



Breakthrough: Can Giving Memory to Entire Neural Nets be Revolutionary?
Last Updated on March 3, 2021 by Editorial Team
Author(s): Joy Lunkad
What is it?
This can be best explained with a very straightforward and simple example.
Imagine if the AI is a student going through a book(dataset) and preparing for a test. All I am doing here is I tried giving it a notebook to write down whatever it thinks is important.
A question that bothered me while learning about AI was what would happen if someone gave memory to the entire Neural Net? It sounds like it’s pretty obvious that it would work, right? I did just that and I am going to share with you, in detail, how I did it, how it works and the most important question of all, Does it work?
Does it work?
The short answer : YES
I decided to train a standard ResNet50 as my base on the Stanford Dogs dataset and then added some memory to the exact same architecture, and trained it exactly in the same way as ResNet50.
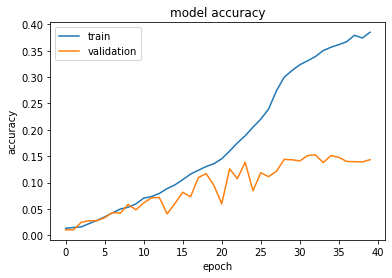
This is how Standard ResNet50 performed, the highest the model reached was 15.14% accuracy on test data. The training was stopped on the 40th epoch since the validation accuracy didn’t increase in 7 epochs.
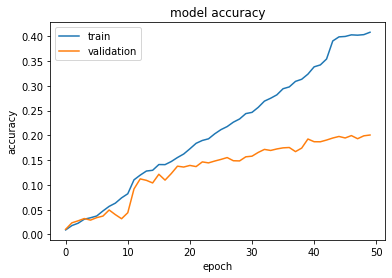
And this is how the same AiM ResNet50 performed (AiM comes from Memory for Artificial intelligence). I only let it run till the 50th epoch. On its fiftieth epoch, it scored 20.06% accuracy on the test data and it still had potential to go further ahead.
This is just a guess but looking how the validation accuracy of the AiM ResNet50 does not fluctuate that much and just steadily rises, doesn’t it look like not only it can learn more, but also it doesn’t make that many mistakes in learning things from the dataset.
A ResNet50 has approximately 23.8 million parameters.
An aim-ResNet50 with a memory size of about 50,000 floats (which was used in the experiment above), has approximately 24.1 million parameters.
How it works?
What my goal while making AiM was –
- Every Layer/Neuron/Unit should have a way to access the memory.
- The Neural Network should have a way to update the memory.
- The new updated memory should be passed on to next batches.
The way I implemented this was I decided to have a layer of ‘memory’ and pass that layer, along with the output of the previous layer, to the next layer, for every layer in the model. I also made update blocks for the “memory layer” so that the second condition is satisfied. The weights and the bias of this layer gave me a way to pass it on.
How I did it?
For CNNs, I used a conv2D layer for my memory. By passing an array of the 1s as input to this layer with a linear activation, the values passed on forward will be just weights and biases. Hence, it can function as a memory layer.
If this memory layer has the same number of rows and columns as the smallest convolutional layer in the architecture, it can be reshaped and concatenated to Input layer and also outputs from other layers without a problem.
When the n_rows * n_columns of other convolutional layers exceed the total memory of the memory layer (n_rows * n_columns * number of channels) the memory can reshaped and padded with zeros into one channel and then, it can be concatenated to the input that layer was already receiving.
And just like that by reshaping and padding, this memory layer can be concatenated to almost all inputs.
Passing this memory layer through a convolutional block along with some other data/features can update the memory layer.
For Fully connected neural networks this is even easier to do, as we just use a dense layer for a memory layer. Again, by passing it, an array of 1s as input and using linear activation, we can use the weight + bias as a unit of memory. This memory layer can then be concatenated with the input for each layer to get a neural network with memory.
How versatile is it?
Just one look at the method with which it is implemented, it’s easy to conclude that, memory can be added to most CNNs and Fully Connected Neural Network architectures with minimal changes. I have tested adding memory to ResNet50 and VGG16 and if it improves their performance, there is a good chance that this might actually improve almost every single deep neural network architecture out there.
Conclusion
I have high hopes for this seemingly simple yet effective idea. Though this experiment is crude and has room for lots of improvement, I wanted, with this post, to bring your attention to this proof of concept.
I love how the deep learning community is so supportive and helpful. So many papers and codes and helpful blog posts and notebooks are out here for free, I thought the best way to give back, would be to make this public.
I would love to hear your opinions on my work and I can’t wait to see how the deep learning community develops this idea further.
To get to know more about me and contact me
Breakthrough: Can Giving Memory to Entire Neural Nets be Revolutionary? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")