


Demystifying the Black Box: Advanced Techniques in Interpretable AI with SHAP and LIME
Author(s): saeed garmsiri
Originally published on Towards AI.
Demystifying the Black Box: Advanced Techniques in Interpretable AI with SHAP and LIME
Hey ML Engs out there! Ever felt like you’ve created a brilliant machine learning model, only to realize you can’t quite explain how it’s making its decisions? Trust me, you’re not alone. As our AI babies grow more complex and powerful, they can sometimes feel like moody teenagers — making choices we just can’t understand. But fear not! Today, we’re diving into two super cool techniques that can help us decode those AI decisions: SHAP and LIME.
What’s the Big Deal?
Picture this: You’ve built an amazing model that can predict customer churn with uncanny accuracy. Your boss is thrilled, but then drops the bomb: “Great, but can you explain why it’s flagging Mrs. Johnson as a high-risk customer?” Gulp. This is where SHAP and LIME come to the rescue!
SHAP: The Sherlock Holmes of AI
SHAP (SHapley Additive exPlanations) is like the Sherlock Holmes of the AI world. It meticulously examines each feature of your model, determining how much each one contributes to the final prediction. It’s like having a magnifying glass that reveals the hidden clues in your AI’s decision-making process.
LIME: The Local Tour Guide
LIME (Local Interpretable Model-agnostic Explanations), on the other hand, is more like a friendly local tour guide. It focuses on explaining individual predictions by creating a simple, interpretable model around a specific data point. It’s perfect for those “Why did the model do that?” moments.
Why Should You Care?
Let’s face it — in today’s world, simply having a high-performing model isn’t enough. We need to be able to explain our AI’s decisions to everyone from curious customers to stern regulators. Plus, understanding our models better can help us spot biases, improve fairness, and build more trustworthy AI systems. So, are you ready to become an AI whisperer? Buckle up as we dive deep into the world of SHAP and LIME, exploring their inner workings and showing you how to implement them in your projects. Trust me, by the end of this journey, you’ll be explaining your AI’s decisions like a pro! ✌(ツ)
1. The Mystery of the Black Box
Let’s say you’ve got a super-smart AI friend who’s amazing at solving problems but can’t explain how they do it. Frustrating, right? That’s essentially what a black box model is in the AI world. These models are like magic trick masters — they pull off incredible feats, but won’t reveal their secrets. While they’re undoubtedly powerful, they come with a few headaches:
- The “Trust Me, Bro” Problem: Try telling your boss or a customer, “The AI said so, just trust it!” Yeah, not gonna fly.
- Hidden Biases: Like that friend who swears they’re not biased but always picks the same team to win, our AI might have some sneaky prejudices we can’t spot.
- Debugging Nightmares: When something goes wrong, it’s like trying to find a needle in a haystack… blindfolded.
- Easy Target for Tricksters: Without knowing how it thinks, we can’t protect our AI from those who might try to fool it.
- The Backseat Driver Dilemma: We want to help steer our AI, but it’s hard when we don’t know how it’s driving!
1.1. The Law’s Knocking: Time to Open Up!
But here’s the kicker — making our AI models more understandable isn’t just about making our lives easier. It’s becoming a legal must-do in many places. Take the European Union’s GDPR, for example. It’s basically saying, “If your AI makes a big decision about someone, you better be able to explain why!” It’s like when your parents used to say, “Because I said so” which isn’t a good enough reason anymore. We need to be able to show our work, just like in math class. So, buckle up! We’re about to embark on a journey to make our brilliant but mysterious AI models a bit more chatty. By the end of this, you’ll be able to get your AI to spill its secrets, making everyone — from your boss to the law — a whole lot happier!
2. Cracking the AI Code: Two Paths to Understanding
2.1. The “Open Book” Approach (aka Intrinsically Interpretable Models)
Remember those “show your work” math problems in school? Some AI models are like that — they’re designed to be easy to understand from the get-go. Think of them as the “open book” models:
- Linear regression: The straight-shooter of the AI world. It’s like explaining your decision based on a simple point system.
- Decision trees: Imagine a flowchart that an 8-year-old could follow. That’s a decision tree for you.
- Rule-based systems: These are like your grandma’s cookbook — “If this, then that” kind of instructions.
These models are great because they’re like that friend who always explains their reasoning. The downside? They sometimes struggle with complex tasks, like trying to use a recipe book to write a novel.
2.2. The “After-the-Fact Detective” Approach (aka Post-hoc Interpretation)
Now, what about those super-smart, complex models that do amazing things but can’t explain themselves? That’s where our detective skills come in. We use special techniques to figure out what these models are thinking after they’ve made their decisions. It’s like being a mind reader but for AI! This is where SHAP and LIME strut their stuff. They’re like universal translators for AI-speak, able to work with pretty much any model out there. Think of them as the Sherlock Holmes of the AI world — they investigate the clues and help us understand what our AI is thinking. By the end of this article, you’ll be equipped with these powerful tools, ready to demystify even the most complex AI decisions. Whether you’re dealing with a chatty “open book” model or a mysterious black box, you’ll be able to get to the bottom of their decision-making process. Let’s dive in and become AI whisperers!
Ok! It’s time to take it seriously and dive into theories ¯\_(ヅ)_/¯
3. SHAP: SHapley Additive exPlanations
3.1 Theoretical Foundation
SHAP is grounded in game theory, specifically Shapley values. In the context of model interpretation:
- The “game” is the prediction task
- The “players” are the individual features
- The “payout” is the difference between the actual prediction and the average prediction
The SHAP value for a feature represents its average marginal contribution to the prediction across all possible combinations of features.
The SHAP value for feature i is defined as:
Where:
- F is the set of all features
- S is a subset of features not including i
- fx(S) is the prediction made by the model using only the features in S
3.2 Key Concepts
- Additivity: SHAP values sum to the difference between the prediction and the average prediction
- Consistency: If a feature’s contribution increases or stays the same regardless of other features, its SHAP value will increase or stay the same
- Local Accuracy: For each prediction, the sum of SHAP values plus the base value equals the model output
3.3 Implementing SHAP Let’s implement SHAP for a loan approval model:
Before running this code make sure to install the following libraries in your code environment.
pip install shap
pip install lime
pip install xgboost
pip install --upgrade anchor-exp
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
import shap
import matplotlib.pyplot as plt
# Generate synthetic loan data
np.random.seed(42)
n_samples = 1000
data = pd.DataFrame({
'Annual_Income': np.random.normal(60000, 15000, n_samples),
'Credit_Score': np.random.normal(700, 50, n_samples),
'Years_of_Employment': np.random.normal(5, 2, n_samples),
'Debt_to_Income_Ratio': np.random.normal(0.3, 0.1, n_samples),
'Loan_Amount': np.random.normal(200000, 50000, n_samples)
})
data['Loan_Approved'] = (
(data['Credit_Score'] > 680) &
(data['Debt_to_Income_Ratio'] < 0.4) &
(data['Annual_Income'] > 50000)
).astype(int)
# Prepare data for modeling
X = data.drop('Loan_Approved', axis=1)
y = data['Loan_Approved']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train XGBoost model
model = xgb.XGBClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# SHAP explanation
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# Set up figure size and style
plt.figure(figsize=(12, 8))
plt.style.use('seaborn')
# SHAP summary plot
shap.summary_plot(shap_values, X_test, plot_type="bar", show=False)
plt.title('SHAP Feature Importance', fontsize=16)
plt.xlabel('SHAP Value', fontsize=12)
plt.ylabel('Features', fontsize=12)
plt.tight_layout()
plt.savefig('loan_shap_summary.png', dpi=300, bbox_inches='tight')
plt.close()
# SHAP force plot for a specific application
plt.figure(figsize=(16, 6))
specific_application = X_test.iloc[0:1]
shap.force_plot(explainer.expected_value, shap_values[0], specific_application, matplotlib=True, show=False)
plt.title('SHAP Force Plot for Specific Application', fontsize=16)
plt.tight_layout()
plt.savefig('loan_shap_force_plot.png', dpi=300, bbox_inches='tight')
plt.close()
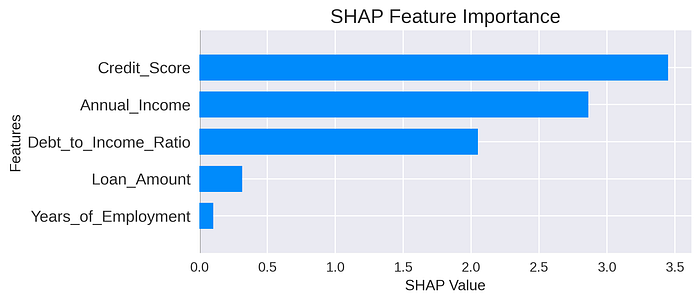
The summary plot (Figure 1) shows the importance of global features. Features are ranked by their average absolute SHAP value, indicating positive or negative impact on the prediction.

The force plot (Figure 2) provides a local explanation for a single prediction, illustrating how each feature pushes the prediction higher (red) or lower (blue) from the base value.
3.4 Advanced SHAP Techniques
SHAP offers additional advanced techniques:
a) SHAP Interaction Values:
SHAP Interaction Values provide a way to measure and visualize how features in the model interact with each other when making predictions.
# SHAP interaction values plot
shap_interaction_values = explainer.shap_interaction_values(X_test)
plt.figure(figsize=(14, 10))
shap.summary_plot(shap_interaction_values, X_test, plot_type="compact_dot", show=False)
plt.title('SHAP Interaction Values', fontsize=12)
plt.xlabel('SHAP Interaction Value', fontsize=5)
plt.ylabel('Features', fontsize=12)
plt.tight_layout()
plt.savefig('loan_shap_interaction_values.png', dpi=300, bbox_inches='tight')
plt.close()
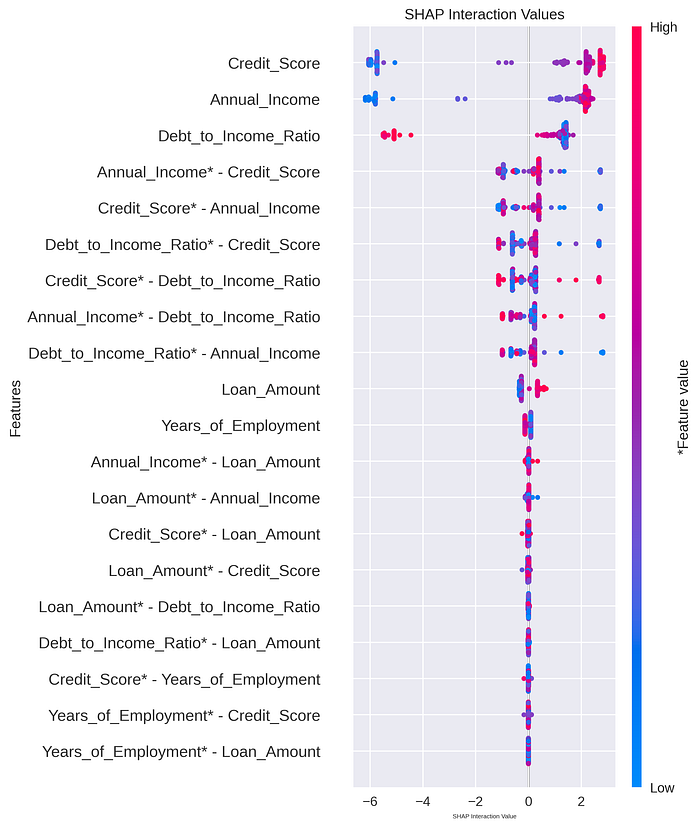
b) Dependence Plots:
shap.dependence_plot("Credit_Score", shap_values, X_test)
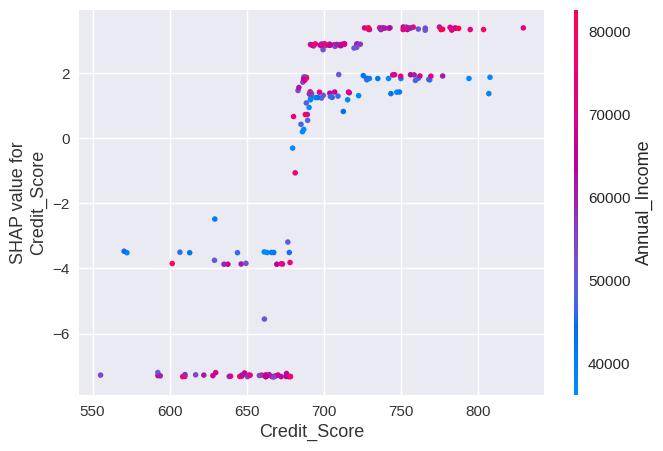
The above plot consists of the following factors:
- X-axis: Shows the actual values of the “Credit_Score” feature
- Y-axis: Shows the SHAP values for “Credit_Score”
- Each point represents an instance from X_test
- The color of each point typically represents the value of another feature that interacts strongly with “Credit_Score”
4. LIME: Local Interpretable Model-agnostic Explanations
4.1 Theoretical Foundation
LIME creates local, interpretable surrogate models by perturbing the input data and observing changes in predictions. It fits a simple model (e.g., linear regression) to this local area around the prediction.
Mathematical Formulation: LIME finds an interpretable model g in the interpretable model family G that minimizes:
Where:
- f is the original complex model
- πx is a proximity measure around instance x
- L is a loss function (e.g., mean squared error)
- Ω(g) is a measure of explanation complexity
4.2 Key Concepts
- Local Fidelity: The explanation accurately represents the model near the instance being explained
- Interpretability: The explanation is simple enough for human understanding
- Model-Agnostic: LIME can explain any black box model
4.3 Implementing LIME Let’s apply LIME to our loan approval model:
import lime
import lime.lime_tabular
# LIME explainer
explainer = lime.lime_tabular.LimeTabularExplainer(
X_train.values,
feature_names=X.columns,
class_names=['Denied', 'Approved'],
mode="classification"
)
# Generate LIME explanation for a specific application
specific_application = X_test.iloc[0]
exp = explainer.explain_instance(specific_application, model.predict_proba, num_features=5)
# LIME plot
exp.as_pyplot_figure()
plt.tight_layout()
plt.savefig('loan_lime_explanation.png')
plt.close()

The LIME plot (Figure 5) shows local feature importance for a single prediction, ranking features by their importance in the local area and demonstrating how changes affect the prediction.
4.4 Advanced LIME Techniques
a) Anchor Explanations:
Anchor is an extension of LIME that provides high-precision rules to explain individual predictions. While LIME offers local linear approximations, Anchor generates if-then rules that “anchor” a prediction with high precision.
Anchor explanations are based on the concept of “anchors” — rules that are sufficient to make a prediction. An anchor rule is a set of feature-value pairs that, when present, almost always result in the same prediction regardless of the values of other features.
An anchor A is defined as a rule that maximizes:
Where:
- E[·] denotes the expected value
- P(·) is the probability
- f(x) is the model’s prediction for instance x
- z represents instances sampled from the distribution D
- A(z) = 1 indicates that z satisfies the anchor rule A
- τ is a user-defined precision threshold
In simpler terms, this formula states that the expected probability of the model making the same prediction for instances that satisfy the anchor rule should be at least τ.
Also, these are Anchor’s key factors:
Precision: Anchor rules aim for high precision, meaning they should be correct for a large proportion of instances where they apply.
Coverage: The proportion of instances where the anchor rule applies.
Stability: Anchor explanations are deterministic, unlike LIME’s random sampling approach. Let’s implement Anchor for our loan approval model:
from anchor import anchor_tabular
explainer = anchor_tabular.AnchorTabularExplainer(
class_names=['Denied', 'Approved'],
feature_names=X.columns,
train_data=X_train.values
)
exp = explainer.explain_instance(X_test.iloc[0].values, model.predict, threshold=0.95)
print(exp.names())
[
'Credit_Score > 704.45',
'Annual_Income > 50236.77',
'Debt_to_Income_Ratio <= 0.23'
]
b) LIME for Text and Images:
LIME can also be extended to other data types and techniques. For example, It can explain predictions for text and image data, making it versatile across various ML domains. Here is a simple text example:
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from lime.lime_text import LimeTextExplainer
# Sample dataset
texts = [
"I love this movie, it's amazing",
"This film is terrible, I hated it",
"Great acting and plot, highly recommended",
"Boring story, waste of time",
"Excellent cinematography and direction"
]
labels = [1, 0, 1, 0, 1] # 1 for positive, 0 for negative
# Create and train a simple text classifier
classifier = make_pipeline(CountVectorizer(), MultinomialNB())
classifier.fit(texts, labels)
# Create LIME explainer
explainer = LimeTextExplainer(class_names=['negative', 'positive'])
# Text to explain
new_text = "The movie was good, but a bit long"
exp = explainer.explain_instance(new_text, classifier.predict_proba, num_features=6)
print("Prediction:", "positive" if classifier.predict([new_text])[0] == 1 else "negative")
print("\nExplanation:")
for feature, score in exp.as_list():
print(f"{feature}: {score}")
exp.as_pyplot_figure()
import matplotlib.pyplot as plt
plt.tight_layout()
plt.show()
Prediction: positive
Explanation:
movie: 0.1283088566345527
a: 1.5125823711000755e-05
was: 8.881837633946205e-06
good: 8.619394187488467e-06
The: 2.3504017921364224e-06
but: 8.591569445314599e-07
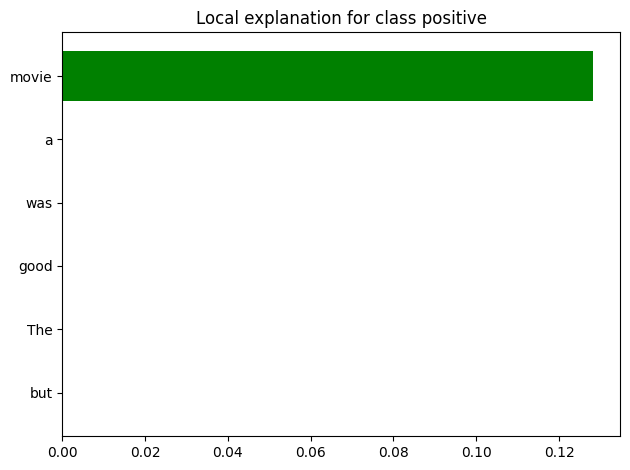
This code demonstrates how LIME can be used to explain text classifications. It shows which words in the input text had the most influence on the model’s prediction, either positively or negatively. This example showcases LIME’s versatility in explaining predictions across different types of data, making it a valuable tool for interpreting various machine-learning models.
5. Comparative Analysis: SHAP vs. LIME
5.1 Consistency and Scope
- SHAP: Provides consistent global and local interpretations
- LIME: Focuses on local explanations, which can vary due to random sampling
5.2 Computational Efficiency
- SHAP: Can be computationally expensive, especially for large datasets
- LIME: Generally faster for individual explanations
5.3 Theoretical Guarantees
- SHAP: Based on solid game-theoretic principles
- LIME: Less rigorous theoretical foundation, but offers an intuitive approach
5.4 Use Cases and Limitations
- SHAP: Ideal for comprehensive model understanding and feature importance analysis
- LIME: Excellent for quick, intuitive explanations of individual predictions
6. Best Practices for Interpretable AI
6.1 Selecting the Appropriate Tool
Choose SHAP for in-depth model analysis and LIME for rapid, instance-specific explanations.
6.2 Combining Multiple Approaches
Use both global (SHAP) and local (LIME) explanations for a comprehensive understanding.
6.3 Validating Explanations
Cross-check SHAP and LIME explanations for consistency and verify with domain experts.
6.4 Iterative Model Refinement
Use insights from explanations to improve your model and feature engineering.
6.5 Effective Communication of Results
Tailor explanations to your audience and leverage visualizations for intuitive understanding.
7. Explaining the Hypothetical Credit Risk Assessment Case Study
A major bank implemented SHAP and LIME to explain their credit risk model. By using SHAP, they identified that the debt-to-income ratio had a disproportionate impact on loan rejections for certain demographics. LIME explanations helped customer service representatives provide clear, instance-specific reasons for loan decisions. This improved transparency led to increased customer satisfaction and helped the bank refine their model to be more equitable.
8. Ethical Considerations in Interpretable AI
As we delve deeper into interpretable AI techniques like SHAP and LIME, it’s crucial to consider the ethical implications of these methods, especially in sensitive domains like credit risk assessment.
8.1 Fairness and Bias Detection
Interpretable AI techniques can play a pivotal role in identifying and mitigating bias in machine learning models. In our credit risk assessment case study, SHAP analysis revealed that the debt-to-income ratio had a disproportionate impact on loan rejections for certain demographics. This insight is crucial for ensuring fair lending practices.
- Use SHAP and LIME to regularly audit your models for potential biases
- Pay special attention to protected attributes and their interactions with other features
- Consider using fairness-aware machine learning techniques in conjunction with interpretability methods
8.2 Transparency and Accountability
The use of SHAP and LIME in our case study improved transparency, allowing customer service representatives to provide clear, instance-specific reasons for loan decisions. This level of transparency is essential for building trust with customers and complying with regulations like GDPR’s “right to explanation.”
- Develop clear protocols for explaining model decisions to stakeholders, including customers and regulators
- Train your team to effectively communicate model insights derived from SHAP and LIME
- Document the interpretability process and results for audit purposes
8.3 Privacy Considerations
While striving for interpretability, it’s important to balance this with privacy concerns. Detailed explanations might inadvertently reveal sensitive information about the model or the training data.
- Ensure that individual privacy is protected when providing explanations
- Be cautious about the level of detail in public-facing explanations
- Consider using differential privacy techniques when necessary
8.4 Responsible AI Development
Interpretable AI is a key component of responsible AI development. By understanding how our models make decisions, we can ensure they align with ethical principles and societal values.
- Use insights from SHAP and LIME to iteratively improve your models, not just for performance but also for ethical considerations
- Establish an ethics review process for AI models, especially those used in high-stakes decisions like loan approvals
- Stay informed about evolving ethical guidelines and regulations in AI
8.5 Limitations and Potential Misuse
While SHAP and LIME are powerful tools, they are not panaceas for ethical AI. Be aware of their limitations:
- These methods provide insights into the model’s behavior but don’t inherently make the model more ethical
- There’s a risk of over-relying on these explanations or using them to justify potentially problematic decisions
- The interpretations themselves can be complex and potentially misunderstood or misused
Conclusion
Shining a Light on AI’s Black Box: Why SHAP and LIME Matter
Hey there, AI enthusiasts! Let’s chat about something that’s been buzzing in the tech world lately — making our smart AI models a little less mysterious. You know how sometimes our AI can be like that friend who’s brilliant but can’t explain how they solve problems? Well, SHAP and LIME are here to change that game!
Why Should We Care?
Imagine you’ve built an AI that’s amazing at predicting stock prices. Your boss is thrilled, but then asks, “So, why is it saying we should invest in this particular company?” Gulp. That’s where SHAP and LIME come to the rescue! These aren’t just fancy acronyms — they’re like X-ray glasses for our AI models. They help us peek inside and understand why our AI is making certain decisions. This is huge, especially in areas like healthcare or finance, where we can’t just say, “The computer said so!”
SHAP and LIME: The Dynamic Duo
SHAP is like that friend who’s great at breaking down complex group projects. It looks at how each feature in your model contributes to the final decision.LIME, on the other hand, is more like a local tour guide. It focuses on explaining individual predictions by creating a simple model around a specific data point. Together, they’re like the Sherlock and Watson of the AI world, helping us solve the mystery of our model’s decision-making process.
Why It’s More Than Just Cool Tech
- Building Trust: When we can explain how our AI works, people are more likely to trust and use it.
- Spotting Biases: These tools help us catch if our AI is being unfair without us realizing it.
- Staying Legal: With new laws popping up about AI transparency, SHAP and LIME help us stay on the right side of regulations.
- Improving Our Models: Understanding our AI better means we can make it even smarter and more reliable.
The Bigger Picture
By using SHAP and LIME, we’re not just making our models more understandable — we’re shaping the future of AI. We’re moving towards a world where AI isn’t just powerful, but also trustworthy and fair.
What’s Next?
The world of interpretable AI is always evolving. New techniques are popping up all the time, promising even better ways to understand our AI. As AI developers, it’s our job to keep learning and adapting, always striving to make our AI not just smarter, but more transparent and ethical.
Wrapping Up
So, next time you’re working on an AI project, remember SHAP and LIME. They’re not just tools — they’re your partners in creating AI that’s not only brilliant but also explainable and trustworthy. Let’s build AI that doesn’t just impress with its smarts but also with its clarity and fairness! Keep coding, keep explaining, and let’s make AI that everyone can understand and trust!
Resources for Further Learning
- “Interpretable Machine Learning” by Christoph Molnar
- SHAP GitHub repository: https://github.com/slundberg/shap
- LIME GitHub repository: https://github.com/marcotcr/lime
- “A Unified Approach to Interpreting Model Predictions” (SHAP paper): https://arxiv.org/abs/1705.07874
- “Why Should I Trust You?: Explaining the Predictions of Any Classifier” (LIME paper): https://arxiv.org/abs/1602.04938
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")