



Serving Data Science to a Rookie
Last Updated on July 20, 2023 by Editorial Team
Author(s): Daksh Trehan
Originally published on Towards AI.
So, last week my team head asked me to interview some of the possible interns for the team for the role of data science and machine learning, and he forwarded me their resumes. He asked me to select at most 2 candidates from 8 eligible candidates. That was pretty usual, right?
Now here comes the twist, I called everyone and asked just one fundamental question “What is Data Science?”, one replied it is the science of extracting data and then modeling it, another one responded it is equivalent to machine learning, next one told me it is a part of AI to predict/classify.
These definitions might be correct collectively, but what exactly is it? No one was able to provide a decent pretext and its legit use. I was shocked as their knowledge was utterly contrary to their fancy resumes.
Now coming to the point, What is Data Science?
Data Science is the science of collecting, storing, processing, describing, and modeling data.
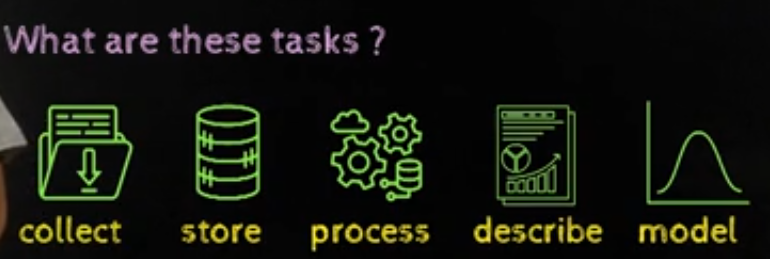
5 ingredients help to make a delicious Data Science dish:
- Collecting
- Storing
- Processing
- Describing
- Modeling
The critical thing to note here is Machine Learning, and Data Science is not the same — you can learn the difference between them from my previous article i.e., What exactly Machine Learning is?
Collecting: This is the first step of Data Science, and it is a collection of relevant or irrelevant data from different sources. The data can be structured (that would require the use of SQL) or unstructured (that would need skills of crawling/scraping).
Skills required:
- Programming knowledge
- Database knowledge
- Statistical knowledge
Storing: This includes storing the collected data so that it is readily available for further computation and predictions. The data can be stored in data lakes or data warehouses (e.g., Hadoop).
There are 3 characteristics to big data: High Volume, High variety, High velocity (the 3V’s).
Skills required:
- Programming knowledge
- Database knowledge (SQL, NoSQL)
- Data warehouse/ Data lake knowledge
Processing: This is when we start preparing the data for the leading cause i.e., prediction/classification. It includes data wrangling, filling missing data, and data normalization. In novice style, it is removing/replacing every unnecessary/NaN value and only storing the pertinent data.
Skills required:
- Programming knowledge
- Map Reduce (Hadoop)
- Database knowledge (SQL, NoSQL)
- Basic Statistical knowledge
Describing: This consists of visualizing the processed data for better understanding and summarization. This stage is decisive as it helps you model the algorithms accordingly.
Skills required:
- Statistical knowledge
- Spreadsheet knowledge (MS Excel)
- Visualization tools (Python, Tableau, Power-BI)
Modeling: This is drawing inferences from the processed data. It includes identifying the relation between data, testing hypotheses, and providing the statistical guarantee.
There are further 2 types of modeling;
- Statistical modeling — Includes a simple, intuitive model and is suited for low dimensional data.
- Algorithmic modeling — This is also called machine learning, which contains a sophisticated, flexible model and can work with high dimensional data.
Skills required:
- Programming knowledge
- Statistical knowledge
- Domain knowledge
But, there is a limitation to machine learning: you can’t solve every problem using it. Suppose you have a large amount of high dimensional data, and you want to learn some complex relationships between value and labels. There, we will use Deep Learning.
Skills required for Deep Learning:
- Inferential statistics
- Probability theory
- Calculus
- Optimizing algorithms
- Machine Learning
- Programming skills
So what are some collective skills that Data Science demands?
- Domain knowledge (Intermediate to Expert)
- Programming skills (Intermediate to Expert)
- Mathematical/Statistical knowledge (Intermediate to Expert)
- Hacking skills (Novice to Intermediate)
Myths About Data Science
- A machine can do everything.
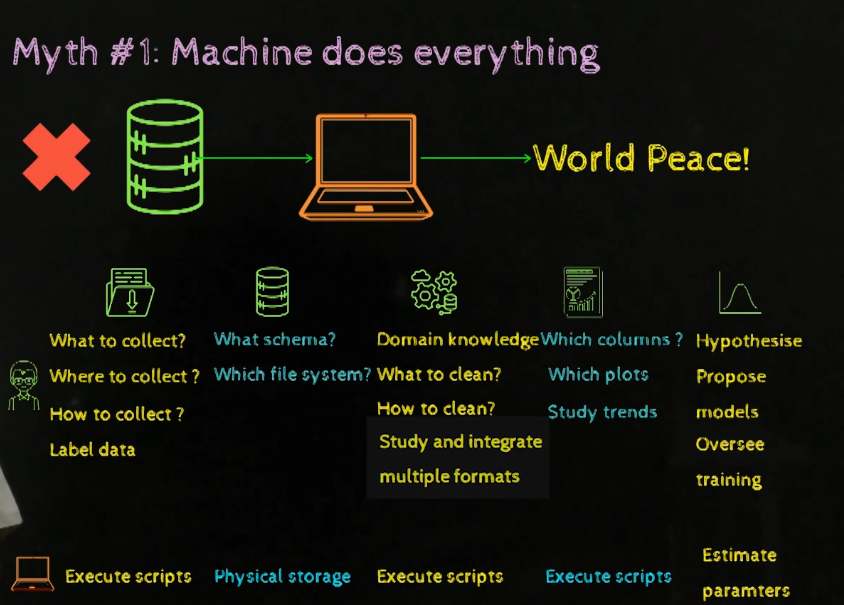
2. Data Science requires Deep Learning and Big Data.

3. Data Science is always successful.

Now we know a lot about Data Science, but what about its implementation and tools it requires?
Crisp DM (Data Science pipeline)
It is an open standard process model that describes conventional approaches used to solve business analytical problems.
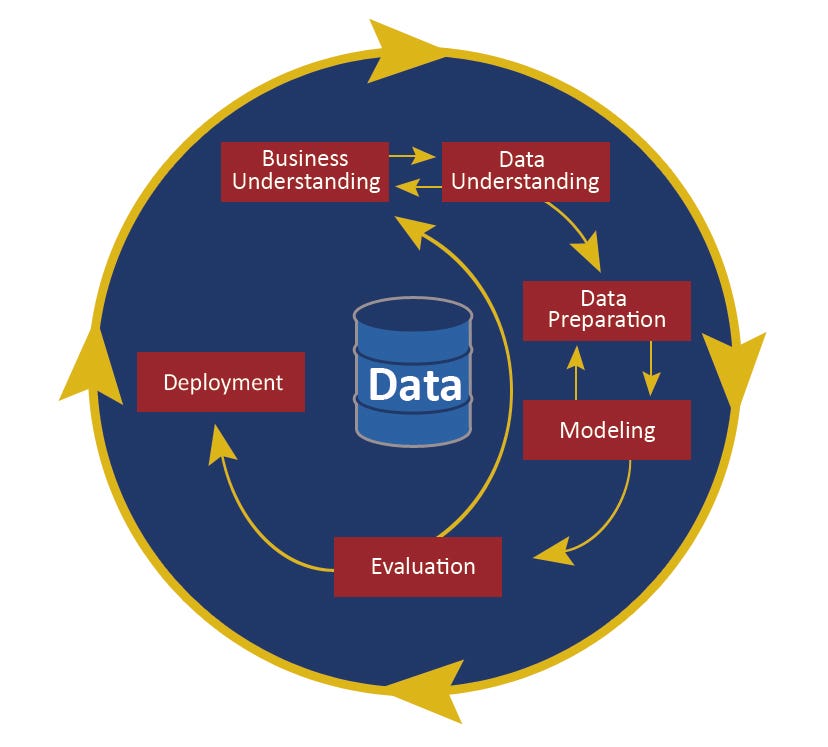
- Business understanding
- Data understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
Tools for Data Scientist
- No code environment (Novice users) — H20.ai, Amazon Lex
- Spreadsheets/BI tools (Novice users) — MS Excel, Tableau, Power BI
- Programming language (Intermediate users) — Python, R, MATLAB
- High-Performance Stack (Highly skilled users) — Hadoop, Apache Spark
Conclusion
Hopefully, this article helped you understand What Data Science is?, and what all skills you might require to become superb Data Scientist. And it’s pretty unusual to find that just with few clicks and a little statistical and programming knowledge, we can manage many data. But again, all we care about is a model good at predicting/classifying 🙂
A unique token of appreciation to:
- Dr. Mitesh Khapra and Dr. Pratyush Kumar from OneFourthLabs ~ https://www.linkedin.com/company/one-fourth-labs/
- Gaurav Chatterjee (machinelearningman) ~ https://www.linkedin.com/in/gaurav-chatterjee-857813137/
- Megan Dibble ~ https://www.linkedin.com/in/megandibble1/
Feel free to connect:
LinkedIN ~ https://www.linkedin.com/in/dakshtrehan/
Instagram ~ https://www.instagram.com/_daksh_trehan_/
Github ~ https://github.com/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Cheers.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

