



GNNs to Data Augmentation to Building Distributed Applications at Scale with Open-source
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
AI news, research, and updates, an exciting and free-to-attend AI summit, and our monthly editorial picks!
If you have trouble reading this email, see it on a web browser.
The open-source AI community is seeing rapid growth. Open-source projects like TensorFlow, Theano, Caffe, BERT, MXNet, PyTorch, Gluon, and PyStanfordNLP are among the ones helping make AI accessible to everyone. To get you even more excited about scalable AI, check out this excellent and free-to-access event, presented by Anyscale:
Ray Summit brings together developers, data scientists, architects, and product managers to build scalable AI using Ray, the dominant framework for distributed computing. Topics include top AI trends, ML in production, MLOps, reinforcement learning, cloud computing, serverless & more. Register free to join live or on-demand.
Most commonly used implementations of GNNs in practice use a node-wise thresholding strategy to protects sensitive information (e.g., emails, phone numbers, street addresses, etc.). This approach is vulnerable to information leakage attacks on social networks. Researchers from MIT, Carnegie Mellon, and UIUC led by Peiyuan Liao propose a new algorithm graph adversarial network (GAL) with minimax games to protect such sensitive information.
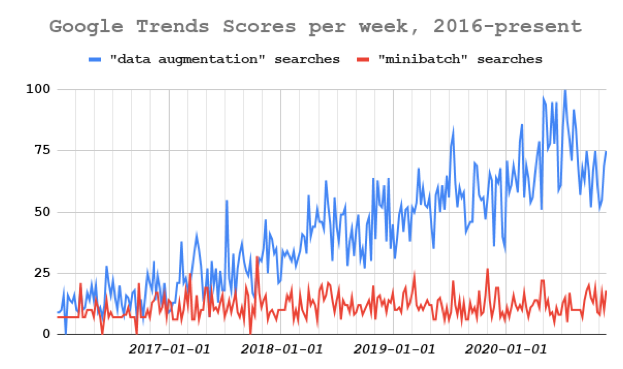
In the field of Natural Language Processing (NLP), data augmentation comes at a premium. Improving model performance by relying on auxiliary datasets is a proven tactic in many NLP subfields. However, it is by no means an “easy” problem. Check out this paper led by researchers at Google, Carnegie Mellon, and Mila — Quebec AI exploring state-of-the-art techniques used for data augmentation approaches (DAA).
Next, it is common in the supervised machine learning literature to assume that early learning implies generalization: to develop a system that performs well on the early part of the training set will result in extrapolation to unseen or future data. This paper led by Saurabh Garg with Machine Learning at CMU presents results that show this hypothesis is true for a wide variety of models and problem types: the work shows that early learning is key to understanding generalization.
Now, let’s face it. AI systems are often opaque, strange, and difficult to use. In the field of machine learning, this is particularly true. If we want to make intelligent systems that people can understand and interact with — more easily, a key part of the solution is a community where people can come together, share ideas and learn from each other. That is why we created our AI community on Discord — to connect and learn with other data experts and enthusiasts.
If you have not checked it out yet, we recently launched our book on descriptive statistics with Python. This article or this PDF provides a sample of the first 36 pages of the book. Please don’t forget that you can access this work, many more books, and other goodies by becoming a member.
Sharing is caring. Please feel free to share our newsletter or subscription link with your friends, colleagues, and acquaintances. One email per month; unsubscribe anytime! If you have any feedback on how we can improve, please feel free to let us know.
Now into the monthly picks! We pick these articles based on readers, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top-performing articles, and our editors will choose a couple of essays that didn’t have outstanding performance, but due to their quality — they made the cut for the month.
📚 Editor’s choice featured articles of the month ↓ 📚

State of the Art Models in Every Machine Learning Field 2021 by Mostafa Ibrahim
State-of-the-art models keep changing all the time. As someone who has been doing Kaggle competitions for almost a year now, I find myself coming across many of them, making comparisons, evaluating, and testing them. I thought it would be a good idea to list the best models for each ML task so that you know where to start. Without further ado, let’s get started!
[ Read More ]
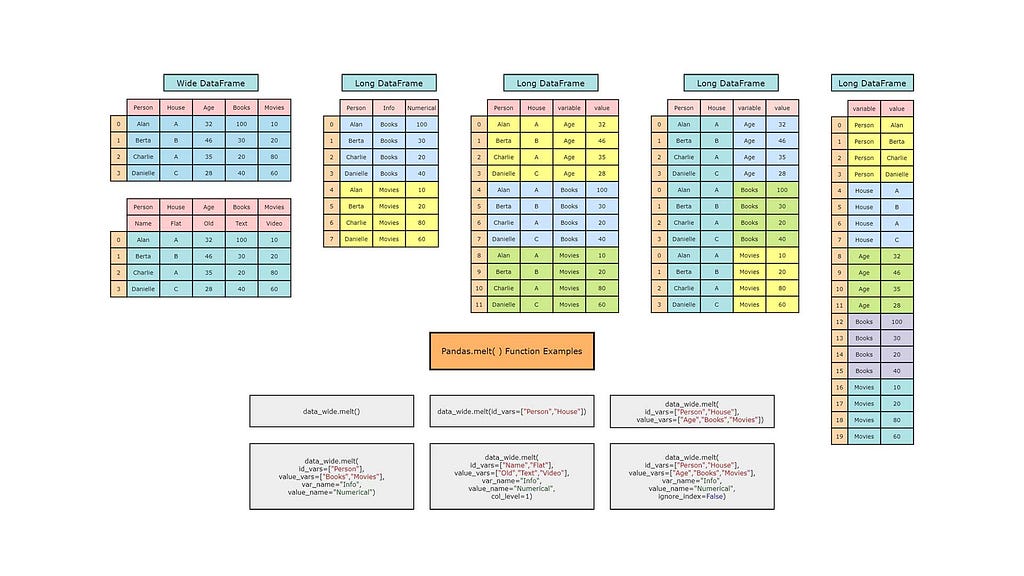
Understanding Pandas Melt — pd.melt() by Towards AI Team
The Pandas melt() function is within many other methods to reshape the pandas DataFrames from wide to a long format, particularly in data science. However, the pd.melt() function is the most efficient and flexible among them. The pd.melt() function unpivots/melts the pandas DataFrame from a wide to a long format.
[ Read More ]
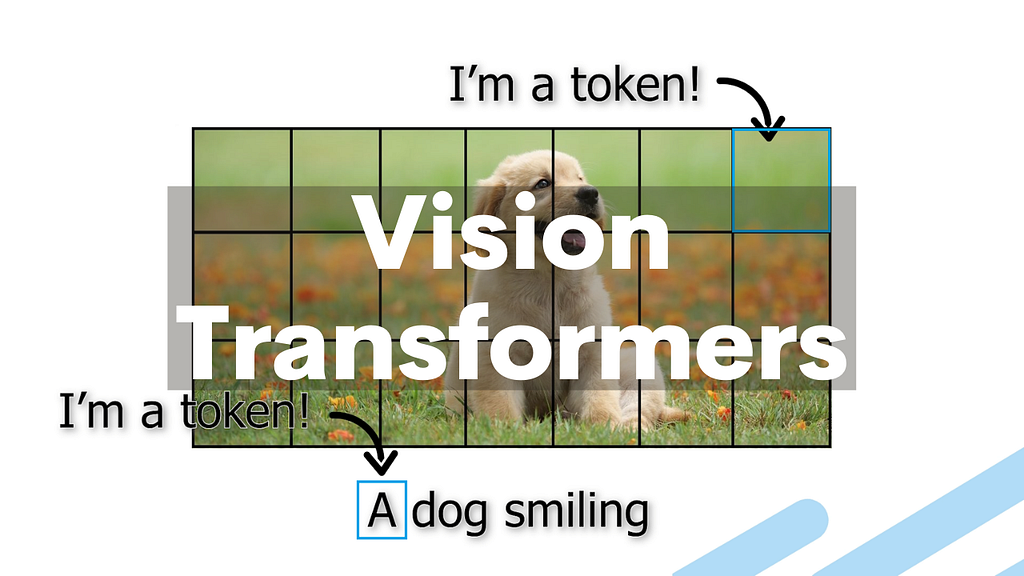
Will Transformers Replace CNNs in Computer Vision? by Louis (What’s AI) Bouchard
This article is about most probably the next generation of neural networks for all computer vision applications: The transformer architecture. You’ve certainly already heard about this architecture in the field of natural language processing, or NLP, mainly with GPT3 that made much noise in 2020. Transformers can be used as a general-purpose backbone for many different applications and not only NLP. In a couple of minutes, you will know how the transformer architecture can be applied to computer vision with a new paper called the Swin Transformer by Ze Lio et al. from Microsoft Research [1].
[ Read More ]

My VS Code Setup To Prototype Algorithmic Trading Strategies Locally Using LEAN by ___
This article represents documentation on my VS Code setup to develop algorithmic trading strategies using QuantConnect’s LEAN engine on a local machine. It is an alternative to using the QuantConnect Lean CLI tool. All the code and scripts to reproduce the results described in this article can be found in this repo.
[ Read More ]
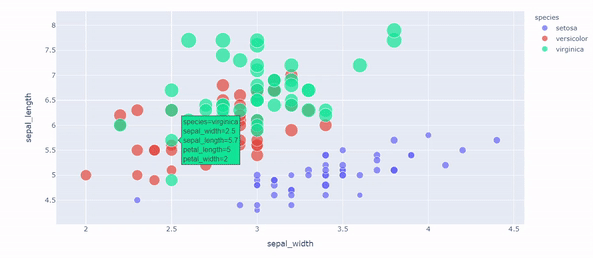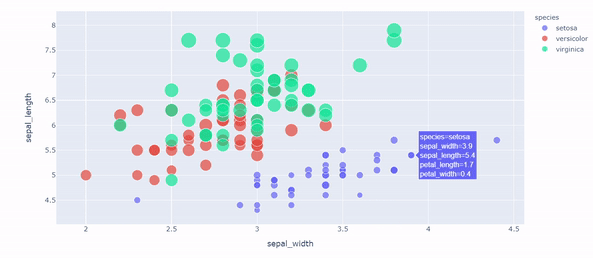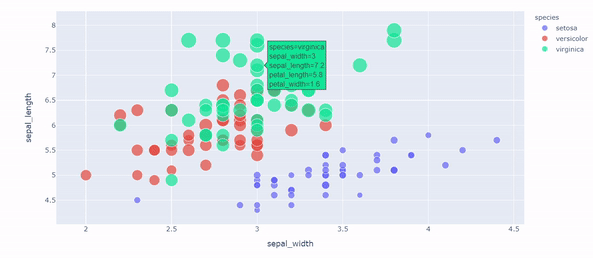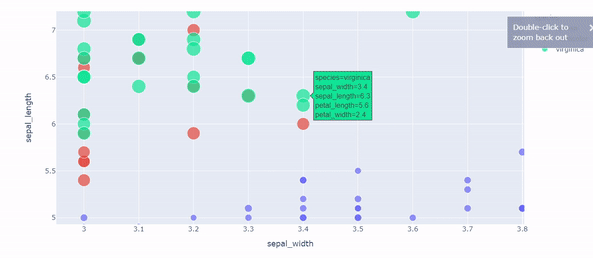
Plotly Express: Interprete data through interactive visualization by Eugenia Anello
It’s the right moment to move forward to other tools to visualize your data. Do you know Matplotlib? Forget it. Maybe it can be easy to apply and doesn’t occupy much memory, but it’s hard to observe the change of features over time from static graphs.
[ Read More ]

Complete List of Feature Engineering Methods: 40 Techniques, 10 Categories by Michelangiolo Mazzeschi
In reality, feature engineering becomes vital when you start transitioning into Big Data. Big Data analytics is and will always remain in high demand because, as of now, there is almost no way you can learn how to work on a gigantic dataset on your own. The only way to start approaching big data is with a team of experts in the working place. It is the real all-hands-on-deck experience of data science.
[ Read More ]

How to Use Analytical Geometry to Find the Shortest Route/Loop for Any Euclidean Travelling Salesman Problem Efficiently by Ashutosh Malgaonkar
“The traveling salesman problem (also called the traveling salesperson problem[1] or TSP) asks the following question: “Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?” It is an NP-hard problem in combinatorial optimization, important in theoretical computer science and operations research…
[ Read More ]
DeepMind Combines Logic and Neural Networks to Extract Rules from Noisy Data by Jesus Rodriguez
In his book “The Master Algorithm,” artificial intelligence researcher Pedro Domingos explores the idea of a single algorithm that can combine the significant schools of machine learning. The idea is, without a doubt, extremely ambitious, but we already see some iterations of it. Last year, Google published a research paper under the catchy title of…
[ Read More ]
Understand Time Series Components with Python by Amit Chauhan
In this article, we will discuss time series concepts with machine learning examples that deal with the time component in the data. Forecasting is essential in the banking sector, weather, population prediction, and many more that directly deals with real-life problems.
[ Read More ]

Data Versioning for Efficient Workflows with MLFlow and LakeFS by Giorgos Myrianthous
Version Control Systems, such as Git, are essential tools for versioning and archiving source code. Version Control helps you keep track of the changes in the code. When a change is made, an error could be introduced, too, but with source control tools, developers can roll back to a working state and compare it against the non-working piece of code. This minimizes the disruption to other team members that are probably working with the code and helps them collaborate efficiently.
[ Read More ]

Understand Bayes’ Theorem Through Visualization by Satsawat Natakarnkitkul
When we get started in our machine learning journey, we often asked ourselves whether we should learn statistics and probability or not, especially probability. The answers depend on where you are and how much depth you want to get yourself into understanding it. However, keep these in mind…
[ Read More ]

7 Awesome Jupyter Utilities That You Should Be Aware Of by Yash Prakash
Jupyter Notebooks are considered to be the backbone of any data science experiment and for a good reason. They allow for interactive, literate programming that no other platform provides. In this short article, I share a few tips and tricks that I frequently use while coding data science projects in notebooks.
[ Read More ]

Fastai Course Chapter 3 Q&A on Linux by David Littlefield
The third chapter of the textbook provides an overview of ethical issues that exist in the field of artificial intelligence. It provides cautionary tales, unintended consequences, and ethical considerations. It also covers biases that cause ethical issues and some tools that can help address them.
[ Read More ]
Make Your Dashboard Stand Out — Tile Map by Memphis Meng
To me, Tableau is the only kind of tool that allows me to do data science as an artist. However, there will be no fun if everyone does the exact visualization with Tableau. This article is one episode of my series “Make Your Dashboard Stand Out,” which provides you with some brilliant but not default visualization ideas. If you are new to me, do check out the following articles…
[ Read More ]

Generating Cool Storylines Using a T5 Transformer and Having Fun by Vatsal Saglani
The folks at Google AI published a paper “Exploring the Limits of Transfer Learning with a Unified Text-To-Text Transformer” and presented an empirical study on what type of pre-training approaches or transfer learning techniques work the best and then used that study to create a new model, i.e., the Text-To-Text Transformer (T5). This transformer model was pre-trained on a much cleaner version of the Common Crawl Corpus, and Google named it the Colossal Clean Crawled Corpus (C4)…
[ Read More ]
- Sponsors | Learn How to Become a Sponsor with Towards AI
- Towards AI
- Join us ↓ | Towards AI Members | The Data-driven Community
🙏 Thank you for being a subscriber with Towards AI! 🙏
Follow us ↓
[ Facebook ] |[ Twitter ]| [ Instagram ]| [ LinkedIn ] | [ Github ] | [ Google News ]
GNNs to Data Augmentation to Building Distributed Applications at Scale with Open-source was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts
")



")


