


Outline
Last Updated on July 24, 2023 by Editorial Team
Author(s): Haryo Akbarianto Wibowo
Originally published on Towards AI.
Deep Learning, Tutorial
U+1F356U+1F372 Recibrew! Predicting Food Ingredients with Deep Learning!U+1F372U+1F356
▶️▶️ Step by step tutorial on predicting food ingredients using seq2seq in Deep Learning implemented in Pytorch Lightning. ◀️◀️
Hi, guys, welcome to my new article. It’s been a long time since the last time I wrote something. Today, I want to write about my simple fun project called Recipe Brewer (Recibrew). Recipe Brewer is one of the fun projects that I do in my free time to satisfy my curiosity. Thus, I want to share how I have done my fun little project as honestly as possible U+1F604. So you can replicate and learn what I built.
- Introduction
- Repository
- Model
- Dataset, EDA, and Data Preprocessing
- Evaluation Metrics
- Decoding Strategy
- Implementation
- Experiment
- Result
- Suggestion
- Fun Ingredient Generator
- Conclusion
- Afterwords
Introduction
The Project is about building an ingredients generator application. It is an ingredients predictor based on the recipe title as the input. I used Deep Learning as the approach to create the model that generates the recipe name.
The idea comes when my mother cooks something and wonders what ingredients to cook some new food. Then I thought, ‘Hmm, How about I build a program that can extract ingredients from a food name.’ Since I have experience in developing some Deep Learning (DL) application, why not have fun on it U+270C️.
In summary, I want to build a program which receives food name as input and output the ingredients. Here is an example of what I want to develop:
Input : 'fried rice'
Model Output : '1 gr rice U+007CU+007C 1 gr salt'
This article will be mainly about experimenting with some Deep Learning Seq2Seq architectures in Natural Language Processing (NLP). They are Gated Recurrent Unit (GRU)+ Bahdanau Attention and Transformer. Since I am curious about their performance in a low parameter, I made these architecture small. Each of them has almost similar parameters (around 1M). Later, we will compare each of them and see which architecture is the best. I also want to introduce some of the great tools for developing a Deep Learning application in Pytorch, which is Pytorch Lightning. I will tell you how helpful it is to make my code base more structured.
This article’s primary focus will be mainly telling step-by-step how to implement and experiment with the Recipe Brewer. This article will not dive too much about the detail of the concept. Nevertheless, I will provide some good readings that might help you understand the concept better. If you are new, Do not worry! I will give a gentle description of these concepts. If you also do not understand. DO NOT WORRY!
And here is my ultimate quote from an ML guru that might keep your spirit up U+1F606.
Don’t worry about it if you don’t understand
~ Andrew Ng
Repository
For anyone who wants to dive into the code, here is the repository link:
haryoa/ingredbrew
Contribute to haryoa/ingredbrew development by creating an account on GitHub.
github.com
Several notes:
- The source code is in ‘recibrew.’ The source code is mainly written in Pytorch and wrapped in Pytorch Lightning.
- The notebook in the repository is the ‘scratchpad’ on building the codebase. For anyone that has an interest in how I frustratedly implemented my idea, see the notebook. (Except for the EDA)
- To run the GRU + Bahdanau Attention experiment, go to this Colab link
- To run the Transformer experiment, use this Colab link
Model
As I said in the introduction, I used 2 Seq2Seq architectures, which are GRU + Bahdanau Attention and Transformer. I will briefly describe each of them.
Seq2Seq
As the name shows, seq2seq is an architecture ‘pattern’ in deep learning which receives a sequential input (text, audio, video) and also produces a sequential output (text, audio, video). The architecture mainly contains Encoder and Decoder. The Encoder is a Deep Learning model that encodes the input seq2seq, the encoded input will be decoded by the Decoder to help to produce a sequence of output. The Decoder is also a Deep Learning model. See Image 0 to see the visualization.
Some examples that implement seq2seq:
- Machine Translation: input source language, output target language
- Summarization: input article, output summary of an article
- Food Ingredient : (this project)
In this article, we will only explore GRU and Transformer seq2seq architecture.
For further information about seq2seq, you can see this link.

GRU + Attention seq2seq
One of the seq2seq that I built consist of GRU Encoder and GRU Decoder with Bahdanau Attention. I will describe each of them below.
Gated Recurrent Unit (GRU) is a variant of RNN which handles sequential (e.g., text) input. The sequence of input is ‘gated’ by reset gate and update gate. The update gate adds or removes the information for each step of the sequence. Meanwhile, the reset gate decides how much to forget the information in the past step.
If you want more depth details about GRU, I suggest to read this article (Thanks to Michael Phi):
Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
Hi and welcome to an Illustrated Guide to Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU). I’m Michael…
towardsdatascience.com
Attention, in a simple term, learns what is important and not important between variables to do some tasks. In sentiment analysis tasks, when using Attention, It might learn what token to attend to make the model easier to learn. Image 1 tell us some example when seeing the dependency of a word doing ‘self-attention’ to other words.
Intuitively, attention is a mechanism for remembering the sequence of input. It learns what input is best to be attended, given an output. Attention selectively determines what input is needed, given the word. It might boost the model performance.
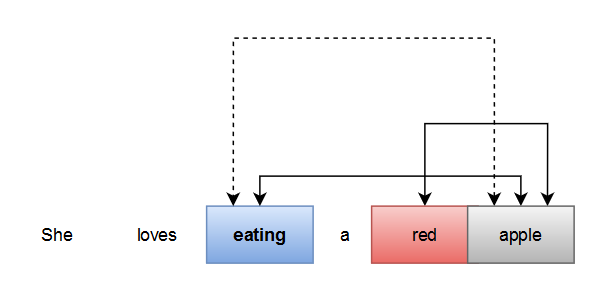
In our case, the model wants to learn the importance of the input (source) and output token (target). Here is some example
Source : fried rice
Current token in target : oil
The model should learn that oil should become attentive to the fried token in the source.
Note:
You use oil to make some-fried stuff right? Tell me if I am wrong since I am noob in this stuff XD.
The attention formula is as follow:
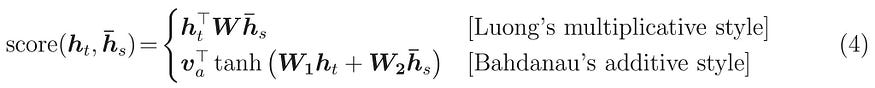
We use Bahdanau’s Attention formula. The input of the Attention is the source encoded output (output of Encoder) as value(h_t) and the hidden state of the decoder GRU layer as query (h_s). v, W is a parameter that is learned.
For further information, I encourage you to read this article about the technical detail about Attention.
Attention? Attention!
Attention has been a fairly popular concept and a useful tool in the deep learning community in recent years. In this…
lilianweng.github.io
Transformer Seq2Seq
The Transformer is the current meta hype base deep learning architecture. Existing NLP architecture mainly used the Transformer as a base architecture. This architecture gives birth to many Sesame Street named deep learning architecture like BERT and GPT.
The Transformer itself is a seq2seq architecture consist of several self-attention layers on both Encoder and Decoder side (GRU seq2seq use GRU on both Encoder and Decoder). The Transformer alleviates the weakness of the GRU that needs to wait for the process of each sequential step. The transformer process each of them simultaneously, enable the Transformer to do parallelization.
Architecture visualization is shown in Image 3. For more information about how Transformer work, I highly encourage you to visit this excellent article.
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations…
jalammar.github.io

Dataset, EDA, and Data Preprocessing
Dataset

In this project, I used a food recipe dataset. I tried to search for food recipes in Google and found an Indonesian Food Recipe Dataset in Kaggle. Since it is the data that I want, I decided to use it as the dataset of my project.
The dataset uses the Indonesia language. I tried to search the dataset food recipe in English, but I did not find it. So, I gave up and decided to use the Indonesian one.
Do not worry about the language. I will provide some explanation about the meaning of the data (if necessary). What I want to emphasize is the process of what I did on this project. You can change the data into other food recipe dataset that you want.
Here is the dataset:
Indonesian Food Recipes
14000 recipes of chicken, lamb, beef, egg, tofu, tempe, and fish
www.kaggle.com
In this project, I explore and analyze the data to determine what kind of data I deal with. After that, I preprocessed the data according to the need of the seq2seq model.
Exploratory Data Analysis
The first thing I did was to see the format of the data. The data is in ‘.csv’ format. So I did this:
df = pd.read_csv("../data/raw/indonesia_food_recipe.csv")
Here are some instances:

The data contains ‘title’, ’ingredients’, ‘steps’, ’loves’, ’URL’, and ‘basic_ingredient”. ‘Title ’ is the food name, ‘Steps’ is how to cook the food, Loves is the user like in the website, ‘basic_ingredient ’is the core ingredient needed to create the food
NOTE
(‘ayam’ == chicken).
Since the project is ‘predicting ingredients given food name.’ The column needed for this project is ‘Title’, ‘Ingredients’, and ‘basic_ingredient’. ‘basic_ingredient’ is required to split the dataset.
Then, I decided to extract these statistics to answer the descriptive question:
- Number of tokens
- Number of unique tokens
- top 20 frequency unique tokens
To do it, I used my python package to extract each of them. I named it Exploda (Explore Data). This package extracts the basic statistic of the data.
My Story/Opinion
Currently the package is in private. Nevertheless, if anyone have interest in it, I might want to open source it.
EDA Ingredients
from exploda.explore import get_stat
result = get_stat(df, 'Ingredients', ['get_total_instances', 'get_value_counts_column_and_unique_token', 'get_sum_count_token',
'get_stat_token'])
print('total_instance : ', result['get_total_instances'])
print('total token : ', result['get_sum_count_token'])
print('unique token : ', result['get_value_counts_column_and_unique_token']['total_unique'])
Output:

Top-20 token in the dataset
[('1', 48903),
('2', 30534),
('bawang', 27729),
('secukupnya', 20039),
('merah', 16548),
('buah', 15676),
('siung', 14954),
('putih', 14403),
('3', 13590),
('garam', 12228),
('sdm', 11257),
('daun', 10905),
('4', 10013),
('sdt', 9542),
('cabe', 9451),
('5', 9141),
('gula', 7777),
('bumbu', 6922),
('air', 6892),
('iris', 6244)]
So in the dataset, ‘1’ and ‘2’ have the highest frequency. They might be a number of an ingredient (e.g., 1 pcs, 2 kg). ‘bawang’ or onion, which has the 3rd highest token frequency, is a fairly common ingredient in Indonesia.
To sum it up, mostly the top-20 tokens are about the measurement on how to apply the ingredient like ‘secukupnya’ (sufficiently), ‘buah’ (fruit) , 1,2,3,4,5, sdm, sdt ‘iris’ (slice).
It also contains popular ingredient such as ‘bawang putih’ (garlic), ‘bawang merah’ (shallot), ‘daun’ (leaf), ‘cabe’ (chilli), ‘gula’ (sugar), ‘air’ (water).
EDA Food name
result2 = get_stat(df, 'Title', ['get_total_instances', 'get_value_counts_column_and_unique_token', 'get_sum_count_token'])
print('total_instance : ', result2['get_total_instances'])
print('total token : ', result2['get_sum_count_token'])
print('unique token : ', result2['get_value_counts_column_and_unique_token']['total_unique'])
Output:

As expected, the total and unique token of the food name is lower than the ingredients.
Top-20 token in the dataset
[('tahu', 2557),
('tempe', 2269),
('ayam', 1999),
('telur', 1768),
('sapi', 1611),
('kambing', 1442),
('goreng', 1000),
('daging', 928),
('ikan', 842),
('tumis', 748),
('pedas', 733),
('bumbu', 607),
('ala', 572),
('kecap', 485),
('telor', 453),
('balado', 434),
('sambal', 428),
('dan', 426),
('sate', 417),
('beef', 406)]
Most of the top-20 highest frequency token in food name is the main ingredient such as ‘tahu’ (tofu), tempe, ‘ayam’ (chicken), ‘telur’ (egg), ‘sapi’ (beef), ‘kambing’ (goat), ‘daging’ (meat), ‘ikan’ (fish), ‘telor’ (also egg), ‘sate’ (satay). Other than that, they are the flavor of the food (‘pedas’ [spicy])
From this exploration, I believe that the model might recognize the ingredient given the food name. Several ingredient names tokens become a part of the food name. Let us test later on. I believe that food name such as ‘pedas’ (spicy) must output ‘cabe’ (chili)
My Story/Opinion
I hope the data is not bad, for instance, containing ‘fried chicken’ food name and having fish instead of chicken as the ingredient U+1F605.
—
My Story/Opinion
The top-2 highest frequency token for food name is ‘tahu’ (tofu) and tempe (google it). For your information, ‘tahu’ and tempe are the most common basic food that we eat in Indonesia.
Data Preprocessing
Here are the preprocessing that I had done to the data:
- Change ‘/n’ into ‘U+007CU+007C’ as ingredient separator
- Lowercase
- Remove duplicate
- Remove non-alpha-numeric character
- Separate ingredient and its measurement (‘15gr’ -> ’15 gr’)
- Remove some instances of more than 120 tokens. I choose this hyperparameter because it can be divided by 4 (for multi-head in transformer) and more than Q3 (84) + standard deviation (31).
Here is the final statistic based on basic_ingredient:
tempe 1958
telur 1931 # egg
tahu 1931 # tofu
ikan 1858 # fish
ayam 1772 # chicken
sapi 1760 # beef
kambing 1590 # goat meat
Name: basic_ingredient, dtype: int64
Then I split the dataset into train, dev, and test set using sklearn.model_selection.train_test_split to ensure balance split. I split based on ‘basic_ingredient’ column. The ratio is 80% 10% 10%.
train_df, remainder_df, _, _ = train_test_split(df, df['basic_ingredient'], test_size=0.2, random_state=234)
dev_df, test_df, _, _ = train_test_split(remainder_df, remainder_df['basic_ingredient'], test_size=0.5, random_state=345)
Then, I output them to ‘processed’ folder
train_df.to_csv('../data/processed/train.csv',index_label='no')
dev_df.to_csv('../data/processed/dev.csv', index_label='no')
test_df.to_csv('../data/processed/test.csv', index_label='no')
The data manipulation and exploration is done 🙂
See this notebook for the implementation of the EDA:
haryoa/ingredbrew
Notebook
github.com
Evaluation Metric
In this project, we use BLEU as an evaluation metric to compare performance between GRU and Transformer.
BLEU
BLEU (Bilingual Evaluation Understudy) is a popular metric widely used on seq2seq tasks such as Machine Translation. BLEU’s main idea is checking whether many token are overlapping in predicted output and the ground truth. The n-grams used are 1-gram, 2-gram, 3-gram, and 4-gram.
For more information about BLEU and its problem, I recommend reading this article (Thank you,
Rachael Tatman for your awesome article about BLEU :))
Evaluating Text Output in NLP: BLEU at your own risk
One question I get fairly often from folks who are just getting into NLP is how to evaluate systems when the output of…
towardsdatascience.com
My Story/Opinion
TIL (Today I Learn) about the abbreviation of BLEU come from (BilinguaL Evaluation Understudy). Until I wrote this article, I thought BLEU is named randomly.
Decoding Strategy
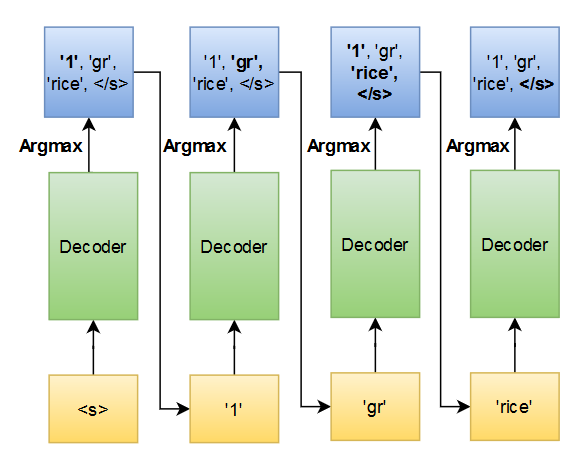
When we implement a generation machine learning system, we must decide how to generate the output sequence. In our seq2seq system, the Decoder will output confidence score (softmax probability distribution) for each step. The question is, how do we use each step’s confidence level?
One of the general approaches is Greedy search decoder. The strategy is simple enough; just pick the highest confidence score for each step until you find a stop token (‘<eos>’). That’s it.
Note
Remember that decoding strategy is used when doing inference, not training.
As a reminder, the seq2seq consists of Decoder and Encoder. The input will be encoded into something (a vector actually), decoded by Decoder for each step. Then it will produce a confidence score of each token in the vocabulary. Then, we choose the highest score.
Let’s see some example here:
Encoder : Encoder of seq2seqDecoder : Decoder of seq2seq
<s> and </s> are start and end special token respectivelyinput = "<s> fried chicken </s>"
encoder_output, hidden_variable = Encoder(input)STEP 1:target_input = "<s>"
decoded, hidden_variable : Decoder(target_input, encoder_output, hidden_variable)Output decoded example:.
.
chili 0.01
chicken 0.95 <- we choose the highest (greedy)
fish 0.03
egg 0.01
.
.target_input = "<s> chicken"STEP 2:
target_input = "<s> chicken"
decoded, hidden_variable : Decoder(target_input, encoder_output, hidden_variable)Output decoded example:.
.
U+007CU+007C 1.00 <- we choose the highest (greedy)
chicken 0.00
fish 0.00
egg 0.00
.
.target_input = "<s> chicken U+007CU+007C "STEP 3:
target_input = "<s> chicken U+007CU+007C"
decoded, hidden_variable : Decoder(target_input, encoder_output, hidden_variable)Output decoded example:.
.
U+007CU+007C 0.00
chicken 0.00
fish 0.00
egg 0.00
oil 1.00 <- we choose the highest (greedy)
.
.target_input = "<s> chicken U+007CU+007C oil "STEP 4:
target_input = "<s> chicken U+007CU+007C oil"
decoded, hidden_variable : Decoder(target_input, encoder_output, hidden_variable)Output decoded example:.
.
U+007CU+007C 0.00
chicken 0.00
fish 0.05
egg 0.30
oil 0.20
</s> 0.55 <- we choose the highest (greedy)
.
.target_input = "<s> chicken U+007CU+007C oil </s>"
END
The above example is basically how the seq2seq greedy decoding works.
There are other decoding strategies, such as Beam Search, Top-k sampling, and top-p sampling. For preventing me from creating 60 minutes-read article U+1F61C, I decided only to use Greedy search decoding.
My Story/Opinion
For a teaser, I plan to release a new article about sampling strategy in the future and compare each of them 🙂
Implementation
Library Used
- Pytorch 1.5.1: A popular Deep Learning Framework is written in Python
- Torchtext 0.6.0: A library focused on processing text on Pytorch
- Sacrebleu 1.4.10: A toolkit on calculating BLEU
- Pytorch Lightning 0.8.1: New yet powerful extension of the Pytorch. If you find a need for Keras-like framework in Pytorch (Callback!) and a great saver on making your code tidier and high reusability, I highly encourage you to use this package! Thank you, William Falcon and team, for your awesome package U+1F604
- Pandas 1.0.5: Python usual data tabular manipulation package.3
From pytorch-lightningGitHub package:
Note
Lightning is a way to organize your PyTorch code to decouple the science code from the engineering. It’s more of a PyTorch style-guide than a framework.
In Lightning, you organize your code into 3 distinct categories:
Research code (goes in the LightningModule).
Engineering code (you delete, and is handled by the Trainer).
Non-essential research code (logging, etc… this goes in Callbacks).
—
My Story/Opinion
Is it only me that when writing code in pure Pytorch, I have a hard time on fixing code readibility and structuring? That’s why all of my previous article are written in Keras.
Token Representation
I used word index sequential representation, which will be converted into word embedding by the model. The token is tokenized (split) from the sentences using nltk.word_tokenizer. I processed it with the torchtext library where it will sequentially encode each of token into index representation in the array. I built the token vocabulary based on the training set. I set init and end token as <s> and </s> respectively.
On producing iterator used by the model, I used torchtext.data.BucketIterator, which will sort the batch based on the length of the food name token. Below is the code on how to process and construct the iterator (picked from my source code).
Example:
'fried rice' -> '<s> fried rice </s>' -> [2, 4342, 42432, 3]
Modeling
I used PyTorch lightning on structuring the PyTorch code.
GRU + Attention
I used the code from the Tensorflow NMT attention tutorial and rewrote them into Pytorch. I also add small addition, such as enabling the bidirectional and multi-layer GRU on the decoder side (although I do not use it U+1F61B). You can see the code in this link (my repo):
haryoa/ingredbrew
Contribute to haryoa/ingredbrew development by creating an account on GitHub.
github.com
I combine them in the Pytorch Lightning model interface. See the above snippet code.
In the forward function, I divide forward into forward_encoder and forward_decoder_train . forward_encoder will receive source input and encoded it into enc_out and hidden. They will be the input of Decoder, which will output the confidence score for each step. The Decoder and Encoder used shared embedding (means shared vocabulary).
In training, I used full teacher forcing ( the input of the next step is the ground truth ) to make it similar to the Transformer setup. The training is optimized with AdamW optimizer.
Noob advice:
Be sure to set your padding_idx on your criterion (CrossEntropy) and your embedding to ensure no operation done on the padding. In the past, When I developed some NER system, I noobly ignore this and have bad model results.
Transformer
I implement the Transformer by using a built-in Pytorch transformer package. The package does not include Positional Embedding and Word Embedding. So I took the implementation of the positional embedding from the Pytorch tutorial (See https://pytorch.org/tutorials/beginner/transformer_tutorial.html).
In this section, I will focus on describing the implementation of the mask implementation in Transformer, especially on how to implement the mask. Here we go:
The encoder and decoder forward pass implementation are straight forward. The want I want to emphasize on is the mask variable.
out_trf = self.trfm(out_emb_enc, out_emb_dec, src_mask=None, tgt_mask=tgt_mask, memory_mask=None, src_key_padding_mask=src_pad_mask, tgt_key_padding_mask=tgt_pad_mask, memory_key_padding_mask=src_pad_mask
src_mask: In source input (input of encoder), a position, if provided with a ‘True’ flag (means masked) in a Boolean Tensor will not attend to any other sequence (remember transformer has self-attention). This variable will be used on the Encoder of the Transformer. The transformer default implementation will set this to None.
tgt_mask: Similar to src_mask, but In target input (input of decoder). This variable will be used on the Decoder of the Transformer. As I said above, the Transformer can process simultaneously, so it needs a mask to prevent doing calculations on the attention process.
Easy way to visualize tgt_mask
Remember: decoder output sequence of text in sequential order.
For example, If the model want to output 'Fried Rice is delicious'. In the first step (Fried), it will not attend 'Rice is delicious'
In the second step (Rice), It will attend 'Fried' and will not attend 'is delicious'
In the third step (is), It will attend 'Fried' and 'Rice and will not attend 'delicious'
In the forth step (delicious), It will attend 'Fried, Rice, and is'
memory_mask : In memory (output of encoder transformer), when used on the attention second time (remember, attention process in decoder layer contains two steps, self-attention, and encoder-decoder attention) will not attend any other sequence. The transformer default implementation will set this to None.
src_key_padding_mask: Basically padding mask on the source. This process will act as masking the key in attention process
tgt_key_padding_mask: Basically padding mask on target. This process will act as masking the key in attention process
memory_key_padding_mask: Basically padding mask on memory which is the output of the encoder. This process will act as masking the key in the attention process. The memory of encoding is the padding of the source.
Implementing padding_mask is easy (see mask_pad_mask ) and for tgt_mask, the implementation should use transformer.generate_square_subsequent_mask in the pytorch.nn.Transformer .
In the Pytorch Lightning Implementation, just do it normally like this:
Straight forward and easy to set up! Just remember the Noob Advice that I give to you below. Some silly small problems come from it.
Noob Advice:
See this ?
logits = self.forward(src, tgt[:-1])
loss = loss_criterion(logits.view(-1, output_dim), tgt[1:].view(-1))Do not forget to set the ground truth as tgt[1:] and the encoder input as tgt[:-1]
We want the model learn to predict next word in the decoder , aren’t we?
e.g : current token is ‘</s>’ we want to make sure the model to learn the next word ‘chicken’
—
My Story:
Let me tell my story about implementing the transformer. I searched a built-in easy copy pasta code (too lazy to debug and implement it from scratch). I stumbled on that Pytorch have built-in transformer package and have a tutorial on it. I see the tutorial and conclude that the tutorial cannot be applied to my case. It does not handle the padding mask. How the hell can I do it? I read the documentation and find a variable called [src/tgt/memory]_mask and [src/tgt/memory]_padded _mask. Yep.. still confused as the description is too short. I search for all the stack overflow and Github issues. Finally, I found some enlightenment that someone writes an implementation in Colab. Also, I was not conscious that there is additional documentation about these mask variable ( I should’ve scrolled down a little bit in that documentation).
Well… problem solved anyway. If anyone have strugle like this, just see my implementation on implementing the Pytorch Transformer.
Greedy Decoder
The Greedy Search decoding implementation is simple. See below:
Above is the inference source code for GRU. At the inference step, The model loop each instance one by one. For each step in the decoder, it will do greedy search until It finds the end of sentence token ‘</s>’.
The inference for the Transformer is also similar to the GRU one. You can see my implementation here:
haryoa/ingredbrew
You can't perform that action at this time. You signed in with another tab or window. You signed out in another tab or…
github.com
Experiment
I do not do hyperparameter tuning to not spend a lot of time on training the model.
Transformer
Here is the hyperparameter that I choose for the Transformer model:
"dim_feedforward": 100
"dropout": 0.1
"lr": 0.001
"nhead": 2
"num_decoder_layer": 4"num_embedding": 100 # Also act as hidden unit in decoder and encoder layer"num_encoder_layer": 4
"padding_idx": 1
Total Parameter:
U+007C Name U+007C Type U+007C Params
-----------------------------------------------------
0 U+007C full_transformer U+007C FullTransformer U+007C 1 M
GRU
Here is the hyperparameter for GRU seq2seq model:
embedding_dim=100hidden_dim=100enc_bidirectional=Trueenc_gru_layers=1dropout=0.1
Total Parameter:
U+007C Name U+007C Type U+007C Params
------------------------------------------------------
0 U+007C encoder U+007C Encoder U+007C 121 K
1 U+007C decoder U+007C Decoder U+007C 945 K
2 U+007C shared_embedding U+007C Embedding U+007C 300 K
3 U+007C criterion U+007C CrossEntropyLoss U+007C 0
They are trained using Colab GPU and use Greedy Search Decoder on doing the inference.
Note
The Colab notebook will act as main program which call the Pytorch Lightning implementation.
Before doing the experiment, I make sure to ensure reproducibility by setting the seed to 888
from pytorch_lightning import Trainer, seed_everythingseed_everything(888)
I use batch size 64 with accumulated_grad_batches=2 . This means that the batch size used to compute the loss will be 128.
Result
Here it is, the moment of truth! U+1F383
After training, I load the best model produced with pytorch_lightning ModelCheckpoint. I predict the test dataset and calculate its BLEU using sacrebleu . Table 0 shows the result for both GRU and Transformer. From the table, we can conclude that the Transformer really dominates GRU + Attention Seq2Seq. With both have almost similar low parameters, Transformer beat GRU. The BLEU difference margin is around 13.
My Story/Opinion
I thought Transformer lose to GRU because from what I have experienced, Transformer tends to overfit to data and often produce drunk output.
Let us sample some data to find out more!
Note
I run the code in
00007_eda_result.ipynbinside the notebook in the repository.

Image 5 shows 3 samples as the output of our trained model. From the example above, we can see that GRU often repeat ingredient and does not stop. It might be caused by GRU, which overfits to some ingredient. The highest confidence level for every step when using Greedy Decoder always produces the same ingredient.
Transformers and GRU tend to produce ‘1/2’ token. From what we have seen in EDA, ‘1’ and ‘2’ have the highest frequency, I think we can infer that the model might overfit to these number.
Although the Transformer has a better variety output than GRU, it still repeats some ingredients. From Image 5, we can see that In summary, it repeats ‘kikil sapi’ (beef) 4th time. After that, it finally changes the output into something else. To sum it up, this Transformer and GRU model does not learn that an ingredient must not appear twice or more.
Anyway, the Transformer output might represent the recipe in the original. We know that there are many varieties of ways to cook something. So, even it has a different output than the ground truth, and we cannot rule that it is wrong.
Suggestions
- I should have done hyperparameter tuning (small to medium model). With it, maybe it can produce better. This is also my to-do list article to write.
- Use other decoding strategies. As I said earlier, I will create a new article about it soon. Let us see the difference between greedy with others.
- Avoid repetition. To avoid repetition, maybe I can add a restriction on decoding?
- Pretrained the model with other (big) data. I think with a pre-trained model, it can increase the result further.
- Add data with semi-supervised learning such as back-translation. This is currently hot and might also increase the quality of the model
Fun Recipe Brewer Generator
U+1F606 Let’s have fun with the model! U+1F606.
You can also try it with the Colab link below. Note that the Ingredients is generated!
Random Input 1:
Food : nasi goreng pedas (spicy fried rice)
Ingredients:
1 piring nasi putih (rice)
1 butir telur (egg)
1 buah wortel (carrot)
1 buah timun (cucumber)
1 buah bawang putih (garlic)
1 buah bawang merah (onion)
1 buah cabe merah (red chili)
1 buah cabe rawit (cayenne pepper)
1 buah tomat (tomato)
1 / 2 sdt terasi (shrimp paste)
1 / 2 sdt garam (salt)
1 / 2 sdt merica (pepper)
Let’s try a generic one, ‘spicy fried rice’. As you can see, it output chili even though there is no chili in the food name.
Random Input 2:

Food : indomie lodeh
Ingredients :
1 bungkus indomie goreng
1 / 2 kg toge (sprouts)
1 / 2 kg kacang tanah (peanuts)
1 / 2 kg bawang bombay (onion)
1 / 2 kg cabe merah (red chili)
1 / 2 ons cabe rawit (cayenne pepper)
1 / 2 ons cabe merah (red chili)
1 / 2 sdt garam (salt)
1 / 2 sdt gula (sugar)
1 / 2 sdt merica bubuk (pepper powder)
1 / 2 sdt penyedap rasa (flavoring)
1 / 2 sdt gula pasir (granulated sugar)
For anyone who wants to know what lodeh is:
Sayur lodeh
Sayur lodeh is an Indonesian vegetable soup prepared from vegetables in coconut milk popular in Indonesia, but most…
en.wikipedia.org
Indomie is a popular instant noodle in Indonesia. You should have already known it.
FYI, I think no one combines Lodeh with Indomie, maybe someone wants to try with these ingredients? U+1F61C
Random Input 3
Food : sop nasi goreng (FRIED RICE SOUP)
Ingredients:
1 piring nasi putih (rice)
1 buah wortel (carrot)
1 buah kentang (potato)
1 buah tomat (tomato)
1 buah bawang bombay (onion)
2 siung bawang putih (garlic)
1 / 2 sdt lada bubuk (ground pepper)
1 / 2 sdt garam (salt)
1 / 2 sdt kaldu bubuk (broth powder)
1 / 2 sdt bubuk (any powder? LOL)
1 / 2 sdt minyak goreng (cooking oil)
FRIED RICE WITH SOUP! U+1F630
In Indonesia, it is an anti-mainstream food (Or is it just me?). Does anyone want to try?
Colab Link:
Here is the collaboratory link for anyone who wants to try generating ingredients. It will use my own best transformer model that I have trained. If you wish, you can comment here about the food ingredients that you generate U+1F603.
Google Colaboratory
Edit description
colab.research.google.com
Conclusion
This article has shared how to make a recipe (ingredient) brewer, a project that I have done in my free time. It also tells you about the technology behind it and how to implement it. The article also tells you what is the best deep learning architecture between GRU and Transformer in almost the same parameters. The experiment shows that the Transformer win over GRU. After that, this article also tries to generate some nonsense foods ingredients.
I hope that it can make you understand better on implementing the seq2seq deep learning system and motivate you to do some fun project and share it with everyone. 🙂
Afterwords
Finally! I am able to write an article again. It’s been surely a long time. FYI, I wanted to write this article several ago. But with my life goes on, it got sidetracked, and I forgot about it. Not a long ago, I do self-evaluation. I evaluate that I have not written any articles lately, which is one of the ‘medium’ for me to share something. Love is caring, you know. Voila, here is the article!
So, I hope that I can continuously write more articles. I want it to become my habit again to share my knowledge. I want my knowledge to not only stay in my brain but to flow with other people and help them achieve something.
If you are wondering why my article is so long. Well… I didn’t think that my article gets this long, and when I realize it, well it’s okay… The more information that I write, the better it is. Actually, I can shorten my article to become 5–10 minutes. I want to give you the most detailed information about my fun project to understand it better.
Anyway, if you find that my article needs improvement, you can send feedback by commenting on it or emailing me. I have shared my email in my repository. I love the feedback!
If you are interested in my article and want to follow, FYI my article will be mainly about Self Development and AI (Especially Deep Learning). You can follow me if you are interested in these fields :).
Thus,
I welcome any feedback that can improve myself and this article. I’m in the process of learning on writing and learning to become better. I apreciate a feedback to make me become better.

Sources
BLEU
BLEU ( bilingual evaluation understudy) is an algorithm for evaluating the quality of text which has been…
en.wikipedia.org
PyTorchLightning/pytorch-lightning
READ THIS QUICK START PAGE System / PyTorch ver. 1.3 (min. req.) 1.4 1.5 (latest) Linux py3.6 [CPU] Linux py3.7 [GPU] …
github.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

