


 in Python : The Basics")
Regular Expression (RegEx) in Python : The Basics
Last Updated on May 25, 2022 by Editorial Team
Author(s): Hrishikesh Patel
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Regular Expression (RegEx) in Python: The Basics
Master the fundamentals of RegEx in Python
Consider you have a lot of text data, and you want to extract meaningful information. For example, you might want to extract hashtags, @mentions, URLs, etc. from any tweets. What’s the best way to do it? You got it right — it is to use a regular expression or regex. The regex is a sequence of characters that form a pattern that matches the text. We can define a pattern for hashtags, and it can be used to match any hashtags in the given tweets.
Though regex implementation is mostly similar across different programming languages, there can be minor differences. In this story, you’ll learn to use regex in Python. This story covers the basics of regex. I’ll write another story for advanced regex.
RegEx in Python
Python has a dedicated package called ‘re’ for working with regex. Click here to read its documentation. It has different functions such as .search(), .split(), .findall(), .sub(), etc. I will show the usage of the findall() function to find all desired information from the text using the regex pattern.

You may wonder what the small character “r” means before the regex pattern and how we can generate different patterns. Let’s dive into that!
Raw string in Python
Before delving deep into the regex, it is crucial to understand what raw string is. Python has special characters such as newline character (\n), tab space(\t), etc. in strings. What if we need \n to be a part of the string instead of being treated specially? In this case, we should use raw strings. The following example illustrates the difference between normal and raw strings. Using raw strings for regex patterns is recommended to avoid the Python interpreter treating the strings unexpectedly.

Summary of typical regex metacharacters
Metacharacters are characters with special meaning in the regex pattern. For example, metacharacter \d represents a digit from 0 to 9. The following table summarizes basic metacharacters used in regex.

1. Literal match
In the absence of metacharacters, you can get an exact match.

2. Match a digit using \d
\d represents any digit from 0 to 9.

3. Match a non-digit using \D
\D matches any single non-digit character.

4. Match a word character using \w
\w matches any single word character. It can include anything from A to Z, a to z, numbers 0 to 9, and an underscore(_).

5. Match a non-word character using \W
Non-word characters include anything except the word characters mentioned above.

6. Match whitespace with \s
\s allows to match single whitespace character.

7. Match a non-whitespace with \S
\S can be used to match single non-whitespace character.

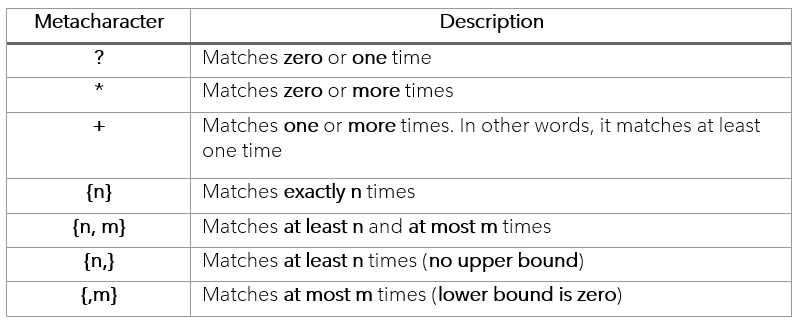
Quantifiers in regex
Let’s first extract a phone number from the text.

Since \d matches a single digit, we must write it ten times to extract a
ten-digit number. But wait — it doesn’t look pretty. Here’s the solution — use quantifiers for characters in the pattern.
1. Match one or more times using +
The + matches one or more occurrences of its preceding character. So \d+ means match one or more occurrences of a digit.

Similarly, you can match zero or more occurrences of its preceding character using *. So \w* means to match zero or more occurrences of a word character.
2. Match exactly n occurrences using {n}
The {n} matches exactly n occurrences of its preceding character in the pattern. So

Other variations:
- {n,m} — Matches its preceding character at least n and at most m times e.g., \d{2, 4} will match a digit at least two times and at most 4 times.
- {n,} — Matches its preceding character at least n times and there is no upper limit e.g., \w{4,} will match a word character at least four times with no upper limit.
- {,m} — Matches its preceding character from zero to m times e.g., \D{,4} will match any non-digit character at most four times, while it can be zero time as well.
3. Match zero or one-time using?
The ? matches its preceding character zero or one time. For example, cats? will match cat as well as cats.

Note — All these quantifiers are applied to their preceding characters, not the entire word e.g., in mango+ pattern, the + only applies to the last character o, not the word mango.
But what if you want to match the special characters like \ ,*, +,? etc. Since these are special characters, you cannot directly match them as shown below:

The solution is to use the escape character \ before the special character to be matched e.g., use \+ in the regex to match + . Similarly, you can use \\ in the pattern to match \ in the text.

Thanks for reading this far. I now have a bonus for you.
Bonus
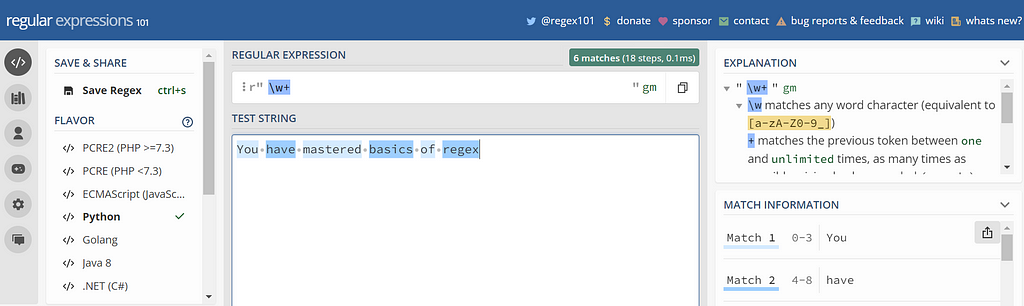
There is a really cool website https://regex101.com/, where you can test your regex pattern. It also supports different programming languages. Go check out the page and have some fun with regex.
Thanks for reading my first ever story on medium. I will appreciate your feedback, and please feel free to post your questions in the comments. Follow me on Medium if you’d like more stories like this.
Regular Expression (RegEx) in Python : The Basics was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

