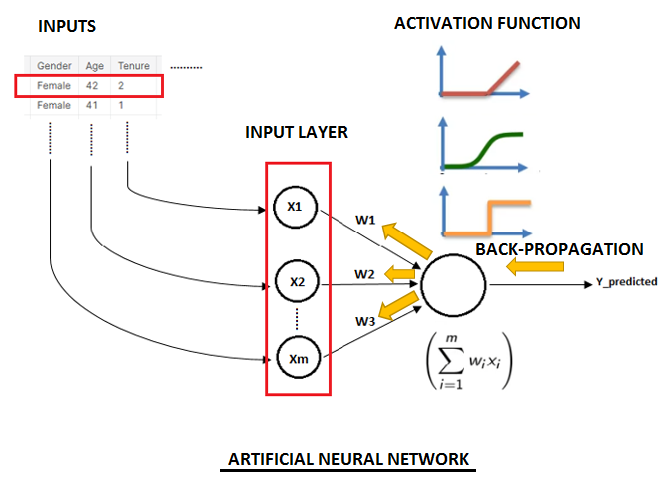
Step-by-Step Basic Understanding of Neural Networks with Keras in Python by Amit Chauhan
Neural networks are on boom in industries all over the globe. It’s about traditional machine learning algorithms for regression, classification, clustering, etc. When we get large complex data, the problems arise with accuracy, over-fitting, and more testing and training time. In this article, we will discuss the simple neural network and its definition with Keras’s example. The use of neural networks over traditional machine learning for accuracy and more large complex data.
[ Read More ]

Analyzing Poetry in Python by Curtis Thompson
How easy is it to write a poem? Slap a few words down on a page, make them rhyme, and you have your poem. Some poets are probably wincing just after reading that sentence. Maybe you have decided to follow a well-known poetry form such as haikus, limericks, and sonnets — that will certainly make your words look like a poem. Sometimes it can be hard to know whether your poem correctly fits the form. This is where your coding skills come in!
[ Read More ]

Why Python Is The Perfect Language For A Machine Learning Project by Bipin Biddappa P K
Python was always doing well because of its stable and easily maintainable nature, and like a popular teen going through the high school corridors, python has been catching many eyeballs in recent years. TIOBE Index named it the language of the year, four times so far since its inception.
[ Read More ]

300 NLP Notebooks and Freedom by Quantum Stat
If this is your first time hearing about the SDNR, it’s a handy repository of more than 300 Colab notebooks (and counting) focusing on natural language processing (NLP). Colab is essentially a Jupyter notebook that one can use and share via a web-based kernel. The best part of these notebooks is that you can use a free GPU, usually a K80 or a T4 or even a TPU (if you are feeling dangerous), to fine-tune your NLP model. If you’re looking for an introduction to Colab, you can watch this video here…
[ Read More ]
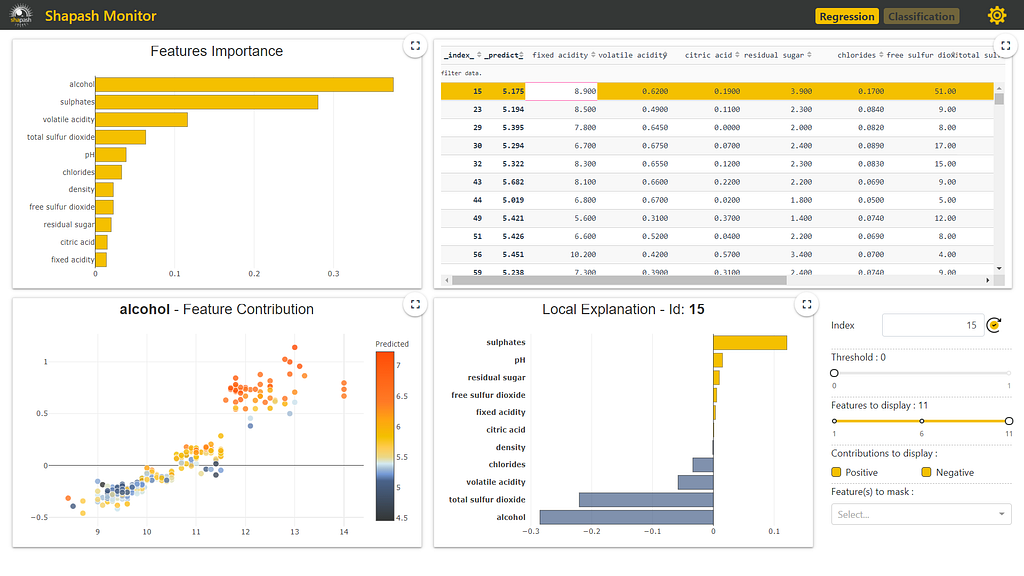
Build A Web App To Interpret Your ML Predictions in Seconds With Shapash by Chetan Ambi
Shapash lets you create a beautiful web app for interpreting your machine learning models in seconds as soon as you have the model ready. You don’t have to spend time creating web applications of your own. This saves much time for you and your team. Isn’t this exciting? If you are reading till this point, then I am sure you are interested in this.
[ Read More ]

A Complete Guide to Confidence Interval, t-test, and z-test in R for Data Scientists by Rashida Nasrin Sucky
The confidence interval, t-test, and z-test are trendy and widely used methods in inferential statistics. They are so important because we can only use a sample to conclude a large population for any research or data analysis. In that case, these inferential statistical methods help us consider the errors and infer a better estimate for a larger population using a smaller sample.
[ Read More ]

Data Scientists Must Embrace Mathematics by Benjamin Obi Tayo Ph.D.
Data science is an interdisciplinary field that uses scientific methods, processes, and algorithms to extract knowledge and insights from data. The field of data science has several subdivisions such as data mining, data transformation, data visualization, machine learning, deep learning, etc. As a scientific discipline, a data science task could be broken into 3 main stages…
[ Read More ]

How Microsoft Icebreaker Addresses the Cold-Start Challenge in Machine Learning Models by Jesus Rodriguez
The acquisition and labeling of training data remain one of the major challenges for the mainstream adoption of machine learning solutions. Within the machine learning research community, several efforts such as weakly supervised learning or one-shot learning have been created to address this issue. Microsoft Research recently incubated a group called Minimum Data AI to work on different solutions for machine learning models that can operate without the need for large training datasets.
[ Read More ]
Why is Business Intelligence useful for a Data Scientist? by Eugenia Anello
I am actually meeting Business Intelligence during my Data Science internship. But it’s not the first time. It happened again in a previous internship for another type of role in an ICT company. During the university, I never did a course about this topic, and it’s not easy to understand when there are many new concepts and not many resources on the Internet. So, what is Business Intelligence? Why do we usually meet it when we go to work and not during the studies?
[ Read More ]

Fastai Course Chapter 1 on Linux by David Littlefield
his article is an expanded guide meant to help you learn what’s happening throughout the chapter. It provides definitions of terms, commands, and code that are used in the article. It also provides an underlined text which has links to additional definitions in the glossary of the article. The first chapter from the textbook shows how to build 5 different models with about 5 lines of code. It builds a model for image classification, image segmentation, text classification…
[ Read More ]

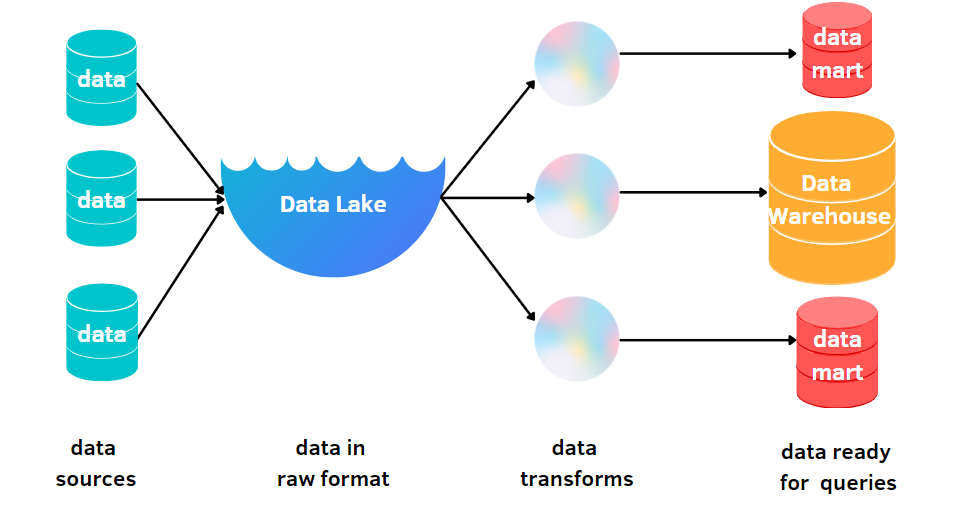
Building a Data Lake with AWS by Magdalena Konkiewicz
Every day, big and small companies collect more and more data. Enterprises typically gather data about companies’ operations, clients, competition, products, etc. They need to store, process, and efficiently analyze all this information. The traditional solution of setting up warehouses and databases is simply not up to the task of satisfying the companies’ needs as they deal with vast amounts of data.
[ Read More ]
- Sponsors | Learn How to Become a Sponsor with Towards AI
- Towards AI
- Join us ↓ | Towards AI Members | The Data-driven Community
🙏 Thank you for being a subscriber with Towards AI! 🙏
Follow us ↓
[ Facebook ] |[ Twitter ]| [ Instagram ]| [ LinkedIn ] | [ Github ] | [ Google News ]
Hands-on Distributed Training with Determined AI, a Breakthrough Algorithm, Coded Bias… and More! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

