



Tabular Classification and Regression Made Easy with Lightning Flash
Last Updated on November 25, 2021 by Editorial Team
Author(s): イルカ Borovec
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Machine Learning
This post presents solving Tabular primary data via the two most common Machine Learning (ML) tasks — classification and regression, with Lightning Flash, which makes it very simple.
When it comes to articles on deep learning, advances in Computer Vision or Natural Language Processing (NLP) receive the lion's share of the attention. Advancement in CV and NLP is fantastic and super exciting; however, many data scientists' day-to-day tasks revolve around tabular data processing.
Tabular data classification and regression are essential tasks. They are often modeled with classical methods such as Random Forests, Support Vector Machines, Linear/Logistic Regressions, and Naive Bayes, implemented in one of many standard libraries — scikit-learn, XGBoost, etc.
Still, it is beneficial to experiment with newer Deep Learning methods to model with more complex data.
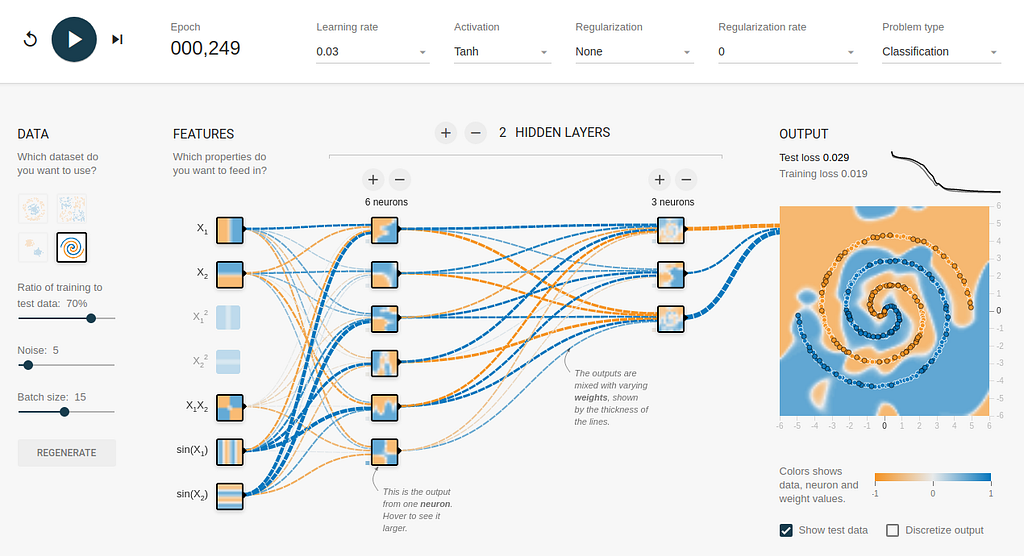
In this post, we present how to prepare data and train models with just a few lines of code using Lightning Flash.
This open-source AI Factory built on top of PyTorch Lightning provides out-of-box solutions for several domains such as tabular, image, text, etc., and all basic tasks. We showcase the solution on two simple Kaggle competitions (and link particular kernels below):
- Tabular classification with Titanic dataset, see docs example
🚢Titanic crash with Lightning⚡Flash
- Tabular regression with House pricing dataset, see docs example
🏠House 💵prices predictions with Lightning⚡Flash
In the following sections, I will walk through the four stages (plus two bonuses) of tabular modeling, including:
1. Data preparation
2. Model creation
3. Training model
4. Evaluation/Inference
The Lightning Flash API unifies a variety of data loadings and tasks, ensuring that classification and regression code is similar and easy to read.
1. Data Preparation
Data preparation, in general, is a broad subject, so let us narrow it down for this tutorial. For this post, we will use the House pricing dataset.
We assume that the data is clean and has been checked for the task we are solving. For classification, the prediction is a positive discrete value mapping to pre-defined labels. For regression, the forecast is a floating-point value without any bounds.
The initial step of any training pipeline is loading the data and identification of the data (per column) types. We need to differentiate between the continuous and categorical inputs. The continuous (numerical) values are exemplary, but the categorical (primarily strings) need to be converted to numerical with some internal mapping.
Don't worry. All of this is done inside Flash! As a user, you do not need to think about it unless you want to.
When you sort numerical and categorical inputs, you can cast them manually or use some heuristic/statistic to infer the type.

Next, we create a DataModule using the from_csv method. To do so, we specify the input CSV file, set the batch size for training and train/validation split, the numerical and categorical columns we want to use as features, and the target column we want to predict.
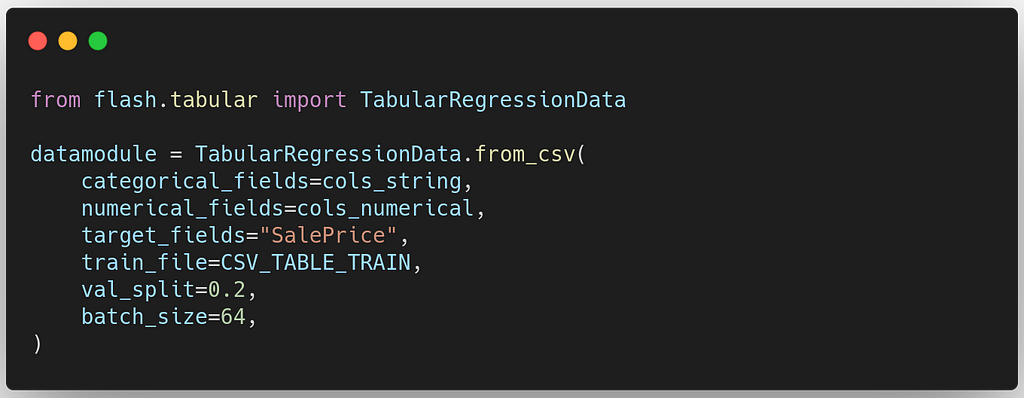
2. Model creation
The next step is creating the task model. In this case, we will create a Tabular regression model in which we provide our DataModule, in addition, to a few other model-specific properties, such as optimizer and learning rate.
3. Training the model
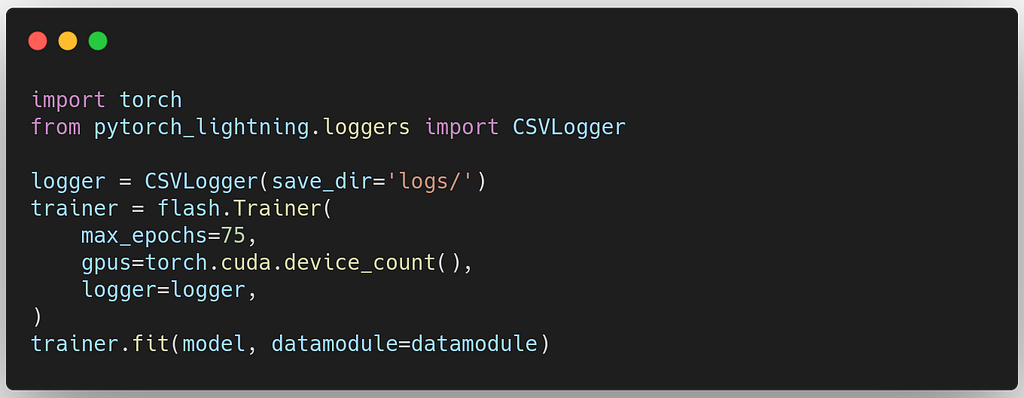
Training a model is usually a very complex task, but Lightning Flash makes it straightforward. Since Flash is powered by PyTorch-Lightning (PL), you can leverage all PL callbacks and features to train your model.
In this case, we will use a CSV logger to conveniently plot training statistics to the IPython notebook.
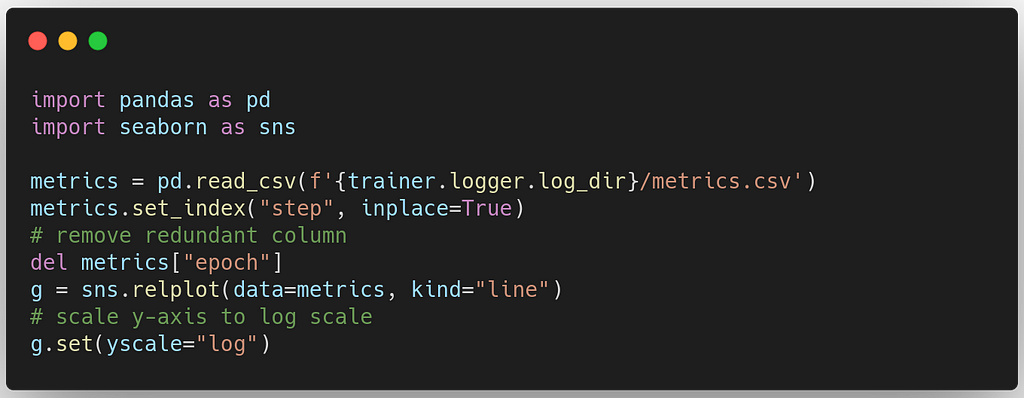
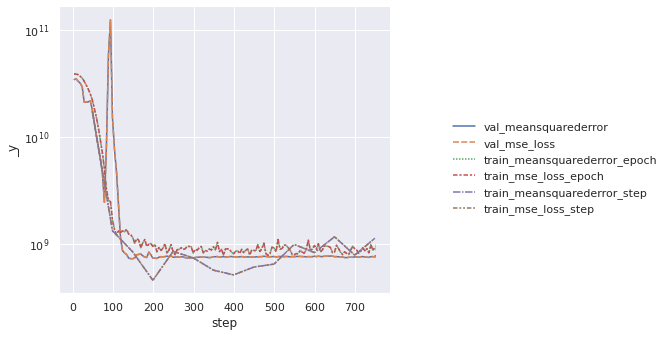
When training is done, we plot all metrics and losses collected during the process with seaborn package:
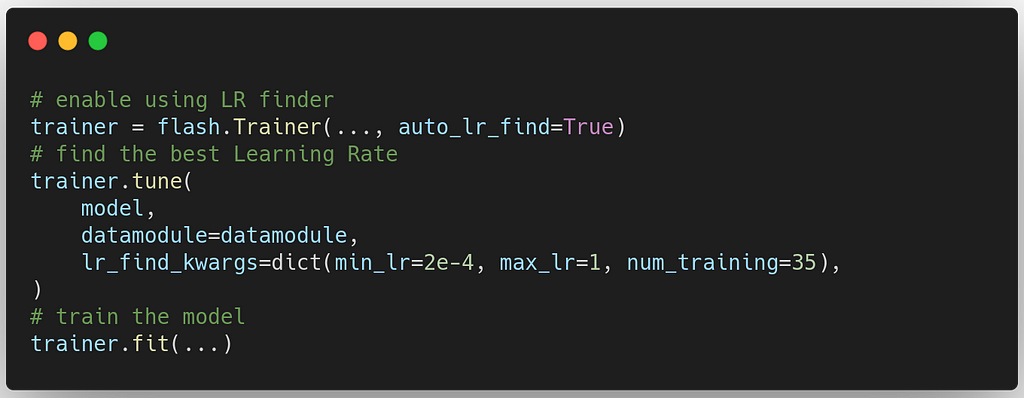
If you do not know the best learning rate for your model/data, you can use the PyTorch Lightning learning rate finder. You need to enable LR in Trainer, and before fit method call the tune method:
When you run this code, you should see training curves similar to the image below that show that your model is converging and learning.
4. Model Inference
The final part of tabular modeling is inferencing on new data. Once again, Flash makes it straightforward to infer as the model remembers what columns were used during training and separated between numerical and categorical columns.
We pass a loaded table or a path to the CSV file we want to evaluate, and FFlash will give us model predictions:
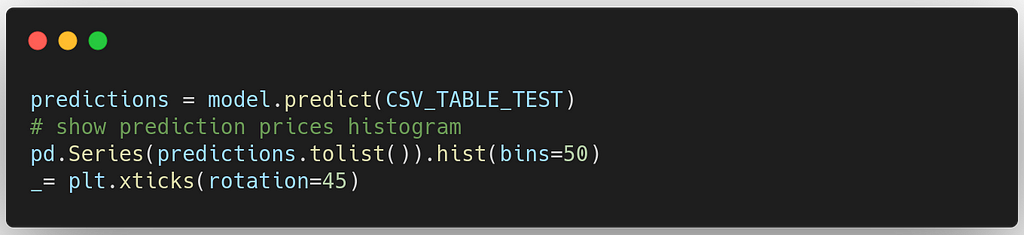
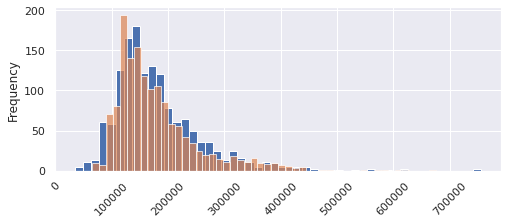
Let's see what the prediction prices distribution is:
Next Steps
Flash Zero for Zero Code CLI Training
Flash Zero is a zero-code machine learning extension of Lightning Flash, which offers Lightning Flash functionality without requiring a single line of a python script.
Flash zero is useful for fast prototyping and hyperparameter searches that define an external loop over given options or a cloud platform such as grid.ai.
HyperParameter Optimization with Grid.ai and No Code Change
Let's demonstrate Flash Zero on another simple Tabular classification task from Kaggle — Tabular Playground Series — Nov 2021.
Playing 📋tabular with Lightning⚡Flash
In this case, we will replace the python training script we wrote about, which consecutively created data, model, and trainer:
With a single CLI call:
flash tabular_classification \
--model.learning_rate=0.01 \
--model.optimizer="AdamW" \
--trainer.max_epochs 20 \
--trainer.accumulate_grad_batches=12 \
--trainer.gradient_clip_val=0.1 \
from_csv \
--train_file=/home/jirka/Downloads/train.csv \
--numerical_fields="['f0', 'f1', ..., 'f99']" \
--target_fields="target"
--batch_size=512
In the end, we can browse training progress with TesorBoard as it is also the default Lightning Flash logger:
tensorboard --logdir ./lightning_logs
Tabular forecasting of time-series data
Recently Lightning Flash also introduced tabular forecasting with time series, which we showcase on actually running competition predicting Crypto value target values.
The ongoing Kaggle kernel with crypto demo can be found here:
🪙Crypto 📈forecasting with Lightning⚡Flash
Are you interested in more cool PyTorch Lightning integrations?
Follow me and join our fantastic Slack community!
About the Author
Jirka Borovec holds a Ph.D. in Computer Vision from CTU in Prague. He has been working in Machine Learning and Data Science for a few years in several IT startups and companies. He enjoys exploring interesting world problems and solving them with State-of-the-Art techniques and developing open-source projects.
Tabular Classification and Regression Made Easy with Lightning Flash was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



