



Scalable and Blazing Fast Similarity Search With Milvus Vector Database
Last Updated on June 30, 2022 by Editorial Team
Store, index, manage and search trillions of document vectors in milliseconds!
Author(s): Dipanjan (DJ) Sarkar
Introduction
In this article, we will cover some interesting aspects relevant to vector databases and similarity search at scale. In today’s rapidly evolving world, we see new technology, new businesses, new data sources and consequently we will need to keep using new ways to store, manage and leverage this data for insights. Structured, tabular data has been stored in relational databases for decades, and Business Intelligence thrives on analyzing and extracting insights from such data. However, considering the current data landscape,
organizations have been leveraging the power of machine learning and deep learning to try and extract insights from such data as traditional query-based methods may not be enough or even possible. There is a huge, untapped potential to extract valuable insights from such data and we are only getting started!
“Since most of the world’s data is unstructured, an ability to analyze and act on it presents a big opportunity.”
— Mikey Shulman, Head of ML, Kensho
Unstructured data, as the name suggests, does not have an implicit structure, like a table of rows and columns (hence called tabular or structured data). Unlike structured data, there is no easy way to store the contents of unstructured data within a relational database. There are three main challenges with leveraging unstructured data for insights:
- Storage: Regular relational databases are good for holding structured data. While you can use NoSQL databases to store such data, it becomes an additional overhead to process such data to extract the right representations to power AI applications at a scale
- Representation: Computers don’t understand text or images as we do. They only understand numbers and we need to convert unstructured data into some useful numeric representation, typically vectors or embeddings.
- Querying: You can’t query unstructured data directly based on definite conditional statements like SQL for structured data. Imagine, a simple example of you trying to search for similar shoes given a photo of your favorite pair of shoes! You can’t use raw pixel values for search, nor can you represent structured features like shoe shape, size, style, color, and more. Now imagine having to do this for millions of shoes!
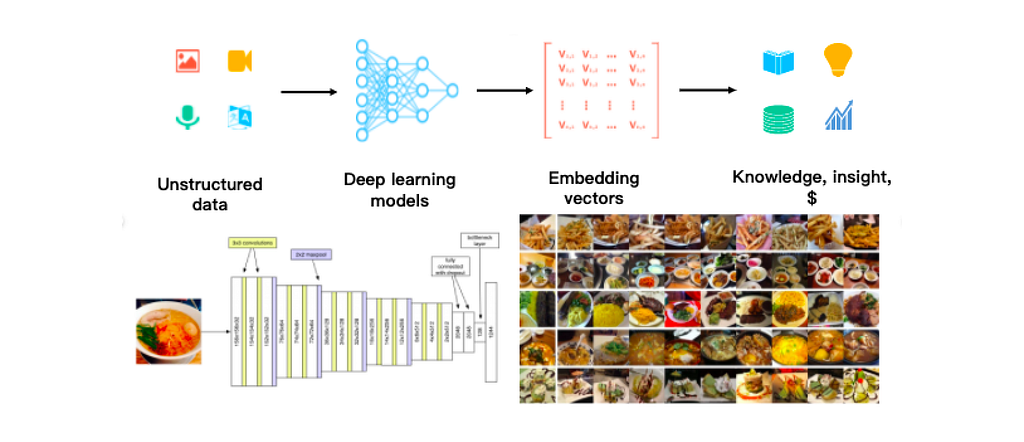
Hence, in order for computers to understand, process, and represent unstructured data, we typically convert them into dense vectors, often called embeddings.
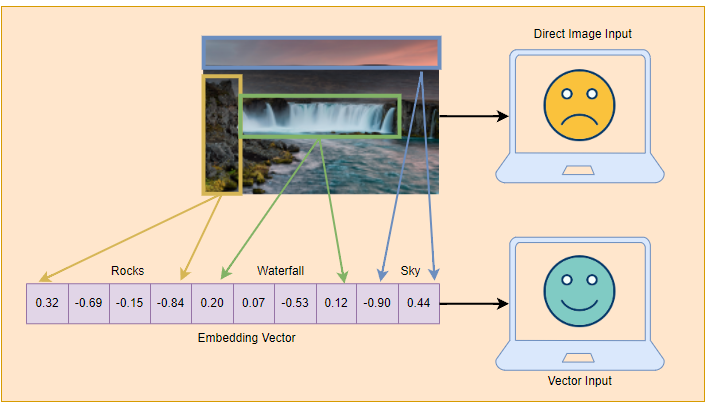
There exists a variety of methodologies especially leveraging deep learning, including convolutional neural networks (CNNs) for visual data like images and Transformers for text data which can be used to transform such unstructured data into embeddings. Zilliz has an excellent article covering different embedding techiques!
Now storing these embedding vectors is not enough. One also needs to be able to query and find out similar vectors. Why do you ask? A majority of real-world applications are powered by vector similarity search for AI-based solutions. This includes visual (image) search in Google, recommendations systems in Netflix or Amazon, text search engines in Google, multi-modal search, data de-duplication, and many more!
Storing, managing, and querying vectors at scale is not a simple task. You need specialized tools for this and vector databases are the most effective tool for the job! In this article we will cover the following aspects:
- Vectors and Vector Similarity Search
- What is a Vector Database?
- Milvus — The World’s Most Advanced Vector Database
- Performing visual image search with Milvus — A use-case blueprint
Let’s get started!
Vectors and Vector Similarity Search
Earlier, we established the necessity of representing unstructured data like images and text as vectors, since computers can only understand numbers. We typically leverage AI models, to be more specific deep learning models to convert unstructured data into numeric vectors which can be read by machines. Typically these vectors are basically a list of floating-point numbers which collectively represent the underlying item (image, text, etc.).
Understanding Vectors
Considering the field of natural language processing (NLP) we have many word embedding models like Word2Vec, GloVe, and FastText which can help represent words as numeric vectors. With advancements over time, we have seen the rise of Transformer models like BERT which can be leveraged to learn contextual embedding vectors and better representations for entire sentences and paragraphs.
Similarly, in the field of computer vision, we have models like Convolutional Neural Networks (CNNs) which can help in learning representations from visual data such as images and videos. With the rise of Transformers, we also have Vision Transformers which can perform better than regular CNNs.
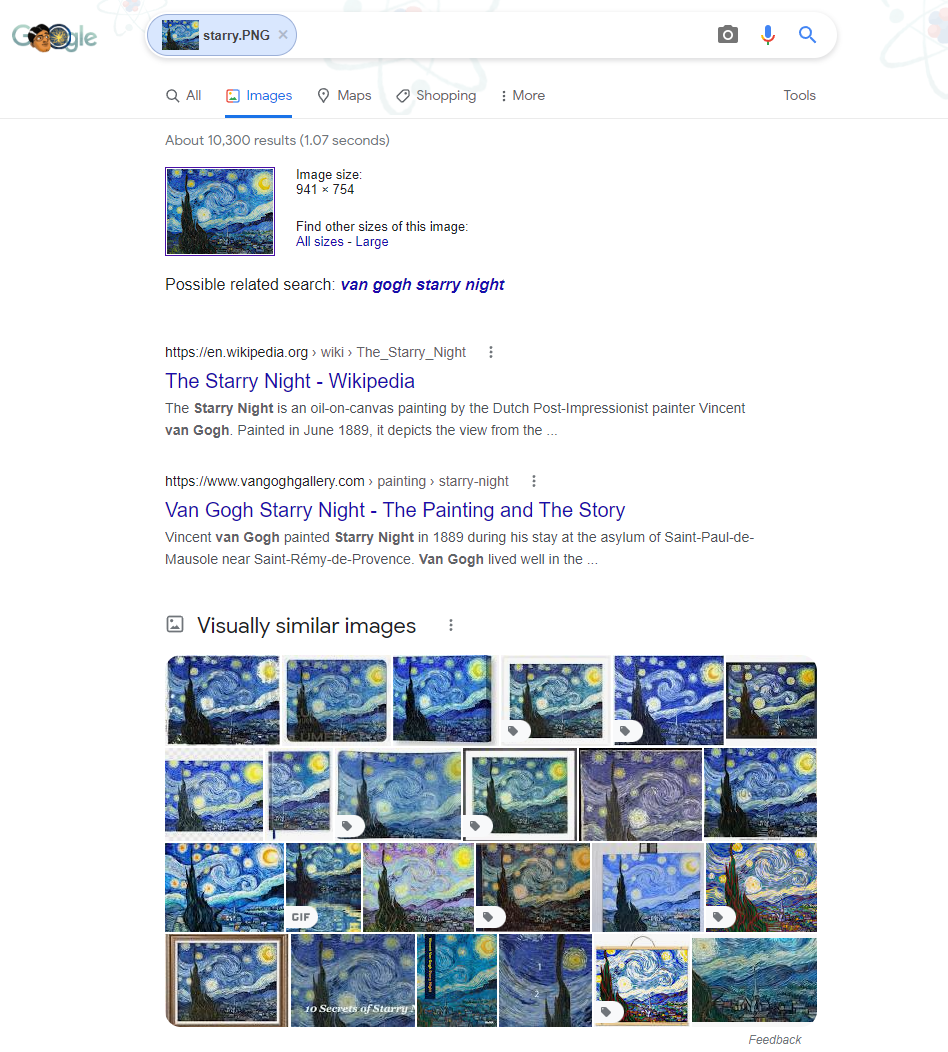
The advantage with such vectors is that we can leverage them for solving real-world problems such as visual search, where you typically upload a photo and get search results including visually similar images. Google has this as a very popular feature in their search engine as depicted in the following example.
Such applications are powered by data vectors and vector similarity search. If you consider two points in an X-Y cartesian coordinate space. The distance between two points can be computed as a simple euclidean distance depicted by the following equation.
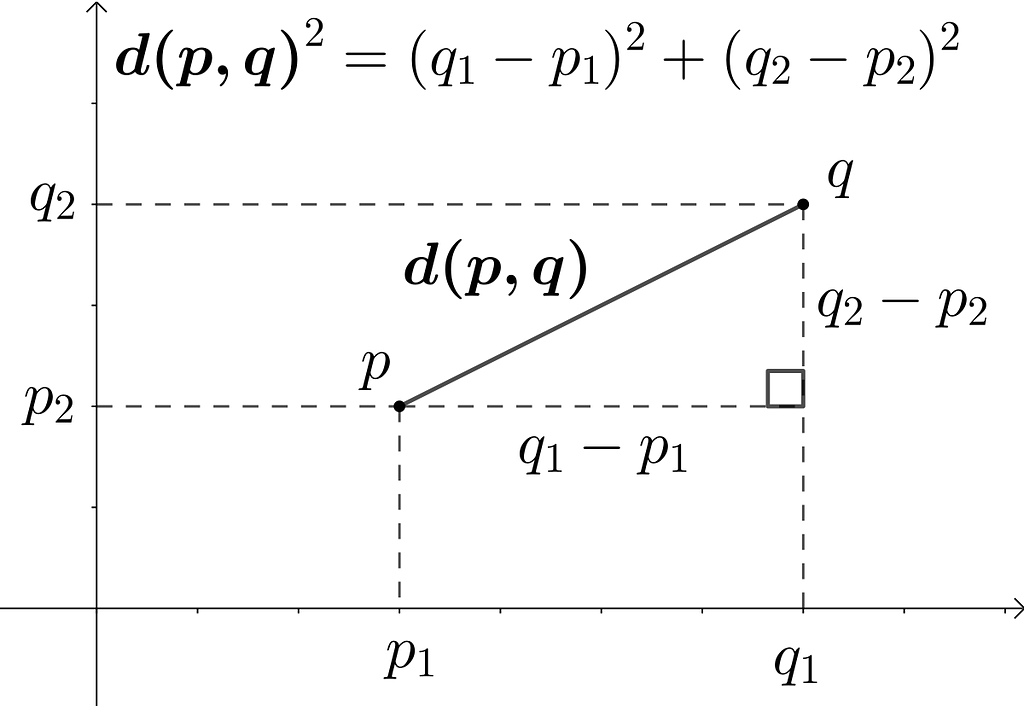
Now imagine each data point is a vector having D-dimensions, you could still use euclidean distance or even other distance metrics like hamming or cosine distance to find out how close the two data points are to each other. This can help build a notion of closeness or similarity which could be used as a quantifiable metric to find similar items given a reference item using their vectors.
Understanding Vector Similarity Search
Vector similarity search, often known as nearest neighbor (NN) search, is basically the process of computing pairwise similarity (or distances) between a reference item (for which we want to find similar items) and a collection of existing items (typically in a database) and returning the top ‘k’ nearest neighbors which are the top ‘k’ most similar items. The key component to compute this similarity is the similarity metric which can be Euclidean distance, inner product, cosine distance, Hamming distance, etc. The smaller the distance, the more similar are the vectors.
The challenge with the exact nearest neighbor (NN) search is scalability. You need to compute N-distances (assuming N existing items) every time to get similar items. This can be super slow especially if you don’t store and index the data somewhere (like a vector database!). To speed up computation, we typically leverage approximate nearest neighbor search which is often called ANN search which ends up storing the vectors into an index. The index helps in storing these vectors in an intelligent way to enable quick retrieval of ‘approximately’ similar neighbors for a reference query item. Typical ANN indexing methodologies include:
- Vector Transformations: This includes adding additional transformations to the vectors like dimension reduction (e.g PCA \ t-SNE), rotation, and so on
- Vector Encoding: This includes applying techniques based on data structures like Locality Sensitive Hashing (LSH), Quantization, Trees, etc. which can help in faster retrieval of similar items
- Non-Exhaustive Search Methods: This is mostly used to prevent exhaustive search and includes methods like neighborhood graphs, inverted indices, etc.
This establishes the case that to build any vector similarity search application, you need a database that can help you with efficient storing, indexing, and querying (search) at scale. Enter vector databases!
What is a Vector Database?
Given that we now understand how vectors can be used to represent unstructured data and how vector search works, we can combine the two concepts together to build a vector database.
Vector databases are scalable data platforms to store, index, and query across embedding vectors that are generated from unstructured data (images, text, etc.) using deep learning models.
Handling a massive number of vectors for similarity search (even with indices) can be super expensive. Despite this, the best and most advanced vector databases should allow you to insert, index, and search across millions or billions of target vectors, in addition to specifying an indexing algorithm and similarity metric of your choice.
Vector databases mainly should satisfy the following key requirements considering a robust database management system to be used in the enterprise:
- Scalable: Vector databases should be able to index and run an approximate nearest neighbor search for billions of embedding vectors
- Reliable: Vector databases should be able to handle internal faults without data loss and with minimal operational impact, i.e be fault-tolerant
- Fast: Query and write speeds are important for vector databases. For platforms such as Snapchat and Instagram, which can have hundreds or thousands of new images uploaded per second, speed becomes an incredibly important factor.
Vector databases don’t just store data vectors. They are also responsible for using efficient data structures to index these vectors for fast retrieval and supporting CRUD (create, read, update and delete) operations. Vector databases should also ideally support attribute filtering which is filtering based on metadata fields which are usually scalar fields. A simple example would be retrieving similar shoes based on the image vectors for a specific brand. Here brand would be the attribute based on which filtering would be done.
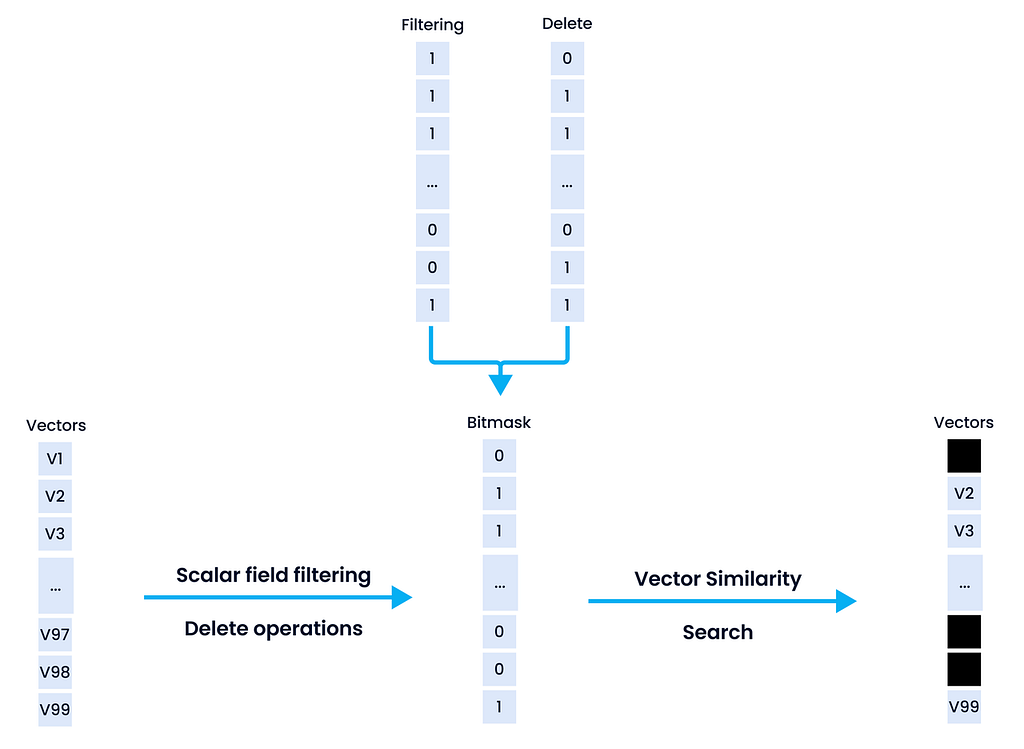
The figure above showcases how Milvus, the vector database we will talk about shortly, uses attribute filtering. Milvus introduces the concept of a bitmask to the filtering mechanism to keep similar vectors with a bitmask of 1 based on satisfying specific attribute filters. More details on this are here.
Milvus — The World’s Most Advanced Vector Database
Milvus is an open-source vector database management platform built specifically for massive-scale vector data and streamlining machine learning operations (MLOps).

Zilliz, is the organization behind building Milvus, the world’s most advanced vector database, to accelerate the development of next-generation data fabric. Milvus is currently a graduation project at the LF AI & Data Foundation and focuses on managing massive unstructured datasets for storage and search. The platform’s efficiency and reliability simplify the process of deploying AI models and MLOps at scale. Milvus has broad applications spanning drug discovery, computer vision, recommendation systems, chatbots, and much more.
Key Features of Milvus
Milvus is packed with useful features and capabilities, such as:
- Blazing search speeds on a trillion vector datasets: Average latency of vector search and retrieval has been measured in milliseconds on a trillion vector datasets.
- Simplified unstructured data management: Milvus has rich APIs designed for data science workflows.
- Reliable, always on vector database: Milvus’ built-in replication and failover/failback features ensure data and applications can maintain business continuity always.
- Highly scalable and elastic: Component-level scalability makes it possible to scale up and down on demand.
- Hybrid search: In addition to vectors, Milvus supports data types such as Boolean, String, integers, floating-point numbers, and more. Milvus pairs scalar filtering with a powerful vector similarity search (as seen in the shoe similarity example earlier).
- Unified Lambda structure: Milvus combines stream and batch processing for data storage to balance timeliness and efficiency.
- Time Travel: Milvus maintains a timeline for all data insert and delete operations. It allows users to specify timestamps in a search to retrieve a data view at a specified point in time.
- Community-supported & Industry recognized: With over 1,000 enterprise users, 10.5K+ stars on GitHub, and an active open-source community, you’re not alone when you use Milvus. As a graduate project under the LF AI & Data Foundation, Milvus has institutional support.
Existing Approaches to Vector Data Management and Search
A common way to build an AI system powered by vector similarity search is to pair algorithms like Approximate Nearest Neighbor Search (ANNS) with open-source libraries such as:
- Facebook AI Similarity Search (FAISS): This framework enables efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It supports indexing capabilities like inverted multi-index and product quantization
- Spotify’s Annoy (Approximate Nearest Neighbors Oh Yeah): This framework uses random projections and builds up a tree to enable ANNS at scale for dense vectors
- Google’s ScaNN (Scalable Nearest Neighbors): This framework performs an efficient vector similarity search at scale. Consists of implementations, which include search space pruning and quantization for Maximum Inner Product Search (MIPS)
While each of these libraries is useful in its own way, due to several limitations, these algorithm-library combinations are not equivalent to a full-fledged vector data management system like Milvus. We will discuss some of these limitations now.
Limitations of Existing Approaches
Existing approaches used for managing vector data as discussed in the previous section have the following limitations:
- Flexibility: Existing systems typically store all data in main memory, hence they cannot be run in distributed mode across multiple machines easily and are not well-suited for handling massive datasets
- Dynamic data handling: Data is often assumed to be static once fed into existing systems, complicating processing for dynamic data and making near real-time search impossible
- Advanced query processing: Most tools do not support advanced query processing (e.g., attribute filtering, hybrid search, and multi-vector queries), which is essential for building real-world similarity search engines supporting advanced filtering.
- Heterogeneous computing optimizations: Few platforms offer optimizations for heterogeneous system architectures on both CPUs and GPUs (excluding FAISS), leading to efficiency losses.
Milvus attempts to overcome all of these limitations and we will discuss this in detail in the next section.
The Milvus Advantage —Understanding Knowhere
Milvus tries to tackle and successfully solve the limitations of existing systems build on top of inefficient vector data management and similarity search algorithms in the following ways:
- It enhances flexibility by offering support for a variety of application interfaces (including SDKs in Python, Java, Go, C++, and RESTful APIs)
- It supports multiple vector index types (e.g., quantization-based indexes and graph-based indexes), and advanced query processing
- Milvus handles dynamic vector data using a log-structured merge tree (LSM tree), keeping data insertions and deletions efficient and searches humming along in real-time
- Milvus also provides optimizations for heterogeneous computing architectures on modern CPUs and GPUs, allowing developers to adjust systems for specific scenarios, datasets, and application environments
Knowhere, the vector execution engine of Milvus, is an operator interface for accessing services in the upper layers of the system and vector similarity search libraries like Faiss, Hnswlib, and Annoy in the lower layers of the system. In addition, Knowhere is also in charge of heterogeneous computing. Knowhere controls on which hardware (eg. CPU or GPU) to execute index building and search requests. This is how Knowhere gets its name — knowing where to execute the operations. More types of hardware including DPU and TPU will be supported in future releases.
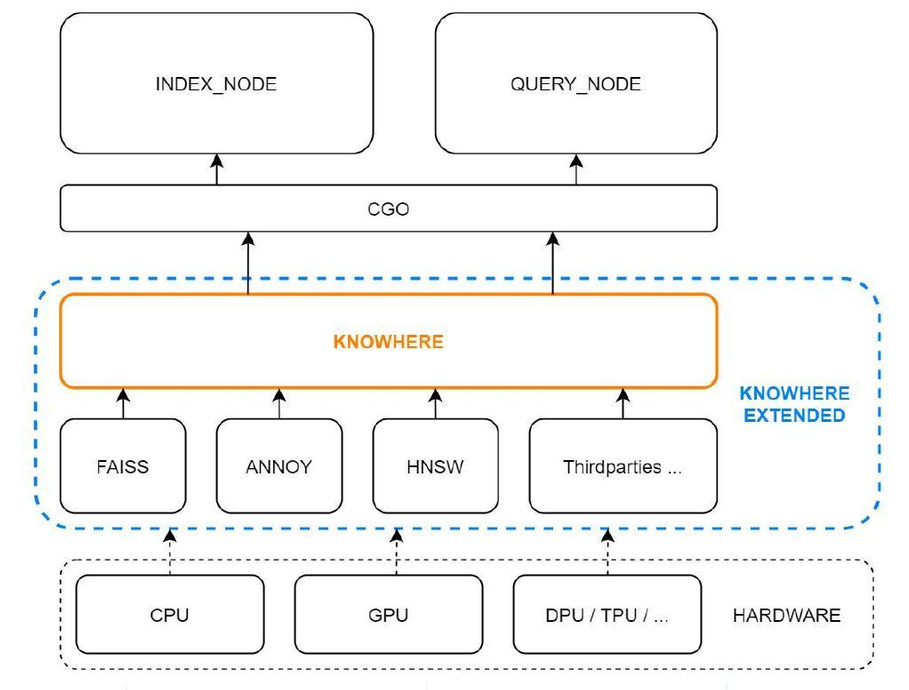
Computation in Milvus mainly involves vector and scalar operations. Knowhere only handles the operations on vectors in Milvus. The figure above illustrates the Knowhere architecture in Milvus. The bottom-most layer is the system hardware. The third-party index libraries are on top of the hardware. Then Knowhere interacts with the index node and query node on the top via CGO. Knowhere not only further extends the functions of Faiss but also optimizes the performance and has several advantages including support for BitsetView, support for more similar metrics, support for AVX512 instruction set, automatic SIMD instruction selection, and other performance optimizations. Details can be found here.
Milvus Architecture
The following figure showcases the overall architecture of the Milvus platform. Milvus separates data flow from control flow and is divided into four layers that are independent in terms of scalability and disaster recovery.
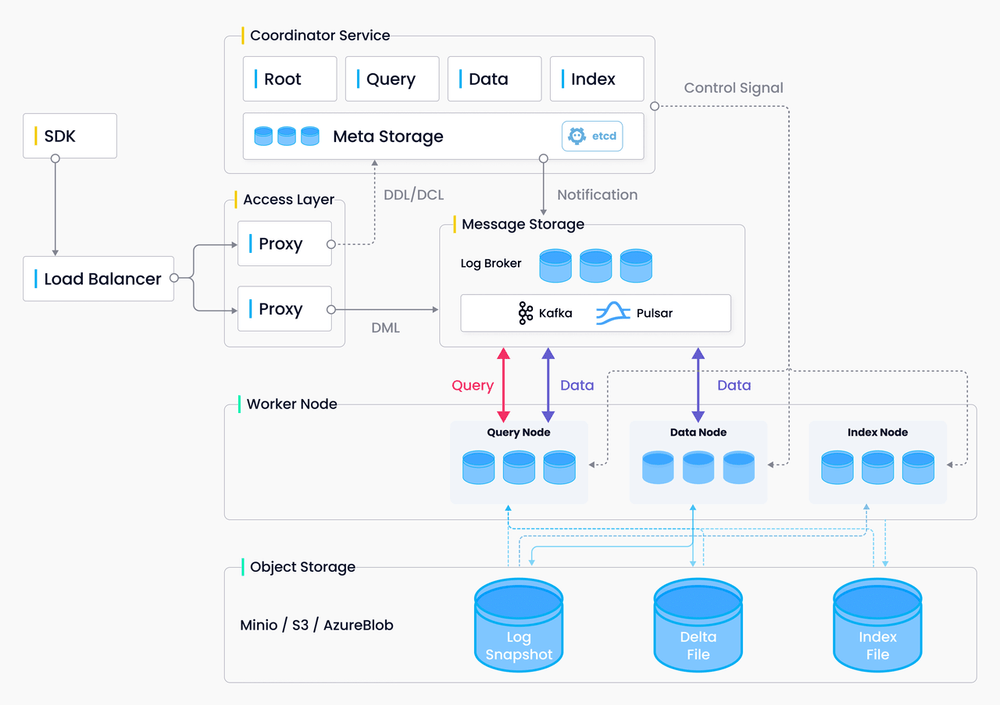
- Access layer: The access layer is composed of a group of stateless proxies and serves as the front layer of the system and endpoint to users.
- Coordinator service: The coordinator service is responsible for cluster topology node management, load balancing, timestamp generation, data declaration, and data management
- Worker nodes: The worker, or execution, node executes instructions issued by the coordinator service and the data manipulation language (DML) commands initiated by the proxy. A worker node in Milvus is similar to a data node in Hadoop, or a region server in HBase
- Storage: This is the cornerstone of Milvus, responsible for data persistence. The storage layer is comprised of meta store, log broker and object storage
Do check out more details about the architecture here!
Performing visual image search with Milvus — A use-case blueprint
Open-source vector databases like Milvus make it possible for any business to create their own visual image search system with a minimum number of steps. Developers can use pre-trained AI models to convert their own image datasets into vectors, and then leverage Milvus to enable searching for similar products by image. Let’s look at the following blueprint of how to design and build such a system.
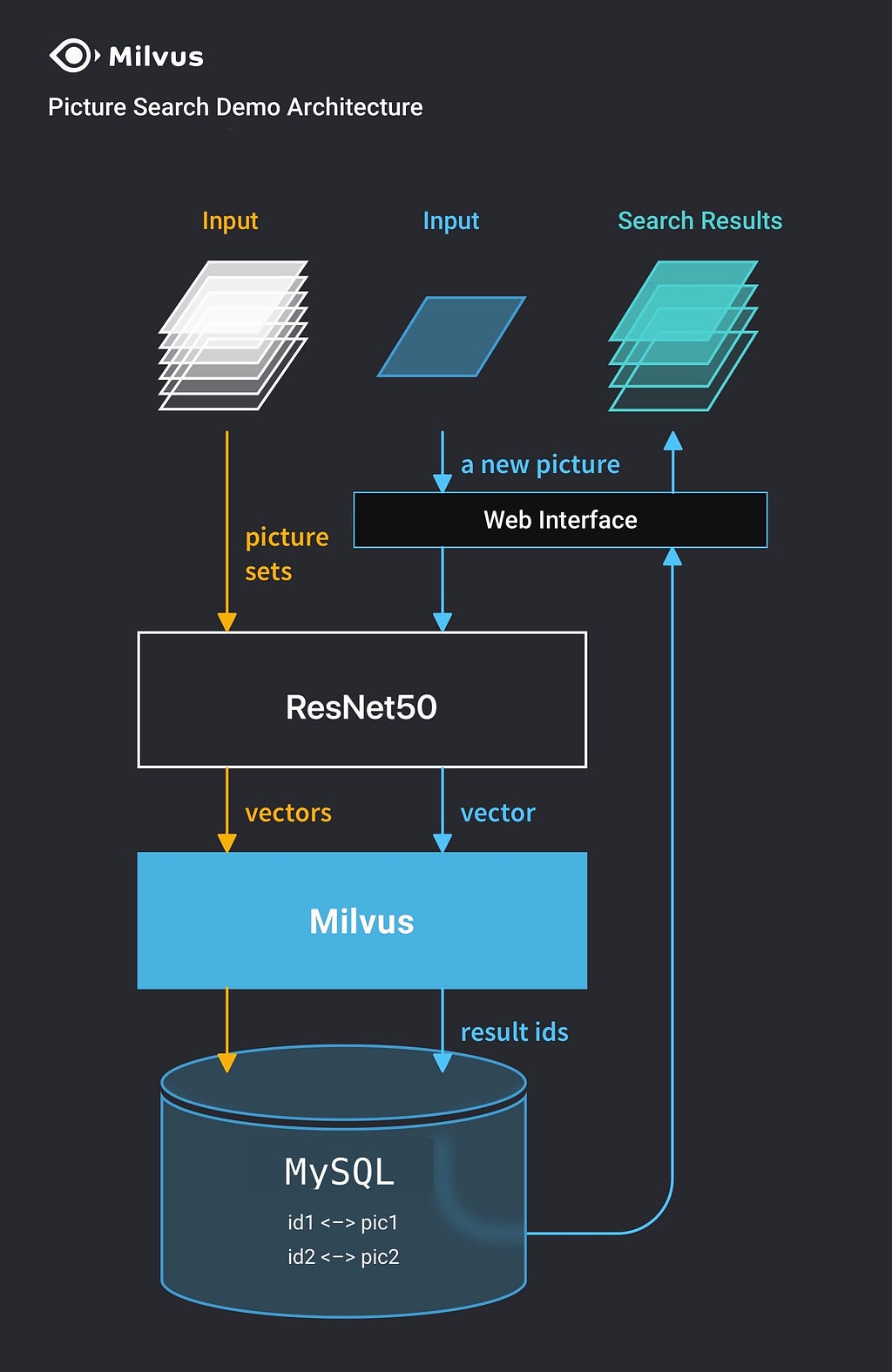
In this workflow, we can use an open-source framework like towhee to leverage a pre-trained model like ResNet-50 and extract vectors from images, store and index these vectors with ease in Milvus and also store a mapping of image IDs to the actual pictures in a MySQL database. Once the data is indexed we can upload any new image with ease and perform an image search at scale using Milvus. The following figure shows a sample visual image search.
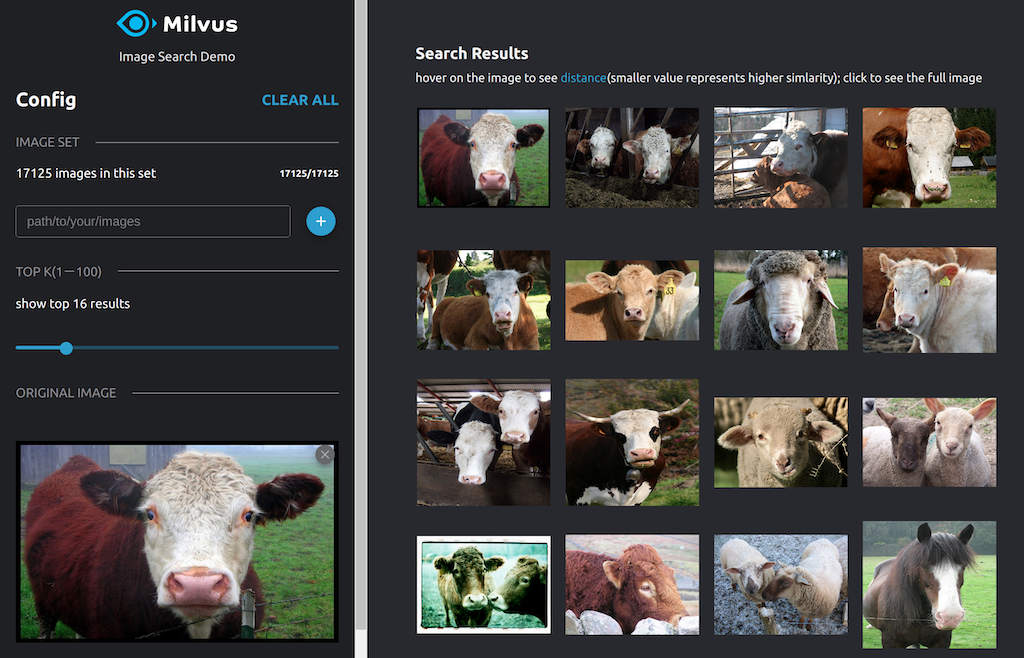
Do check out the detailed tutorial which has been open-sourced on GitHub thanks to Milvus.
Conclusion
We’ve covered a fair amount of ground in this article. We started with challenges in representing unstructured data, leveraging vectors, and vector similarity search at scale with Milvus, an open-source vector database. We discussed details on how Milvus is structured and the key components powering it and a blueprint of how to solve a real-world problem, visual image search with Milvus. Do give it a try and start solving your own real-world problems with Milvus!
The content in this article has been adapted from my article on the Milvus Blog.
Liked this article? Do reach out to me to discuss more on it or give feedback!
Dipanjan Sarkar – Lead Data Scientist – SIT Academy | LinkedIn
Scalable and Blazing Fast Similarity Search With Milvus Vector Database was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.


Recent Posts
")



")


