



Deep Insights Into K-nearest Neighbors
Last Updated on July 26, 2020 by Editorial Team
Author(s): Palak
Machine Learning
Introduction
K-nearest neighbors(in short KNNs) are a robust yet straightforward supervised machine learning algorithm. Though its regression variant also exists, we’ll only discuss its classification form.
KNN is a non-parametric lazy learning algorithm. Let’s have a look at what each term means —
- Non-parametric: Unlike the parametric models, the non-parametric models are more flexible. They don’t have any preconceived notions about the number of parameters or the functional form of the hypothesis. They are thus saving us from the trouble of any wrong assumption about the data distribution. For example, in Linear Regression, which is a parametric algorithm, we already have a form of a hypothesis, and during the training phase, we look for its correct coefficient values.
- Lazy learning: Also known as instance-based learning. Here the algorithm doesn’t explicitly learn a model, rather chooses to memorize the training set so to be used during the prediction phase. This results in the fast training phase, but expensive testing phase as it requires storing and traversing the whole dataset.
Intuitive Approach
The basic idea behind this algorithm is — Birds of a feather flock together, i.e., similar things occur nearby, wondering why something like this even holds?
Well, try imagining a large number of data points in a D dimensional space. It’s not wrong to conclude the subspace will be densely filled, which implies two fairly close points are more likely to have the same label. Indeed there exists a tight error bound on this algorithm —
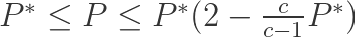
where P* is the Bayes error rate, which is the lowest possible error rate for any classifier, c is the number of classes, and P is the error rate of our algorithm. According to the above equation, if the number of points is fairly large, then the error rate of the algorithm is less than twice the Bayes error rate. Pretty cool!
Don’t get me wrong. By a large number of data points, I don’t mean a large number of features. Rather the algorithm is particularly susceptible to the curse of dimensionality, meaning an increase in the dimension(number of features) will lead to an increase in the volume of hyperspace required to accumulate a fixed number of neighbors. And as the volume increases, the neighbors become less and less similar because the distance between them increases. Therefore the probability of points having the same label decreases. In those cases, feature selection might come handy.
What does KNN do?
The KNN algorithm takes a test input, compares it with every single training example, and predicts the target label as the label that is most often represented in the k most similar training examples. The similarity between two data points is usually measured using Euclidian distance.
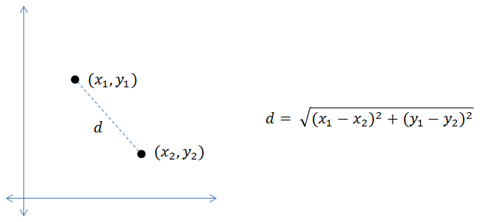
When k = 1, the target label is predicted as the label of the nearest training example.
Since we store and traverse the whole training set for every test example, the testing phase is costly in terms of both memory and time.
What is k in kNN?
K is the hyperparameter, whose value controls the learning process. It is the number of neighbors considered for predicting testing examples’ label.
Does the value of k affect our classifier?
Before addressing the above question, Let’s understand what we mean by overfitting and Underfitting.
In supervised learning, we want to build a model that learns from our training set and makes reasonably accurate predictions on unseen data. This ability of our model to learn enough to apply is called generalization.
Intuitively we expect simple models to generalize better. The complex model fits the peculiarities of the data, rather than summarising the underlying biology. They might perform accurately on training data but usually fails to generalize over testing data.
Overfitting occurs when a model fits closely to the peculiarities of the training set but is not able to generalize on new data.
Whereas Underfitting occurs when a model is too simple and fails even on the training set.
Let’s have a look at what it’s like to consider one nearest neighbor and 20 nearest neighbors —
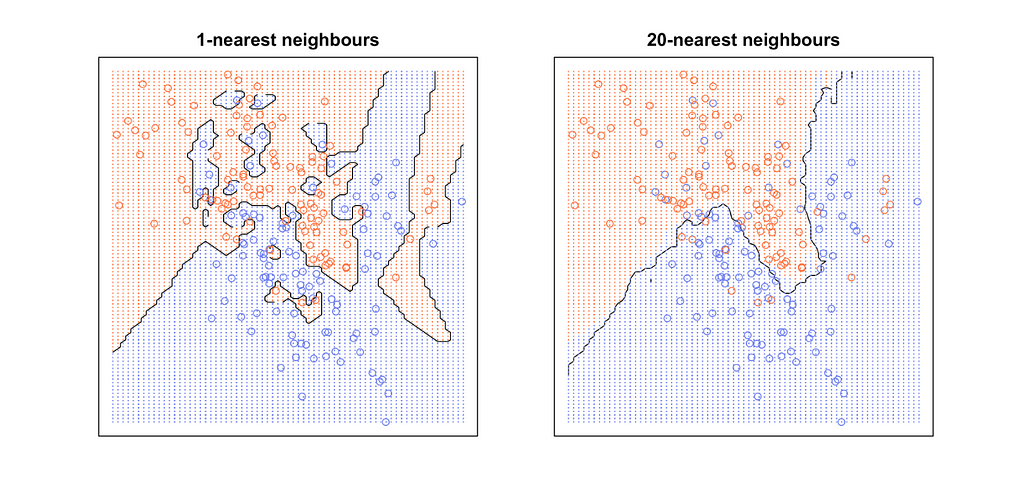
It can be observed from the above image, k = 1 leads to jagged boundaries, while k = 20 gives us a smooth boundary.
Smooth boundaries correspond to a simple model, whereas the jagged boundaries correspond to a complex model. Therefore if we keep the value of k low, we risk ourselves of overfitting, while if we keep the value of k high, we risk ourselves of Underfitting.
So an obvious solution is to keep k such that it’s not too small and not too large. Maybe try evaluating with different values of k and pick what works best.
Well, this is what we’ll do, but a tad smartly.
Validation for Hyperparameter Tuning
As decided earlier, we will try out different values of k but not on the testing set. The testing set should not be used until one time at the very end. Using it before causes us of the trouble of overfitting the testing set and thus unable to generalize on unseen data.
A way around this is to hold out a subset of the training set for tuning the hyperparameter. This set is called a validation set.
In case when the training set is small, a more sophisticated technique is cross-validation. Here we split the training set into x groups, say 5. We’ll use 4 of them for training and one for validation. With each iteration, we use another group as a validation set. Finally, the average performance is used for figuring out the best value of k.

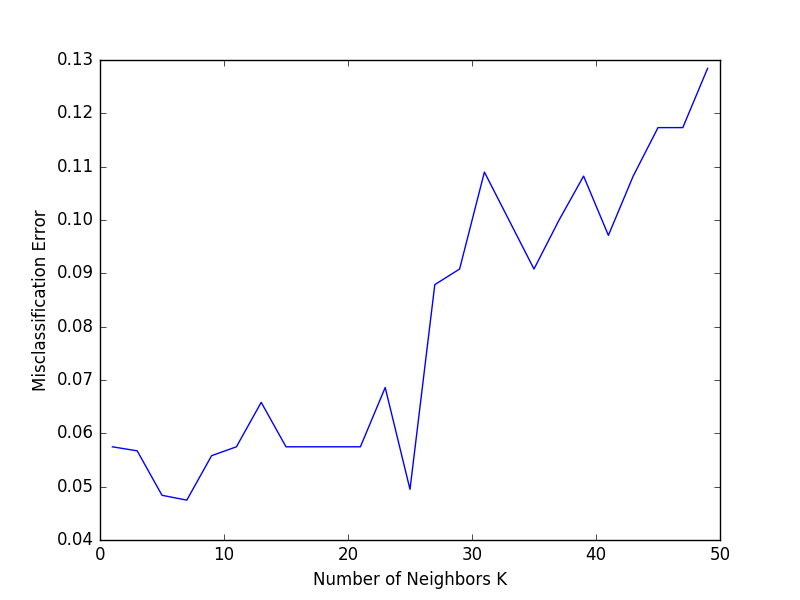
In the above image, k = 7 results in the lowest validation error.
Advantages of KNNs
- KNNs are simple to implement and understand.
- None or very little training time required.
- It works fine with a multiclass dataset.
- KNNs are non-parametric, so it works fine with highly unusual data, as no assumption about the functional form is required.
Disadvantages of KNNs
- It has a computationally, expensive testing phase.
- KNN suffers from skewed class distribution. A more frequent class tends to dominate over the voting process.
- KNN also suffers from the curse of dimensionality.
I have tried to give a deep insight into the K-nearest neighbor algorithm.
I hope everything makes sense.
Thanks for reading!
References:
- CS231n Convolutional Neural Networks for Visual Recognition
- A Detailed Introduction to K-Nearest Neighbor (KNN) Algorithm
- A Complete Guide to K-Nearest-Neighbors with Applications in Python and R
Deep Insights Into K-nearest Neighbors was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

