



Enterprise-grade NER with spaCy
Last Updated on October 19, 2020 by Editorial Team
Author(s): Shubham Saboo
Natural Language Processing
Build Industrial strength Named Entity Recognition (NER) applications within minutes…
Named Entity Recognition is one of the most important and widely used NLP tasks. It's the method of extracting entities (key information) from a stack of unstructured or semi-structured data. An entity can be any word or series of words that consistently refers to the same thing. Every detected entity is classified into a predetermined category. For example, a NER model might detect the word “India” in a text and classify it as a “Country”.
Many popular technologies that we use in our day-to-day life such as smart assistants like Siri, Alexa are backed by Named Entity Recognition. Some other real-world applications of NER include ticket triage for customer support, resume screening, empowering recommendation engines. Here is an example of NER in action:

Now whether you are new to NLP or have some prior knowledge, spacy has something for everyone. It caters to all ranges of audiences starting from beginner to advance. Now let's understand the what, why, and How part of spacy.
What is spaCy?
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) with native support for Python. It's becoming the de-facto choice for data scientists and organizations these days to use a pre-trained spacy model for production-level NER tasks rather than training a new model from scratch in-house.
If you’re working with a lot of text, you’ll eventually want to know more about it. For example, what’s it about? What do the words mean in context? Who is doing what to whom? What companies and products are mentioned? Which texts are similar to each other? … spaCy is there to answer all your questions
spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems or to pre-process text for deep learning.
spaCy is fast, accurate and user-friendly with a mild learning curve…
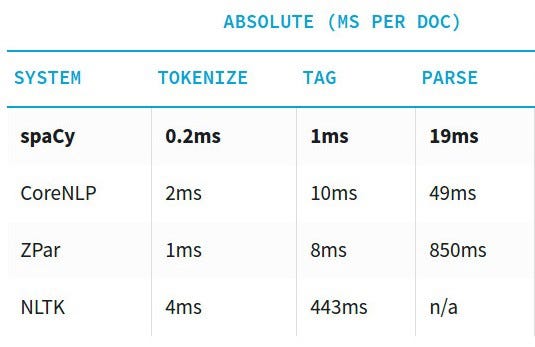
Why spaCy?
spacy comes up with its own in-built features and capabilities. It has a collection of pre-trained models in many global languages which can be simply installed as a python package. These packages become the component of the application, just like any other module. They’re versioned and can be defined as a dependency in your requirements.txt file.
Following are the features of spacy that sets it way apart from any of its potential competitors:
- Preprocessing: It consists of a pre-defined tokenizer, lemmatizer, and dependency parser to automatically preprocess the input data.
- Linguistic Feature: It also has a state-of-the-art Part of Speech tagger that automatically associates POS tags with each word.
- Visualization: It has the capability of visualizing the dependency trees and create beautiful illustrations for the NER task.

- Flexibility: It has the flexibility to augment or replace any pipeline component or add new components such as TextCategorizer.
- Transfer Learning: It provides the user with the feasibility to pick up any pre-trained model and fine-tune it on the downstream tasks.
- Pipeline: Spacy comes up with an in-built feature for creating a processing pipeline that automates the processing of raw text and generates a spacy recognized doc object, which can be used for a variety of NLP tasks.
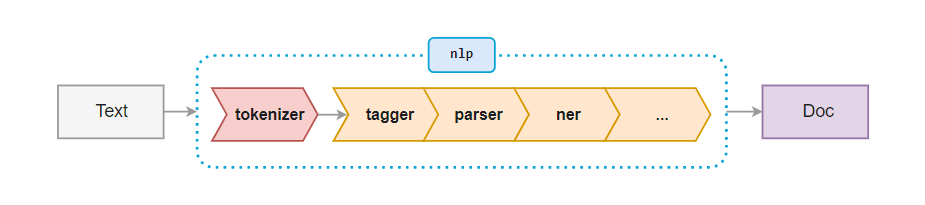
spaCy in Action
spaCy is available as a standard python library at PyPI, which can be easily installed using either pip or conda depending on the python environment. Following are the commands for installing spacy:


Now let’s explore how we can efficiently perform named entity recognition with spacy. For that, we need to download a pre-trained language model that comes pretty handy with spacy. As we saw earlier spacy supports multiple languages, but we will restrict ourselves to just english language. There are three variants of english language models i.e small, medium, and large that are currently present in spacy.
All of them starts with the prefix en_core_web_* and are loaded with pre-defined tokenizer, tagger, parser, and entity recognizer components. As a general trend, the accuracy of the language model increases with model size. Here we will load the large variant of english language model.

After loading the model into an nlp object which now has a tokenizer, tagger, parser, and entity recognizer in its pipeline. The next step is to load the textual data and process it using the different components of the nlp object.
For downstream/domain-specific tasks spacy also provides us with the feasibility to add custom stopwords along with the default stopwords. In spacy the stop words are very easy to identify, where each token has an IS_STOP attribute, which lets us know if the word is a stopword or not.

POS- Tagging
Part-of-speech (POS) tagging is the process of tagging a word with its corresponding part-of-speech like a noun, adjective, verb, adverb, etc by following the language’s grammatical rules that are further constructed based on the context of occurrence of a word and its relationships with other words in a sentence.
After tokenization SpaCy can tag a given sent object using its state-of-the-art statistical models. The tags are available as an attribute of a Token object. The code below shows tokens and their corresponding P.O.S tags parsed from a given text using SpaCy.

output:
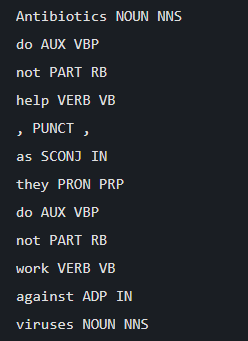
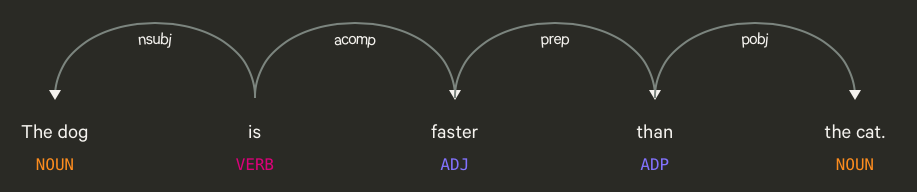
Visualizing Parts-of-Speech
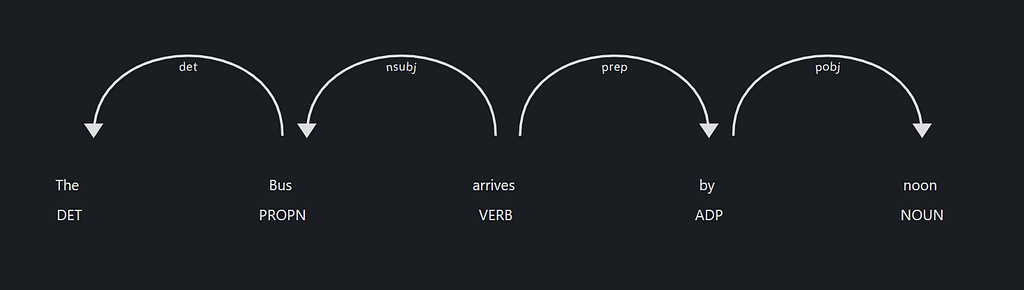
spaCy comes with a built-in dependency visualizer called displacy, which can be used to visualize the syntactic dependency (relationships) between tokens and the entities contained in a text.
output:
Named Entity Recognition:
A named entity is a real-world object with a proper name – for example, India, Rafael Nadal, Google. Here India is a country and is identified as GPE (Geopolitical Entity), Rafael Nadal is PER(person), Google is an ORG (Organization). SpaCy itself offers a certain predefined set of entities. NER-tagging is not the result, it ends up being helpful for further tasks.
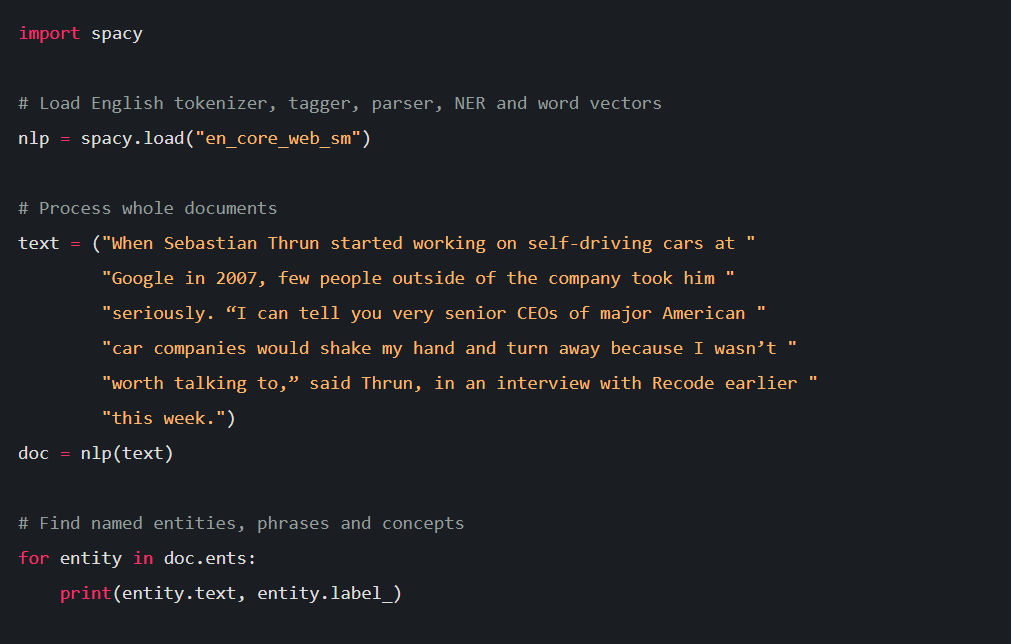
output:
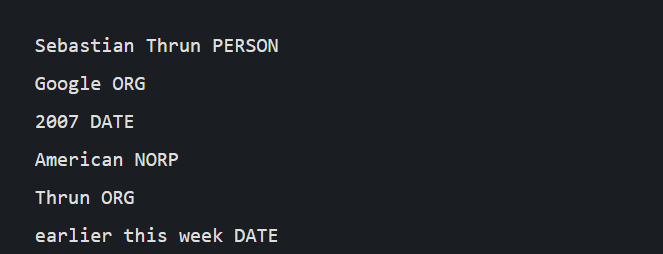
spaCy also comes with a spiffy way of visualizing the NER-tagging task using displacy, which provides us with an intuitive way to visualize the named entities…

output:

Conclusion
Today when many fortune 500 organizations are venturing into AI, ML, and NLP. spaCy is leading the way for organizations to leverage natural language processing for their downstream tasks. spaCy is user-friendly and can be learned with zero to minimal effort by someone already familiar with the field. It is becoming a de-facto choice for data teams to incorporate spaCy in building state-of-the-art, production-ready NLP applications within no time.
If you would like to learn more or want to me write more on this subject, feel free to reach out…
My social links: LinkedIn| Twitter | Github
If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post visibility for other medium users.
Enterprise-grade NER with spaCy was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts



Recent Posts






")