



Pandas vs Polars? Bid Adieu to Pandas and Switch To Polars!
Last Updated on April 22, 2024 by Editorial Team
Author(s): Saankhya Mondal
Originally published on Towards AI.
Dealing with tabular data? Pandas is the first Python library you’ll come across when dealing with tabular data preprocessing. It’s one of the most popular libraries used in Data Science. Pandas is the go-to framework for working with small or medium-sized CSV files. However, as the size of the dataset keeps increasing, Pandas’ performance starts deteriorating. The main disadvantage of Pandas is that it uses only a single thread (hence, only one CPU core) to perform operations and requires you to store the entire data frame in memory. Therefore, Pandas is slow.
Enter Polars. Polars is designed for parallelism as it can utilize all the available cores in the CPU to perform data processing. Hence, it’s blazing fast. It optimizes queries to reduce unneeded work/memory allocations and can handle datasets much larger than the available RAM. Polars is written in Rust which gives it C/C++ performance and allows it to fully control the critical parts in a query engine.
One can seamlessly integrate Polars into their development code as Polars is easy to use and has a similar API as Pandas and Pyspark. It supports most commonly used file types like .csv and .parquet and databases like MySQL and Postgres.
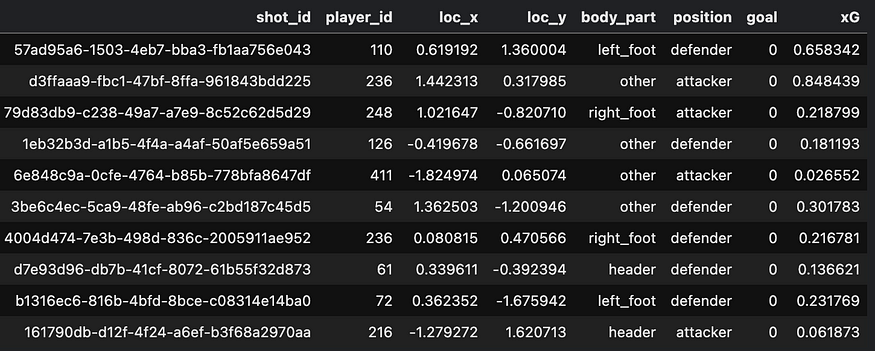
Let’s see how faster Polars is. For comparing the two libraries, I’ve created a dummy dataset containing 1 million rows. Each row represents a shot taken by a football player, the attributes of the shot, and whether it resulted in a goal or not. The size of the dataset is 1.2 GB.
Dataset Creation
import pandas as pd
import numpy as np
import tqdm
import uuid
data = []
body_part = ["right_foot", "left_foot", "header", "other"]
position = ["attacker", "midfielder", "defender"]
for i in tqdm.tqdm(range(10000000)):
data.append({
"shot_id" : str(uuid.uuid4()),
"player_id" : np.random.randint(500),
"loc_x" : np.random.randn(),
"loc_y" : np.random.randn(),
"body_part" : body_part[np.random.randint(4)],
"position" : position[np.random.randint(3)],
"goal" : np.random.binomial(1, 0.11),
"xG" : np.random.uniform(0, 1)
})
data = pd.DataFrame(data)
data.to_csv("data.csv", index=None)
Pandas vs Polars — Read .csv file
The code to read a .csv file has been shown in the code snippet below.
# Pandas
df_pd = pd.read_csv("data.csv")
# Polars
df_pl = pl.read_csv("data.csv")
The execution times are averaged over 10 runs. Polars is 8.93 times faster while reading a 1.2GB .csv file containing 1 million rows!

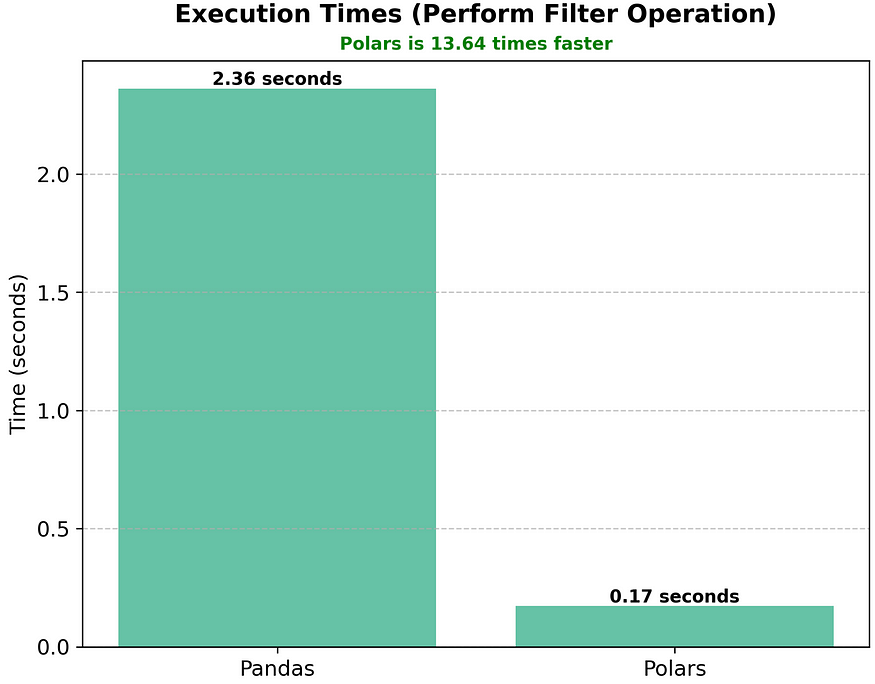
Pandas vs Polars — Perform Filter operation
Suppose we want to deal with the players who are attackers. We perform filter operation.
# Pandas
df_pd_filter = df_pd[df_pd["position"] == "attacker"]
# Polars
df_pl_filter = df_pl.filter(pl.col("position") == "attacker")
Polars is 13.64 times faster than Pandas while performing filtering operation!
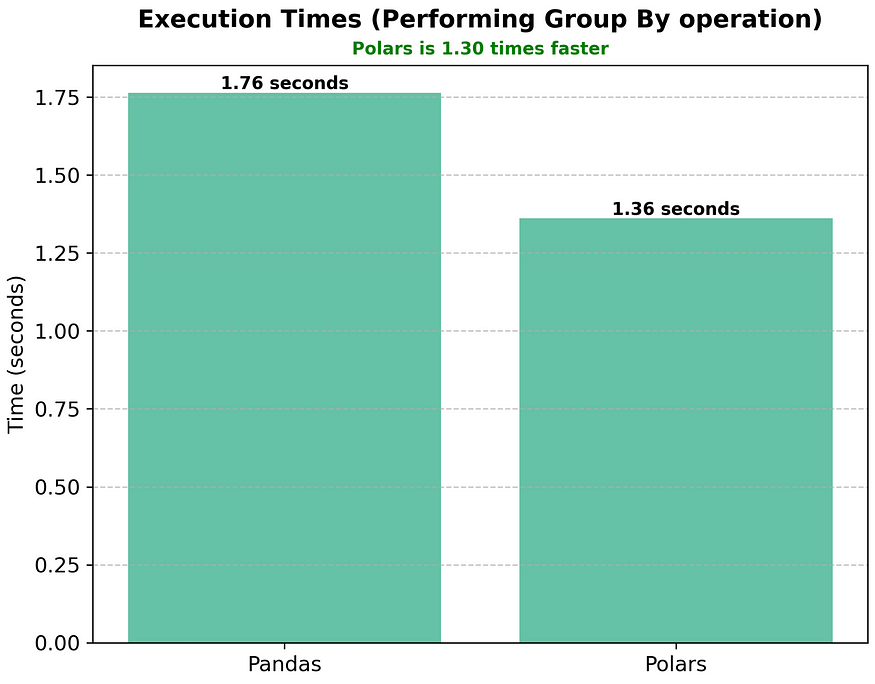
Pandas vs Polars — Perform Group By operation
Suppose we want to see the total number of goals scored by each player from each body part and want the results to be in a clean and sorted order. The following code block does the same.
# Pandas
df_agg_pd = (df_pd
.groupby([
df_pd["player_id"],
df_pd["body_part"]
]
)
.agg(
total_goals = ("goal", "sum"),
total_xG = ("xG", "sum")
)
.reset_index()
.sort_values(
by=["total_goals", "total_xG", "player_id", "body_part"],
ascending=[False, False, True, True]
)
)
# Polars
df_agg_pl = (df_pl
.group_by(
[
pl.col("player_id"),
pl.col("body_part")
]
)
.agg(
pl.sum("goal").alias("total_goals"),
pl.sum("xG").alias("total_xG")
)
.sort(
by=["total_goals", "total_xG", "player_id", "body_part"],
descending=[True, True, False, False]
)
)
The execution times are averaged over 10 runs. Polars is 1.3 times faster here.
Pandas vs Polars — The entire pipeline
As a Data Scientist, I would want my entire pipeline to execute quickly so that I can start training my favorite machine learning model on the dataset. Here comes the interesting part. Polars comes with a lazy API and a dataframe type called LazyFrame! Using the lazy API, Polars doesn’t execute each query line by line; instead, it processes the entire query from start to finish. The lazy API enables automatic query optimization through the query optimizer. Let’s compare three techniques.
# Pandas
df_pd = pd.read_csv("data.csv")
df_pd = df_pd[df_pd["position"] == "attacker"]
df_agg_pd = (
df_pd
.groupby([
df_pd["player_id"],
df_pd["body_part"]
]
)
.agg(
total_goals = ("goal", "sum"),
total_xG = ("xG", "sum")
)
.reset_index()
.sort_values(
by=["total_goals", "total_xG", "player_id", "body_part"],
ascending=[False, False, True, True]
)
)
# Polars
df_agg_pl = (
pl.read_csv("data.csv")
.filter(pl.col("position") == "attacker")
.group_by(
[
pl.col("player_id"),
pl.col("body_part")
]
)
.agg(
pl.sum("goal").alias("total_goals"),
pl.sum("xG").alias("total_xG")
)
.sort(
by=["total_goals", "total_xG", "player_id", "body_part"],
descending=[True, True, False, False]
)
)
# Polars (Lazy)
df_agg_pl = (
pl.scan_csv("data.csv")
.filter(pl.col("position") == "attacker")
.group_by(
[
pl.col("player_id"),
pl.col("body_part")
]
)
.agg(
pl.sum("goal").alias("total_goals"),
pl.sum("xG").alias("total_xG")
)
.sort(
by=["total_goals", "total_xG", "player_id", "body_part"],
descending=[True, True, False, False]
)
)
df_agg_pl = df_agg_pl.collect()
Note that Polars lazy API uses scan_csv instead of read_csv to create a query computation graph. Data processing takes place only when we call collect(). Polars lazy API is 13.24 times faster than Pandas. It is over 1.5 times faster than Polars! Incredible, isn’t it?

Polars support interaction with SQL! The following code snippet shows a simple example.
ctx = pl.SQLContext(population=df_pl, eager_execution=True)
query = """
select player_id, body_part, sum(goal) as total_goals, sum(xG) as total_xG
from population
group by player_id, body_part
order by total_goals desc, total_xG desc, player_id, body_part
"""
print(ctx.execute(query))

Conclusion
Polars is blazing fast, thanks to its multi-threading capability! You can take it up a notch When you want to run your entire pipeline, right from reading you data file and performing data processing operations, you can speed up your pipeline 13 times by using lazy Polars!
For more info, refer documentation — https://docs.pola.rs/.
Code for the analysis and plots can be found here — https://github.com/sm823zw/pandas-vs-polars
Thank you for reading!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



