



Chat With Your Healthcare Documents: Build a Chatbot With ChatGPT and LangChain
Last Updated on May 2, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
Interactively query your PDF documents and extract insights.
Did you know that 80% of healthcare data remains unused and unstructured? Traditional applications that rely solely on structured data can only use 20% of the available information, missing out on crucial insights. But with the help of natural language processing and chatbot technology, healthcare professionals can now ask questions and extract insights quickly and efficiently from healthcare PDF documents.
In this blog post, we’ll discuss how to build a chatbot with ChatGPT and LangChain to extract insights from your healthcare documents. By automating the extraction process, healthcare professionals can save time and resources, allowing them to focus on providing better patient care. With the ability to understand natural language, ChatGPT can provide accurate and relevant information to users. ChatGPT APIs extracts key information from PDF documents, providing structured data that can be analyzed to extract insights. Don’t miss out on the valuable insights hidden in your unstructured healthcare data — build a chatbot with ChatGPT and LangChain today!
Table of contents
What is the application that we are developing?
What is Adverse Drug Reaction (ADR)
What kind of answers are healthcare professionals seeking from the ADR report?
Document used to test this chatbot application?
Before you proceed
Brief summary of technologies used and how the app works
Packages to install
Load the document in to vector store
Build the Web Interface
Pass the question and query the document
Display search results in a chat format
Display chat history
Summary of what was built
Conclusion
What is the application that we are developing?
Chatbots are an effective way to extract insights from healthcare PDF documents because they provide a more interactive and conversational experience than traditional methods. With ChatGPT, the chatbot can understand natural language and provide more accurate and relevant information to the user.
In this article, we will build out a chatbot that will query your healthcare documents and answer questions. The following picture shows what the app will look like. To illustrate this process, I will use an Adverse Drug Reaction report as an example and demonstrate how Chatbot can be used to read and extract insights from this ADR document and answer questions iteratively.
What is Adverse Drug Reaction (ADR)
An Adverse Drug Reaction (ADR) is any harmful, unintended or unwanted effect of a medication or drug that occurs at doses normally used for treatment, diagnosis, or prevention of diseases. ADRs can range from mild side effects such as dizziness or nausea to severe or life-threatening reactions like anaphylaxis. ADRs are a significant concern in healthcare and are closely monitored by healthcare professionals to ensure that medications are used safely and effectively.
Adverse Drug Reactions (ADRs) are reported in clinical trials through Pharmacovigilance, which involves monitoring, detecting, and evaluating adverse drug reactions to ensure medication safety and efficacy. Clinical trial participants are closely monitored for any adverse reactions, and any adverse events are documented and reported to the clinical trial sponsor or regulatory authorities. This information is used to evaluate the safety and efficacy of the medication and make necessary adjustments. Clinical trial sponsors also provide updates on ADRs to regulatory authorities as part of post-marketing surveillance.
What kind of answers are healthcare professionals seeking from the ADR report?
Typical questions to get answers from an Adverse Drug Reaction (ADR) report include:
- What is the name and dose of the drug(s) involved in the ADR?
- What is the patient’s age, gender, and medical history?
- What are the symptoms experienced by the patient as a result of the ADR?
- What was the outcome of the ADR, including any medical intervention required?
- Was the ADR expected or unexpected based on the known side effects of the drug?
- Was the ADR related to the drug or caused by another factor?
- What action was taken to manage or prevent the ADR from occurring again?
- What is the severity of the ADR, and is it considered serious or life-threatening?
- Has the ADR been previously reported, and if so, what was the outcome of previous reports?
- Are there any other factors that may have contributed to the ADR, such as the patient’s lifestyle or other medications being taken?
Document used to test this chatbot application?
This application can point to any healthcare document(s). It can be in text or pdf format. For the purpose of the chatbot to ask questions and extract information about an Adverse Event, I will use a PDF file that has the following text. It is important to note that this report is anonymous, and no personal identifying information is included.
Introduction:
Adverse events (AEs) are unwanted or harmful effects that occur in patients during clinical trials. AEs can range from mild to severe and can impact patient safety, study outcomes, and regulatory approval. This report describes a case of a serious adverse event observed in a phase I clinical trial of a new medication for the treatment of advanced solid tumors.
Case Description:
The patient, a 42-year-old female with metastatic breast cancer, was enrolled in the phase I clinical trial and received the study medication at a dose of 500 mg once daily. The patient had a significant medical history, including a previous diagnosis of hepatitis B and C, but her liver function tests were normal at the time of enrollment. The patient was also taking several other medications, including tamoxifen and levothyroxine.
On day 7 of treatment, the patient reported severe abdominal pain, nausea, and vomiting. The patient's vital signs were stable, but a physical examination revealed diffuse abdominal tenderness. Laboratory testing revealed elevated liver enzymes, total bilirubin, and international normalized ratio (INR). A CT scan of the abdomen showed evidence of hepatic necrosis.
Investigations:
The patient was admitted to the hospital for further evaluation and management. The study medication was discontinued, and the patient was started on supportive care, including intravenous fluids, pain management, and nutritional support. Further investigations, including a liver biopsy, confirmed the diagnosis of drug-induced liver injury.
Discussion:
Drug-induced liver injury is a known adverse effect of many medications, including some chemotherapeutic agents. The incidence of drug-induced liver injury is higher in patients with pre-existing liver disease or those taking other medications that affect the liver. In this case, the patient developed severe drug-induced liver injury shortly after starting the study medication. The patient had a history of hepatitis B and C, which may have predisposed her to liver injury. Additionally, the patient was taking several other medications, which may have contributed to the development of liver injury.
Conclusion:
This case illustrates a serious adverse event that occurred during a phase I clinical trial of a new medication for the treatment of advanced solid tumors. The patient developed severe drug-induced liver injury, likely related to the study medication. Clinicians and investigators involved in clinical trials must be vigilant for potential adverse events, especially in the early phases of drug development. Prompt recognition and management of adverse events are essential to prevent further harm and improve patient outcomes. In this case, the study medication was discontinued, and the patient received supportive care. The patient's liver function gradually improved over several weeks, and she was able to resume treatment for her metastatic breast cancer.
However, this case also raises important questions about the inclusion criteria for phase I clinical trials and the potential risks associated with enrolling patients with pre-existing medical conditions or those taking other medications. The patient in this case had a history of hepatitis B and C, which may have increased her risk of developing drug-induced liver injury. The patient was also taking several other medications, which may have contributed to the development of liver injury.
In order to mitigate the risk of adverse events in phase I clinical trials, it may be necessary to develop more rigorous inclusion and exclusion criteria that take into account the potential risks associated with pre-existing medical conditions or concomitant medications. Additionally, close monitoring of patients during clinical trials, including regular laboratory testing and imaging studies, may be necessary to ensure the early detection and management of adverse events.
In conclusion, adverse events are an inherent risk of clinical trials, especially in the early phases of drug development. Clinicians and investigators must remain vigilant for potential adverse events and take steps to mitigate the risks associated with enrolling patients with pre-existing medical conditions or those taking other medications. Prompt recognition and management of adverse events are essential to prevent further harm and improve patient outcomes. The importance of patient safety cannot be overemphasized, and all efforts must be made to minimize the risks associated with clinical trials.
In addition to rigorous inclusion and exclusion criteria and close monitoring of patients during clinical trials, it may also be necessary to consider alternative trial designs, such as adaptive designs or Bayesian approaches, which allow for greater flexibility in the trial design and can potentially reduce the risk of adverse events. These trial designs can be particularly useful in the early phases of drug development when there is limited information on the safety and efficacy of the drug.
Furthermore, the reporting and analysis of adverse events in clinical trials are essential to improving patient safety and informing future drug development. All adverse events should be promptly reported to the study sponsor and regulatory authorities, and a thorough analysis of the data should be conducted to identify any potential trends or patterns. This analysis can help to identify potential risk factors for adverse events and inform future trial designs or inclusion and exclusion criteria.
In conclusion, adverse events are an inherent risk of clinical trials, and clinicians and investigators must remain vigilant for potential adverse events and take steps to mitigate the risks associated with enrolling patients with pre-existing medical conditions or those taking other medications. The reporting and analysis of adverse events are essential to improving patient safety and informing future drug development. Despite the challenges associated with clinical trials, they remain an essential component of drug development and are necessary to bring new treatments to patients in need.
Before you proceed
If you want to try out the code below, before you proceed below, you should have the following done.
- Install VS code (or some code editor)
- Install Python
- Install relevant extensions in your code editor
- Signed up with OpenAI
- Created an API Key
- Install openai library
- Install Langchain (pip install langchain)
- Install streamit (pip install streamit)
- Install pypdf (pip install pypdf)
All these steps are documented in length here with detailed instructions and examples.
Brief summary of technologies used and how the app works
LangChain is a framework that allows you to build advanced applications powered by large language models (LLMs). It provides a standard interface to connect different components such as LLMs, data sources, and actions. LangChain makes it easier and faster to build powerful applications with features like chaining, data awareness, and agentic capabilities.
The web application is built with Streamlit. Streamlit is an open-source Python library to create interactive web applications and data dashboards. It simplifies the process of building user-friendly web apps with minimal effort, making it popular among developers, data scientists, and machine learning engineers.
The steps include
Front End
- User enters a question in the UI
- Question is sent to the backend application.
- Backend application queries the document and retrieves the answer
- Answer is sent and displayed in the UI
Backend
- Use Langchain loaders to read the ADR PDF document
- Load the document in to a vector database
- Get the question from the user
- Get relevant chunks from the document related to this question
- Send the relevant chunks and the question to OpenAI (LLM)
- Send the answer to the UI (Streamlit)
Packages to install
Install OpenAI, LangChain and StreamLit
pip install openai
pip install langchain
pip install streamit
Import the relevant packages
# Imports
import os
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
import streamlit as st
from streamlit_chat import message
Set the API keys
# Set API keys and the models to use
API_KEY = "Your OpenAI API Key goes here"
model_id = "gpt-3.5-turbo"
# Add your openai api key for use
os.environ["OPENAI_API_KEY"] = API_KEY
Load the document in to vector store
The VectorstoreIndexCreator class is a utility in Langchain for creating a vectorstore index, which stores vector representations of documents. Vector representations allow for various operations on text, like finding similar documents or answering questions about the text.
# Load PDF document
# Langchain has many document loaders
# We will use their PDF load to load the PDF document below
loaders = PyPDFLoader('docs/ADR11.pdf')
# Create a vector representation of this document loaded
index = VectorstoreIndexCreator().from_loaders([loaders])
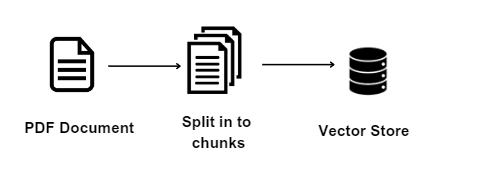
This is very useful because, instead of sending your entire document to OpenAI, you can find document chunks that are relevant to your question and send those chunks along with the question to OpenAI to minimize the amount of text you have to send to save costs.
Now the document is ready for query.
Build the Web interface
We set up the streamlit app page by providing a title and a text box for the user to ask questions.
# Setup streamlit app
# Display the page title and the text box for the user to ask the question
st.title('U+1F99C Query your PDF document ')
prompt = st.text_input("Enter your question to query your PDF documents")
When the user enters their question, it will be stored in the variable prompt so it can be used to query LLM.
Now your basic app is ready

Now we have to wire this to LLM to get the answer from the PDF and send it to the UI.
Pass the question and query the document
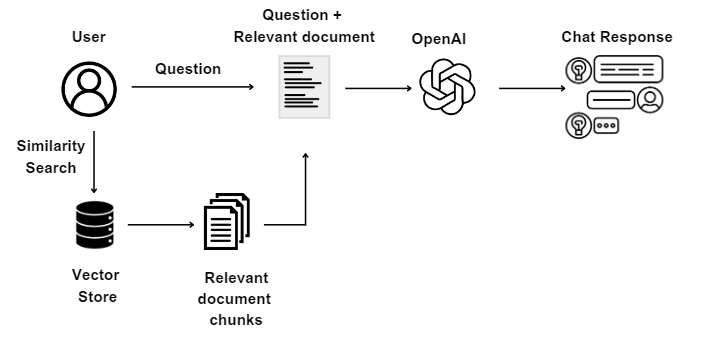
When the user enters a question in the UI, the next step is to do the following.
- Take the question and pass it to the vector index
- Find similar chunks of data relevant to the question from the vector representation
- Send the question and the chunks to OpenAI to find the answer
- Display the answer in the UI. Notice that we use little bit of HTML to format the answer below
# Display the current response. No chat history is maintained
if prompt:
# Get the resonse from LLM
# We pass the model name (3.5) and the temperature (Closer to 1 means creative resonse)
# stuff chain type sends all the relevant text chunks from the document to LLM
response = index.query(llm=OpenAI(model_name="gpt-3.5-turbo", temperature=0.2), question = prompt, chain_type = 'stuff')
# Write the results from the LLM to the UI
st.write("<b>" + prompt + "</b><br><i>" + response + "</i><hr>", unsafe_allow_html=True )
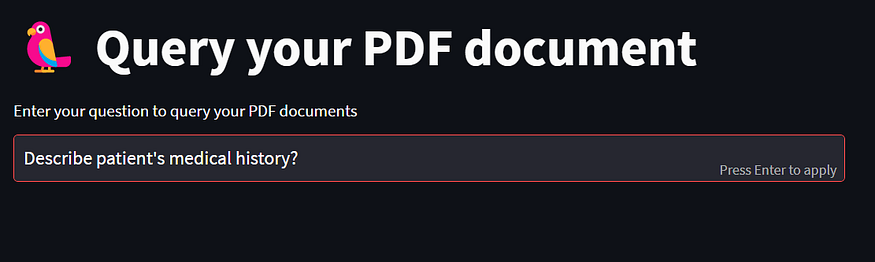
- Open web app

2. Enter the question to query the ADR document
3. It queries the document and generates the answer and displays the answer on the screen

Ask a different question
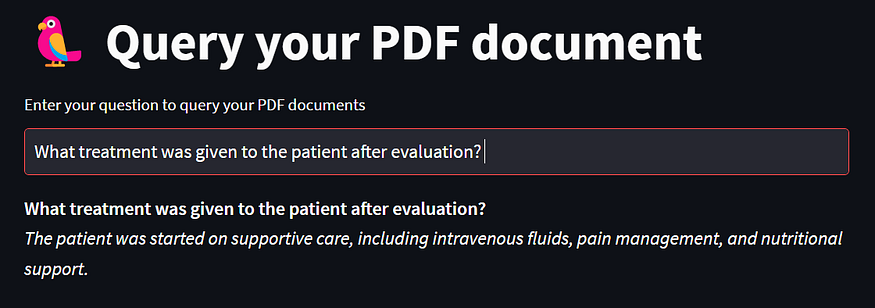
If you notice the previous question / answer is no longer visible. New question and the answer is displayed. Won’t it be good to display in a chat format and include the chat history as well in there?
Display search results in a chat format
Here the goal is to keep the previous questions/answers and add the new question/answer at the top in a chat format. For that, we use the message component in streamlit. Let's first make it look like a chat interface, and then we can add the chat history. We will use the message component to make it look like a chat interface.
if prompt:
# Get the resonse from LLM
# We pass the model name (3.5) and the temperature (Closer to 1 means creative resonse)
# stuff chain type sends all the relevant text chunks from the document to LLM
response = index.query(llm=OpenAI(model_name="gpt-3.5-turbo", temperature=0.2), question = prompt, chain_type = 'stuff')
# Write the results from the LLM to the UI
# Display the response in a message format
# User input will appear on the right which is controlled by the property is_user=True
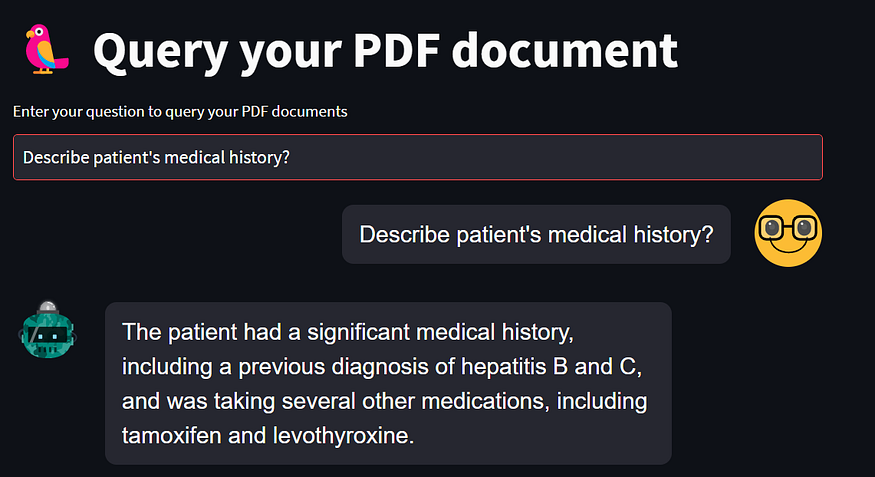
message(prompt, is_user=True)
message(response,is_user=False )
Here is the output. User input will appear on the right which is controlled by the property is_user=True. Note that when user asks a new question, that will erase the previous question. We will fix that next.
Display chat history
The next step is to add the chat history, so when the user asks a new question, the previous answers are also shown below.
Step 1 is to save the history so it can be displayed. The question and the corresponding answers are saved in a list.
#------------------------------------------------------------------
# Save history
# This is used to save chat history and display on the screen
if 'answer' not in st.session_state:
st.session_state['answer'] = []
if 'question' not in st.session_state:
st.session_state['question'] = []
Every time a new question is asked, the question and the corresponding answers are inserted at the top of the list, and the list is displayed in the message box. Since the latest question is inserted at the top, history appears at the bottom.
#------------------------------------------------------------------
# Display the current response. Chat history is displayed below
if prompt:
# Get the resonse from LLM
# We pass the model name (3.5) and the temperature (Closer to 1 means creative resonse)
# stuff chain type sends all the relevant text chunks from the document to LLM
response = index.query(llm=OpenAI(model_name = model_id, temperature=0.2), question = prompt, chain_type = 'stuff')
# Add the question and the answer to display chat history in a list
# Latest answer appears at the top
st.session_state.question.insert(0,prompt )
st.session_state.answer.insert(0,response )
# Display the chat history
for i in range(len( st.session_state.question)) :
message(st.session_state['question'][i], is_user=True)
message(st.session_state['answer'][i], is_user=False)
First question is shown below.
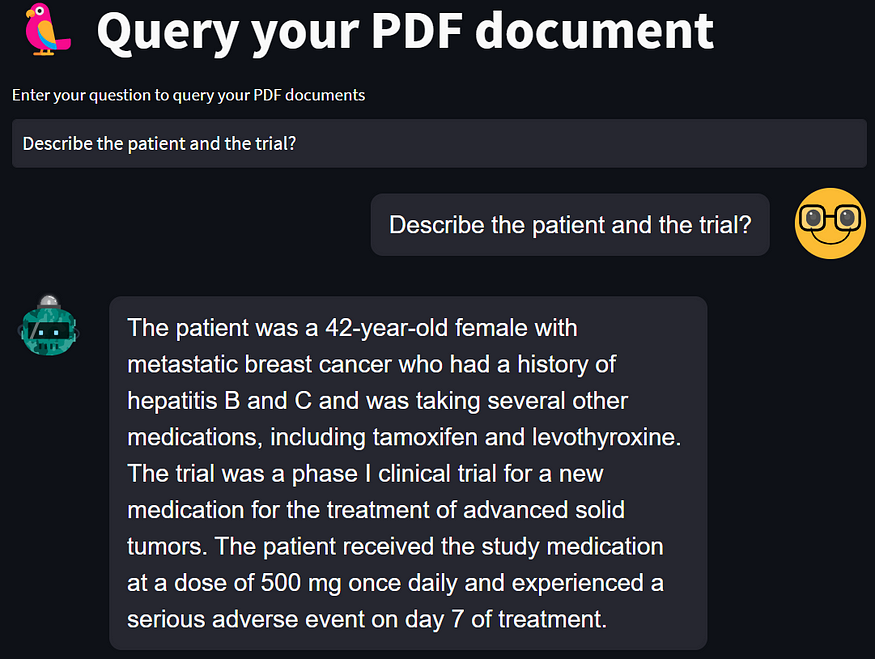
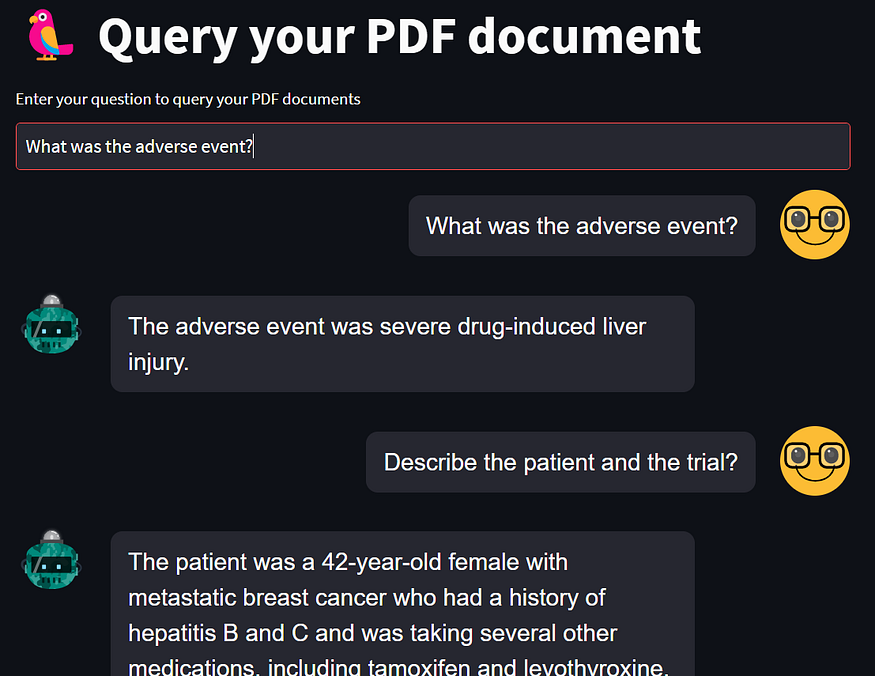
The second question is asked, and it shows at the top, while the 1st question appears in the chat history.
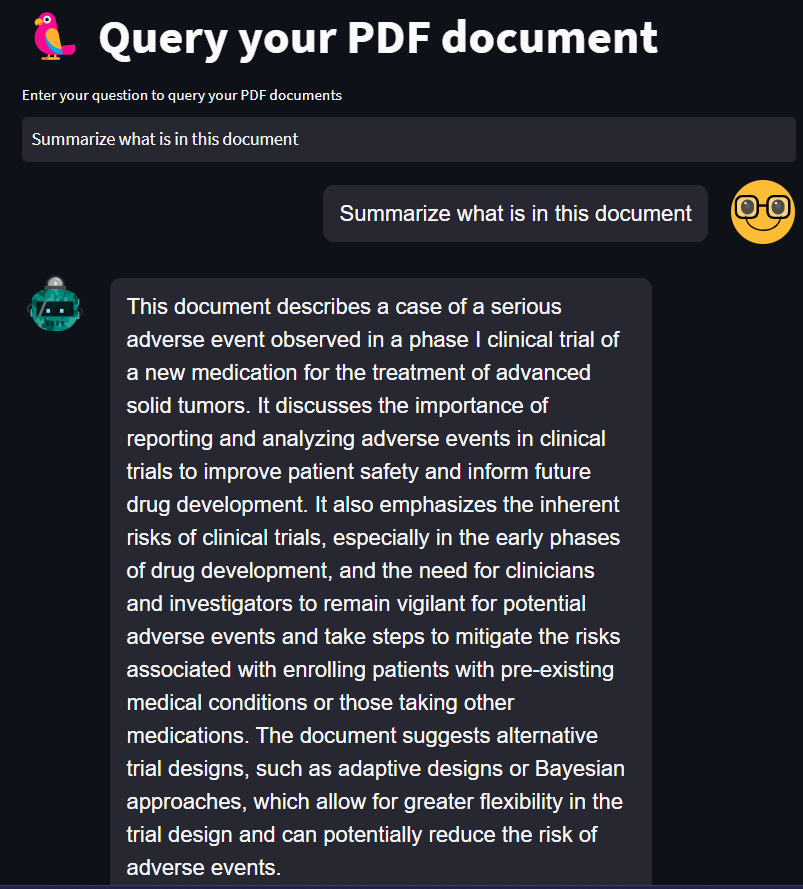
We can also summarize what is in the document.
Summary of what was built
We have accomplished what we started. This is a quick summary of what we built above
- The user enters a question in the Web UI, which was built using Streamlit
- Document(s) to query is initially split into chunks and saved in the vector store
- When the question from the user comes, we lookup for relevant chunks from the vector store
- The question, along with the document chunks, are sent to OpenAI
- OpenAI responds back with a response, and this is displayed in the UI
- We used a message component to format it like a chat
It is essential to acknowledge that the example presented in this article utilized anonymous data. In real-life situations, it is crucial to obtain the necessary security permissions before using confidential patient information.
Conclusion
In conclusion, building a chatbot with ChatGPT can enable the extraction of valuable insights from healthcare documents. With the ability to understand natural language, ChatGPT can provide healthcare professionals with relevant and timely information, answer their questions, and facilitate decision-making. By leveraging the power of AI and natural language processing, healthcare organizations can streamline their operations, improve patient outcomes, and ultimately enhance the quality of care they provide.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


