


NLP Use Case With AWS Comprehend
Last Updated on July 26, 2023 by Editorial Team
Author(s): Shravankumar Hiregoudar
Originally published on Towards AI.
This article covers concepts of Natural Language Processing and how to derive insights from text data using the components of AWS Comprehend.
The topic of discussion!
1. The problem!
2. Basics of AWS Comprehend
3. Sentiment Analysis & Targeted sentiments
4. Topic Modeling
1. The Problem!
Vision
"Accelerate and sustain business outcomes by achieving enterprise change program goals."
How will we achieve our vision?
Mature organizational change capability
Change Capability Defined: The ability of an organization to plan, design, and implement all types of change efficiently while minimizing business disruption, securing stakeholder commitment, and accelerating and sustaining intended business outcomes (financial & cultural).
Let's break the vision down into mini-problems and see how we can address them!
Gain an understanding of:
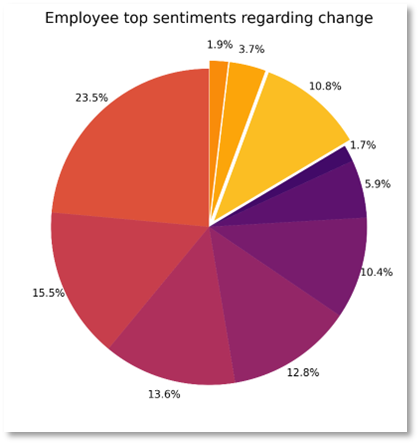
- What are employee sentiments regarding the change in the organization? (How has it impacted them? What do they feel?)
- What is the employee sentiment to our 5 focus areas (leadership, application, standardization, competencies, socialization)
- The pattern of change concerning teams (R&D, Corp, etc.)? What patterns do we see across different teams?
- Top 5–10 sentiments across the board
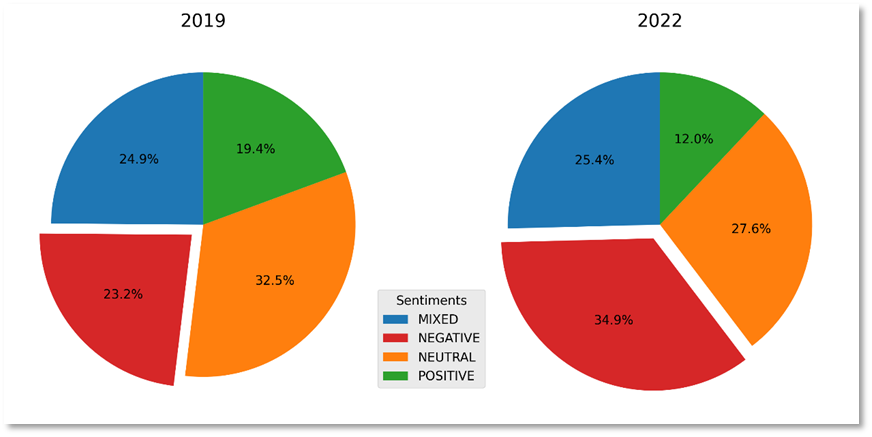
- Impact of change over time (2019 to 2022)
Can we use data?
Yes! We have employee feedback data from 8 quarters. A total of 120,000 records.
Data-Inspired Decision Making
10% (11,000 records) of the employee feedback data was in the context of change even though 'no' questions were asked regarding the change in the org
As the 11,000 records act as the individual voice of the employee, The data was sufficient to perform further analysis!
Approach
Now that we have problem statements and data to inspire some decision-making! We can look over the approach;
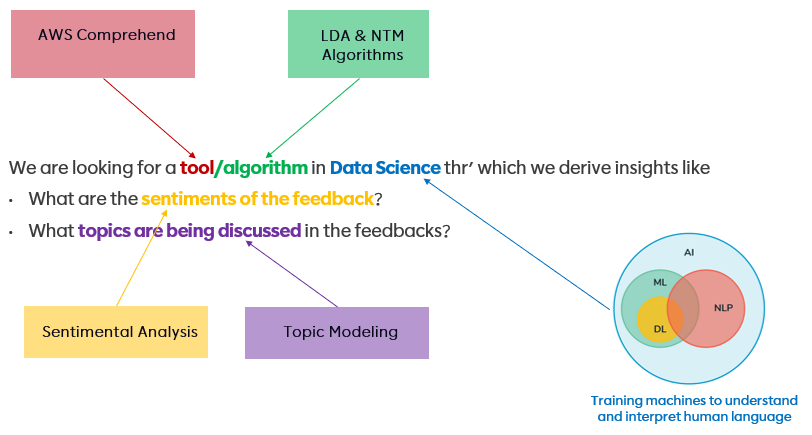
So, we will use AWS comprehend to perform sentimental analysis and topic modeling on the employee feedback data to gain an understanding of sentiments and topics in the context of change!
2. Basics of AWS Comprehend
What is AWS Comprehend?
Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents; in our use case, We use AWS comprehend to extract critical information from our feedback data.
You can use the Amazon Comprehend console or Amazon Comprehend APIs to perform text analysis using Comprehend.
Refer to AWS comprehend documentation
3. Sentiment Analysis & Targeted sentiments

We use Amazon Comprehend to analyze the sentiment of a document. In our use case, you can use sentiment analysis to determine the sentiments of employee feedback on change and whether they like or dislike the change happening in the organization.
Amazon Comprehend supports multiple languages. Note that, All documents in one job must be in the same language.
Sentiment determination returns the following values:
- Positive — The feedback expresses an overall positive sentiment.
- Negative — The feedback expresses an overall negative sentiment.
- Mixed — The feedback expresses a mixed feeling, which is both positive and negative sentiments.
- Neutral — The feedback does not express either positive or negative sentiments.
Targeted sentiment provides a granular understanding of the sentiments associated with specific entities (such as organizations or leadership) in our feedback documents.
One way to perform this is using the UI approach, and we will go a bit deeper into how one can perform this!
Step 1: Visit AWS comprehend home page
Step 2: Under browse section -> Analysis Jobs
Step 3: Create a job
- Name — Give it a unique name like EmpFeedbackSentiV1
- Analysis type — entities, events, key phrases, primary language, personally identifiable information (PII), sentiment, targeted sentiment, or topic modeling.
- Language — The language of the input documents.
- Input data
* Data Source — ‘My documents’
* S3 location —URL of an input data file in S3/ bucket/ folder location in S3.
* Input format — Choose One document per line when you have created a file with each document on a single line. Choose One document per file when each file contains a single document - Output Data — URL of an output data file in S3/ bucket/ folder location in S3.
- Access permissions — Use existing or create one if you don't have one; reasonably straightforward.
- Leave other fields as is
- Hit “Create job.”
The model will run for 2–10 minutes, depending on the input size. Upon completion, You can find the output.tar.gz in your output path. To view the contents, Download and extract the contents of this file using 7 zip.
The output is a JSON structure that you can view better using an online JSON reader. The sample of the output looks like this;
{ "SentimentScore": {
"Mixed": 0.0238794648325487,
"Positive": 0.843765435823298,
"Neutral": 0.0230283082030323,
"Negative": 0.0082836127816313
},
"Sentiment": "POSITIVE",
"LanguageCode": "en" }
The score represents the likelihood that the sentiment was correctly detected. For example, in the example below, it is 85 percent likely that the text has a Positive sentiment. There is a less than 2 percent likelihood that the text has a Negative sentiment. Visualizations can be derived once you refine the JSON.
4. Topic Modeling
You can use Amazon Comprehend to examine the content of a collection of documents to determine common themes. We fed the AWS comprehend with the feedback data, and topics and weights were generated by the AWS comprehend.
Amazon Comprehend uses a Latent Dirichlet allocation-based learning model to determine the topics in a set of documents. It goes through each document to fetch the context and meaning of a word. The words frequently belonging to the same context across the document make up a topic. (Refer to https://docs.aws.amazon.com/comprehend/latest/dg/topic-modeling.html)
After Amazon Comprehend processes, it returns two files, topic-terms.csv and doc-topics.csv.
Output file 1, topic-terms.csv
List of topics in the collection. For each topic, the list includes, by default, the top terms by topic according to their weight.
In our use case, The following to describe the first two topics in the collection:
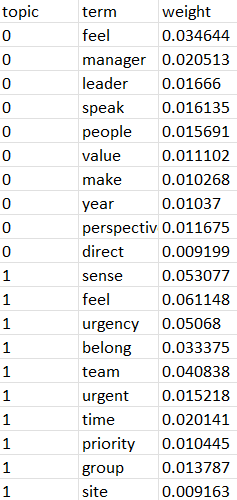
The weights in the table represent a probability distribution over the words in a given topic. It returns only the top 10 words for each topic, the weights won’t sum to 1.0. In the rare cases where there are less than 10 words in a topic, the weights will sum to 1.0.
The words are sorted by their discriminative power by analyzing their frequency across all topics.
You must specify the number of topics to return. For example, If you say 10 topics, it returns the 10 most important topics in the feedback. It can detect a maximum of 100 topics in a collection. The number of topics can be fed based on the document's content, and it’s usually an iterative trial and error method.
Output file 2, doc-topics.csv
Lists the documents associated with a topic and the proportion of the document related to the topic.
In our use case,

Further, Using these two .csv files, You can derive insights, and a simple scatter plot would give you this;
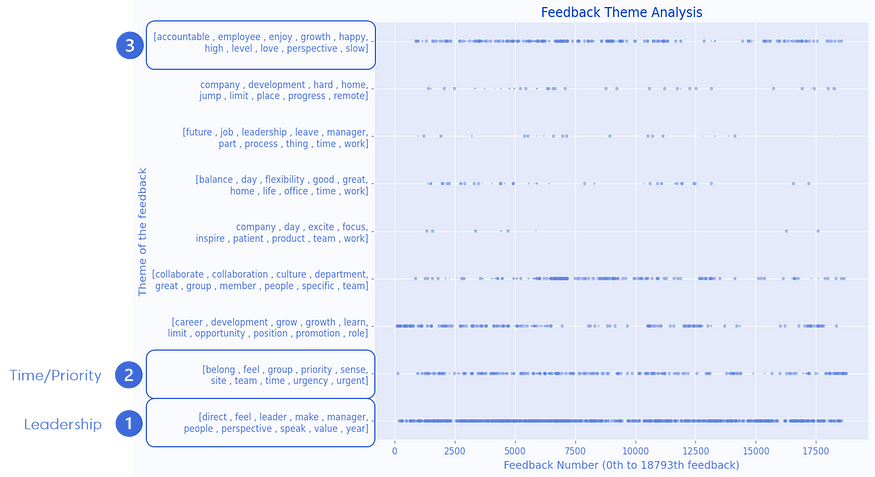
•In the context of change, Some frequently discussed topics were;
1. Highly frequent: direct, feel, leader, manager, people, perspective, speak, value, year (Can be bucketed as Leadership)
2. Moderate: belong, feel, group, priority, sense, site, team, time, urgency, urgent (Can be bucketed as Time/Priority)
Conclusion
Gained an understanding of the sentiments of the employee and topics that were discussed in the context of change!
As a result of the analysis, The team could prioritize the tasks related to improving the existing change management. Improved the application and communication of change
Thank you for reading! Have a fantastic day/night!
Reference
- https://docs.aws.amazon.com/comprehend/latest/dg/what-is.html
- https://docs.aws.amazon.com/comprehend/latest/dg/topic-modeling.html
- https://docs.aws.amazon.com/comprehend/latest/dg/how-sentiment.html
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



