



Implementing FaceID Technology with a Siamese Neural Network
Last Updated on October 10, 2020 by Editorial Team
Author(s): Vasile Păpăluță
Machine Learning
Understanding more weird networks.
Face ID is a technology, that allows devices to give access tho themselves only to allowed identities. It uses this looking at the person’s face and if it is recognized as a person with access, the systems give it. For a long time, it was implementing throw different technologies, but nowadays after the massive development of the ANN and achieving high performance in computer vision by CNNs, the Neural Network has become a more attractive way to do that.
First Way — simple CNN.
The most straightforward way to do that would be to build a simple CNN that would classify the user’s face as the ‘owner’/’non-owner’ of this device. However, this implementation has some drawbacks.
- It takes a lot of time and computing power to train a neural network, especially CNN.
- CNN should be trained for every person separately.
So the user wouldn’t buy a device If he/she must wait for 3 to 5 hours to train the model that would recognize himself. Also, it takes a lot of images. Image how the user must take around 1000 selfies of him/herself for face recognition.
First Way — 2 head neural networks.
The second way is to take a harder Neural Network Architecture — Double-headed Neural network. The idea is pretty simple. The network takes 2 images, one saved in the device of the owner and one from the camera. And CNN should classify them as the ‘same’/’non-same’ or give a rank.
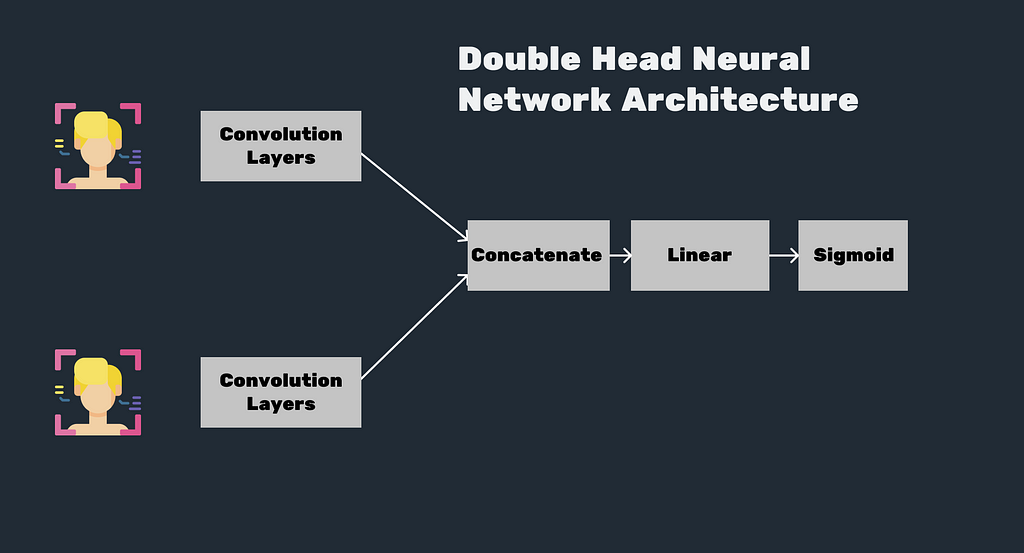
Even if this architecture is a better approach it also has it’s limitations.
- It may not work in all cases, even it was trained on a lot of different people’s images.
- Also, It can be computing and time consuming, even if CNN would be trained on a server and not on the end-device.
So we need a better approach.
Siamese neural network
Siamese neural network (or shortly SNN) is actually a simple CNN that requires a little bit of different way to train. In almost all networks we are splitting our dataset into some batches ant the loader is sending them to the network. SNNs are using a method named triplet training. So how it works.
Basically, we need 2 types of images, the ‘owner’s face’ photos, and other ‘non-owners face’ photos, usually random photos of persons. During the creation of the dataset, we are creating from these images triplets, 2 different photos of the same person, and one of a random person. The code below is showing the Dataset class implemented in PyTorch.
# Defining the Dataset
class SNN_Dataset(data.Dataset):
def __init__(self, root, ME_DIR, NOT_ME_DIR):
self.root = root
ME_PATHS = listdir(ME_DIR)
NOT_ME_PATHS = listdir(NOT_ME_DIR)
ME_PATHS = [join(ME_DIR, img_path) for img_path in ME_PATHS]
NOT_ME_PATHS = [join(NOT_ME_DIR, img_path) for img_path in NOT_ME_PATHS]
ME_PAIRS = list(itertools.permutations(ME_PATHS, 2))
self.TRIPLETS = list(itertools.product(ME_PAIRS, NOT_ME_PATHS))
self.TRIPLETS = [list(triplet) for triplet in self.TRIPLETS]
for i in range(len(self.TRIPLETS)):
self.TRIPLETS[i] = list(self.TRIPLETS[i])
self.TRIPLETS[i][0] = list(self.TRIPLETS[i][0])
self.TRIPLETS[i][0].append(self.TRIPLETS[i][1])
self.TRIPLETS[i].pop(-1)
self.TRIPLETS[i] = self.TRIPLETS[i][0]
random.shuffle(self.TRIPLETS)
def __getitem__(self, index):
img_triplet = [Image.open(img).convert('RGB') for img in self.TRIPLETS[index]]
img_triplet = [transforms.Scale((244, 244))(img) for img in img_triplet]
img_triplet = [transforms.ToTensor()(img) for img in img_triplet]
return img_triplet[0], img_triplet[1], img_triplet[2]
def __len__(self):
return self.TRIPLETS
The network is taking every image from the triplet and calculates the linear representation of the images. From the linear algebra point of view, neural networks are actually a very big and complex linear and non-linear transforms. So every output of the ANN is a linear representation of the input. After taking the linear representation, the output goes to the formula below. If the linear representation of the first to images are near each-other (the euclidean norm is low) and the linear representation of the first and the last image is far away (the euclidean norm is high) then the value of the first term of the max function, before adding alpha would be negative. So, when alpha is 0, if the first images are of the same person the of this formula will be 0. The why we need alpha in the formula.
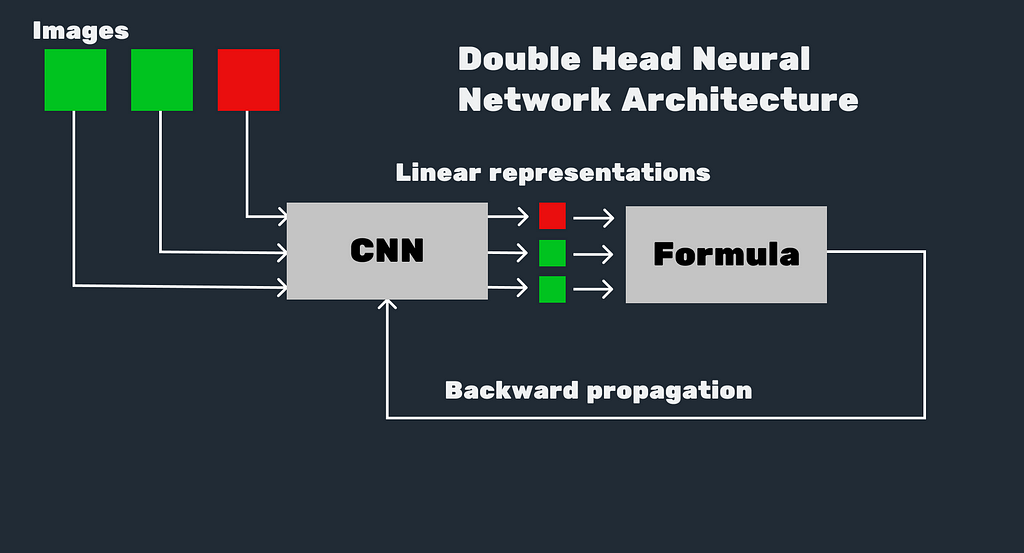
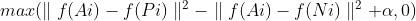
Alpha can be interpreted as a parameter (from -1 to 1) that sets up the sensitivity of the network. So the higher the sensitivity, the lower norm between the same person images it will require, and vice versa. Also If you have a lot of images you can set alpha to a higher value, and when you have fewer to a smaller even negative.
When I trained the network on my images, a set the alpha to 0.5 and using 7 images of me and 10 random images it took 5 hours to train the network (I used combinations to generate the dataset) on a PC with 8 cores. However, when I trained the network on images of one of my colleagues using only 2 images of the person and 5 random images, it took no more than 15 minutes to train the network, but it also took a lower alpha, even negative. So you can train a network with a high value of alpha to push the network to learn better, and lower it on the production phase.
For backpropagation is used the value gotten from the formula.
And here are the results.
Note: VASILIKA — means a caress for my name — Vasile.
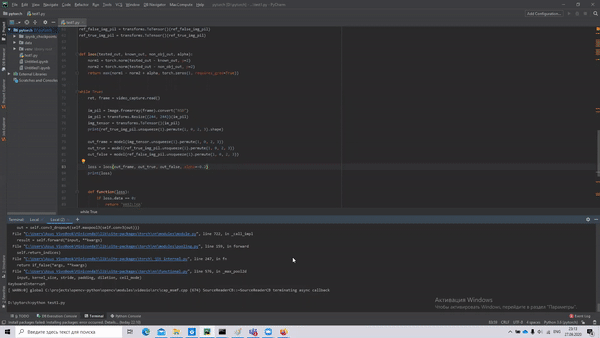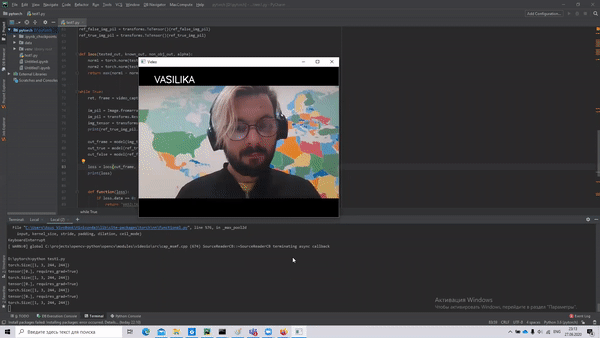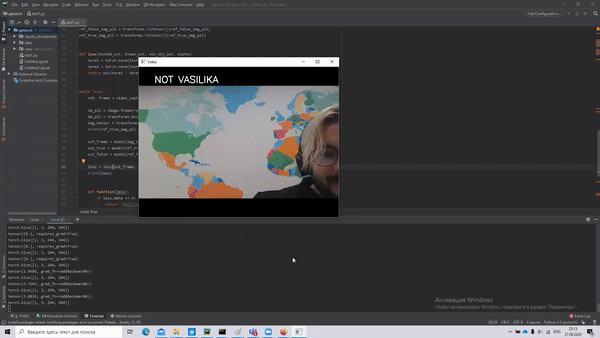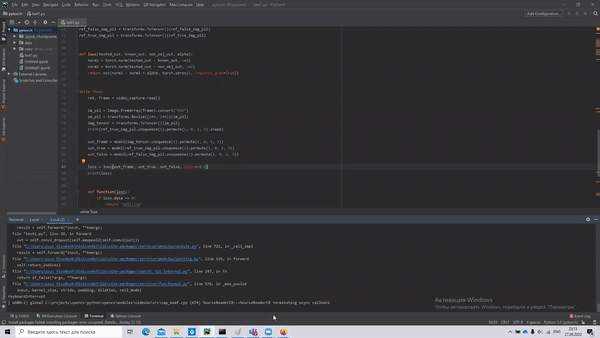
The code repository: https://github.com/ScienceKot/SNN.git
The inspiration — Andriy Burkov the hundred-page machine learning book
Implementing FaceID Technology with a Siamese Neural Network was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

